


寫在前面
Max Grigorev最近寫了一篇文章,題目是《What every software engineer should know about search》,這篇文章里指出了現(xiàn)在一些軟件工程師的問(wèn)題,他們認(rèn)為開(kāi)發(fā)一個(gè)搜索引擎功能就是搭建一個(gè)ElasticSearch集群,而沒(méi)有深究背后的技術(shù),以及技術(shù)發(fā)展趨勢(shì)。Max認(rèn)為,除了搜索引擎自身的搜索問(wèn)題解決、人類使用方式等之外,也需要解決索引、分詞、權(quán)限控制、國(guó)際化等等的技術(shù)點(diǎn),看了他的文章,勾起了我多年前的想法。
很多年前,我曾經(jīng)想過(guò)自己實(shí)現(xiàn)一個(gè)搜索引擎,作為自己的研究生論文課題,后來(lái)琢磨半天沒(méi)有想出新的技術(shù)突破點(diǎn)(相較于已發(fā)表的文章),所以切換到了大數(shù)據(jù)相關(guān)的技術(shù)點(diǎn)。當(dāng)時(shí)沒(méi)有寫出來(lái),心中有點(diǎn)小遺憾,畢竟憑借搜索引擎崛起的谷歌是我內(nèi)心渴望的公司。今天我就想結(jié)合自己的一些積累,聊聊作為一名軟件工程師,您需要了解的搜索引擎知識(shí)。
搜索引擎發(fā)展過(guò)程
現(xiàn)代意義上的搜索引擎的祖先,是1990年由蒙特利爾大學(xué)學(xué)生Alan Emtage發(fā)明的Archie。即便沒(méi)有英特網(wǎng),網(wǎng)絡(luò)中文件傳輸還是相當(dāng)頻繁的,而且由于大量的文件散布在各個(gè)分散的FTP主機(jī)中,查詢起來(lái)非常不便,因此Alan Emtage想到了開(kāi)發(fā)一個(gè)可以以文件名查找文件的系統(tǒng),于是便有了Archie。Archie工作原理與現(xiàn)在的搜索引擎已經(jīng)很接近,它依靠腳本程序自動(dòng)搜索網(wǎng)上的文件,然后對(duì)有關(guān)信息進(jìn)行索引,供使用者以一定的表達(dá)式查詢。
互聯(lián)網(wǎng)興起后,需要能夠監(jiān)控的工具。世界上第一個(gè)用于監(jiān)測(cè)互聯(lián)網(wǎng)發(fā)展規(guī)模的“機(jī)器人”程序是Matthew Gray開(kāi)發(fā)的World wide Web Wanderer,剛開(kāi)始它只用來(lái)統(tǒng)計(jì)互聯(lián)網(wǎng)上的服務(wù)器數(shù)量,后來(lái)則發(fā)展為能夠檢索網(wǎng)站域名。
隨著互聯(lián)網(wǎng)的迅速發(fā)展,每天都會(huì)新增大量的網(wǎng)站、網(wǎng)頁(yè),檢索所有新出現(xiàn)的網(wǎng)頁(yè)變得越來(lái)越困難,因此,在Matthew Gray的Wanderer基礎(chǔ)上,一些編程者將傳統(tǒng)的“蜘蛛”程序工作原理作了些改進(jìn)。現(xiàn)代搜索引擎都是以此為基礎(chǔ)發(fā)展的。
搜索引擎分類
全文搜索引擎當(dāng)前主流的是全文搜索引擎,較為典型的代表是Google、百度。全文搜索引擎是指通過(guò)從互聯(lián)網(wǎng)上提取的各個(gè)網(wǎng)站的信息(以網(wǎng)頁(yè)文字為主),保存在自己建立的數(shù)據(jù)庫(kù)中。用戶發(fā)起檢索請(qǐng)求后,系統(tǒng)檢索與用戶查詢條件匹配的相關(guān)記錄,然后按一定的排列順序?qū)⒔Y(jié)果返回給用戶。從搜索結(jié)果來(lái)源的角度,全文搜索引擎又可細(xì)分為兩種,一種是擁有自己的檢索程序(Indexer),俗稱“蜘蛛”(Spider)程序或“機(jī)器人”(Robot)程序,并自建網(wǎng)頁(yè)數(shù)據(jù)庫(kù),搜索結(jié)果直接從自身的數(shù)據(jù)存儲(chǔ)層中調(diào)用;另一種則是租用其他引擎的數(shù)據(jù)庫(kù),并按自定的格式排列搜索結(jié)果,如Lycos引擎。
目錄索引類搜索引擎雖然有搜索功能,但嚴(yán)格意義上不能稱為真正的搜索引擎,只是按目錄分類的網(wǎng)站鏈接列表而已。用戶完全可以按照分類目錄找到所需要的信息,不依靠關(guān)鍵詞(Keywords)進(jìn)行查詢。目錄索引中最具代表性的莫過(guò)于大名鼎鼎的Yahoo、新浪分類目錄搜索。
元搜索引擎
元搜索引擎在接受用戶查詢請(qǐng)求時(shí),同時(shí)在其他多個(gè)引擎上進(jìn)行搜索,并將結(jié)果返回給用戶。著名的元搜索引擎有InfoSpace、Dogpile、Vivisimo等,中文元搜索引擎中具代表性的有搜星搜索引擎。在搜索結(jié)果排列方面,有的直接按來(lái)源引擎排列搜索結(jié)果,如Dogpile,有的則按自定的規(guī)則將結(jié)果重新排列組合,如Vivisimo。
相關(guān)實(shí)現(xiàn)技術(shù)
搜索引擎產(chǎn)品雖然一般都只有一個(gè)輸入框,但是對(duì)于所提供的服務(wù),背后有很多不同業(yè)務(wù)引擎支撐,每個(gè)業(yè)務(wù)引擎又有很多不同的策略,每個(gè)策略又有很多模塊協(xié)同處理,及其復(fù)雜。
搜索引擎本身包含網(wǎng)頁(yè)抓取、網(wǎng)頁(yè)評(píng)價(jià)、反作弊、建庫(kù)、倒排索引、索引壓縮、在線檢索、ranking排序策略等等知識(shí)。
網(wǎng)絡(luò)爬蟲技術(shù)網(wǎng)絡(luò)爬蟲技術(shù)指的是針對(duì)網(wǎng)絡(luò)數(shù)據(jù)的抓取。因?yàn)樵诰W(wǎng)絡(luò)中抓取數(shù)據(jù)是具有關(guān)聯(lián)性的抓取,它就像是一只蜘蛛一樣在互聯(lián)網(wǎng)中爬來(lái)爬去,所以我們很形象地將其稱為是網(wǎng)絡(luò)爬蟲技術(shù)。網(wǎng)絡(luò)爬蟲也被稱為是網(wǎng)絡(luò)機(jī)器人或者是網(wǎng)絡(luò)追逐者。
網(wǎng)絡(luò)爬蟲獲取網(wǎng)頁(yè)信息的方式和我們平時(shí)使用瀏覽器訪問(wèn)網(wǎng)頁(yè)的工作原理是完全一樣的,都是根據(jù)HTTP協(xié)議來(lái)獲取,其流程主要包括如下步驟:
1)連接DNS域名服務(wù)器,將待抓取的URL進(jìn)行域名解析(URL------>IP);
2)根據(jù)HTTP協(xié)議,發(fā)送HTTP請(qǐng)求來(lái)獲取網(wǎng)頁(yè)內(nèi)容。
一個(gè)完整的網(wǎng)絡(luò)爬蟲基礎(chǔ)框架如下圖所示:
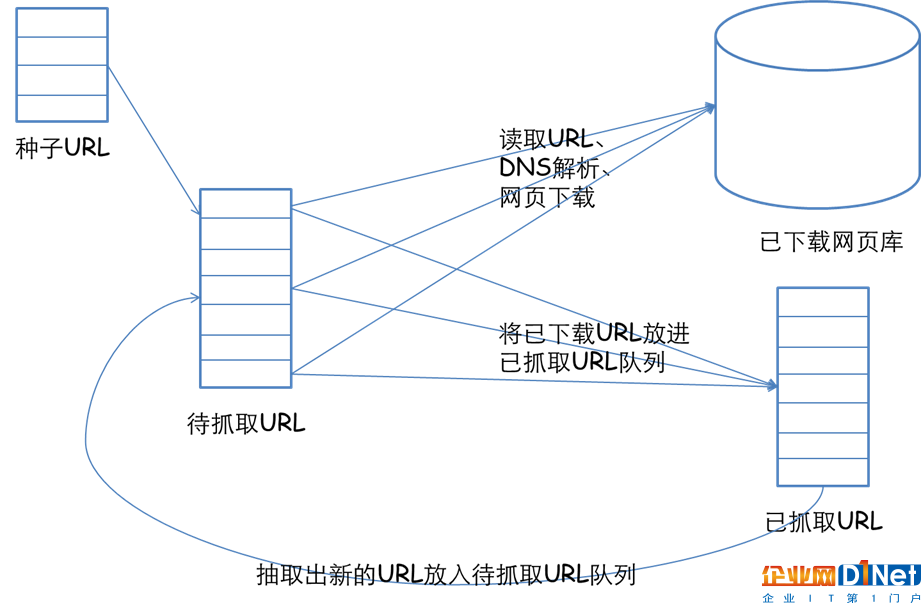
整個(gè)架構(gòu)共有如下幾個(gè)過(guò)程:
1)需求方提供需要抓取的種子URL列表,根據(jù)提供的URL列表和相應(yīng)的優(yōu)先級(jí),建立待抓取URL隊(duì)列(先來(lái)先抓);
2)根據(jù)待抓取URL隊(duì)列的排序進(jìn)行網(wǎng)頁(yè)抓取;
3)將獲取的網(wǎng)頁(yè)內(nèi)容和信息下載到本地的網(wǎng)頁(yè)庫(kù),并建立已抓取URL列表(用于去重和判斷抓取的進(jìn)程);
4)將已抓取的網(wǎng)頁(yè)放入到待抓取的URL隊(duì)列中,進(jìn)行循環(huán)抓取操作;
- 索引
從用戶的角度來(lái)看,搜索的過(guò)程是通過(guò)關(guān)鍵字在某種資源中尋找特定的內(nèi)容的過(guò)程。而從計(jì)算機(jī)的角度來(lái)看,實(shí)現(xiàn)這個(gè)過(guò)程可以有兩種辦法。一是對(duì)所有資源逐個(gè)與關(guān)鍵字匹配,返回所有滿足匹配的內(nèi)容;二是如同字典一樣事先建立一個(gè)對(duì)應(yīng)表,把關(guān)鍵字與資源的內(nèi)容對(duì)應(yīng)起來(lái),搜索時(shí)直接查找這個(gè)表即可。顯而易見(jiàn),第二個(gè)辦法效率要高得多。建立這個(gè)對(duì)應(yīng)表事實(shí)上就是建立逆向索引(inverted index)的過(guò)程。
LuceneLucene是一個(gè)高性能的java全文檢索工具包,它使用的是倒排文件索引結(jié)構(gòu)。
全文檢索大體分兩個(gè)過(guò)程,索引創(chuàng)建 (Indexing) 和搜索索引 (Search) 。
索引創(chuàng)建:將現(xiàn)實(shí)世界中所有的結(jié)構(gòu)化和非結(jié)構(gòu)化數(shù)據(jù)提取信息,創(chuàng)建索引的過(guò)程。
搜索索引:就是得到用戶的查詢請(qǐng)求,搜索創(chuàng)建的索引,然后返回結(jié)果的過(guò)程。
非結(jié)構(gòu)化數(shù)據(jù)中所存儲(chǔ)的信息是每個(gè)文件包含哪些字符串,也即已知文件,欲求字符串相對(duì)容易,也即是從文件到字符串的映射。而我們想搜索的信息是哪些文件包含此字符串,也即已知字符串,欲求文件,也即從字符串到文件的映射。兩者恰恰相反。于是如果索引總能夠保存從字符串到文件的映射,則會(huì)大大提高搜索速度。
由于從字符串到文件的映射是文件到字符串映射的反向過(guò)程,于是保存這種信息的索引稱為反向索引 。
反向索引的所保存的信息一般如下:
假設(shè)我的文檔集合里面有100篇文檔,為了方便表示,我們?yōu)槲臋n編號(hào)從1到100,得到下面的結(jié)構(gòu)
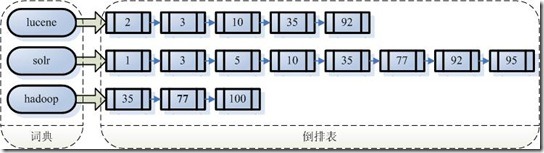
每個(gè)字符串都指向包含此字符串的文檔(Document)鏈表,此文檔鏈表稱為倒排表 (Posting List)。
ElasticSearchElasticsearch是一個(gè)實(shí)時(shí)的分布式搜索和分析引擎,可以用于全文搜索,結(jié)構(gòu)化搜索以及分析,當(dāng)然你也可以將這三者進(jìn)行組合。Elasticsearch是一個(gè)建立在全文搜索引擎 Apache Lucene 基礎(chǔ)上的搜索引擎,但是Lucene只是一個(gè)框架,要充分利用它的功能,需要使用JAVA,并且在程序中集成Lucene。Elasticsearch使用Lucene作為內(nèi)部引擎,但是在使用它做全文搜索時(shí),只需要使用統(tǒng)一開(kāi)發(fā)好的API即可,而不需要了解其背后復(fù)雜的Lucene的運(yùn)行原理。
SolrSolr是一個(gè)基于Lucene的搜索引擎服務(wù)器。Solr 提供了層面搜索、命中醒目顯示并且支持多種輸出格式(包括 XML/XSLT 和 JSON 格式)。它易于安裝和配置,而且附帶了一個(gè)基于 HTTP 的管理界面。Solr已經(jīng)在眾多大型的網(wǎng)站中使用,較為成熟和穩(wěn)定。Solr 包裝并擴(kuò)展了 Lucene,所以Solr的基本上沿用了Lucene的相關(guān)術(shù)語(yǔ)。更重要的是,Solr 創(chuàng)建的索引與 Lucene 搜索引擎庫(kù)完全兼容。通過(guò)對(duì)Solr 進(jìn)行適當(dāng)?shù)呐渲茫承┣闆r下可能需要進(jìn)行編碼,Solr 可以閱讀和使用構(gòu)建到其他 Lucene 應(yīng)用程序中的索引。此外,很多 Lucene 工具(如Nutch、 Luke)也可以使用Solr 創(chuàng)建的索引。
Hadoop谷歌公司發(fā)布的一系列技術(shù)白皮書導(dǎo)致了Hadoop的誕生。Hadoop是一系列大數(shù)據(jù)處理工具,可以被用在大規(guī)模集群里。Hadoop目前已經(jīng)發(fā)展為一個(gè)生態(tài)體系,包括了很多組件,如圖所示。
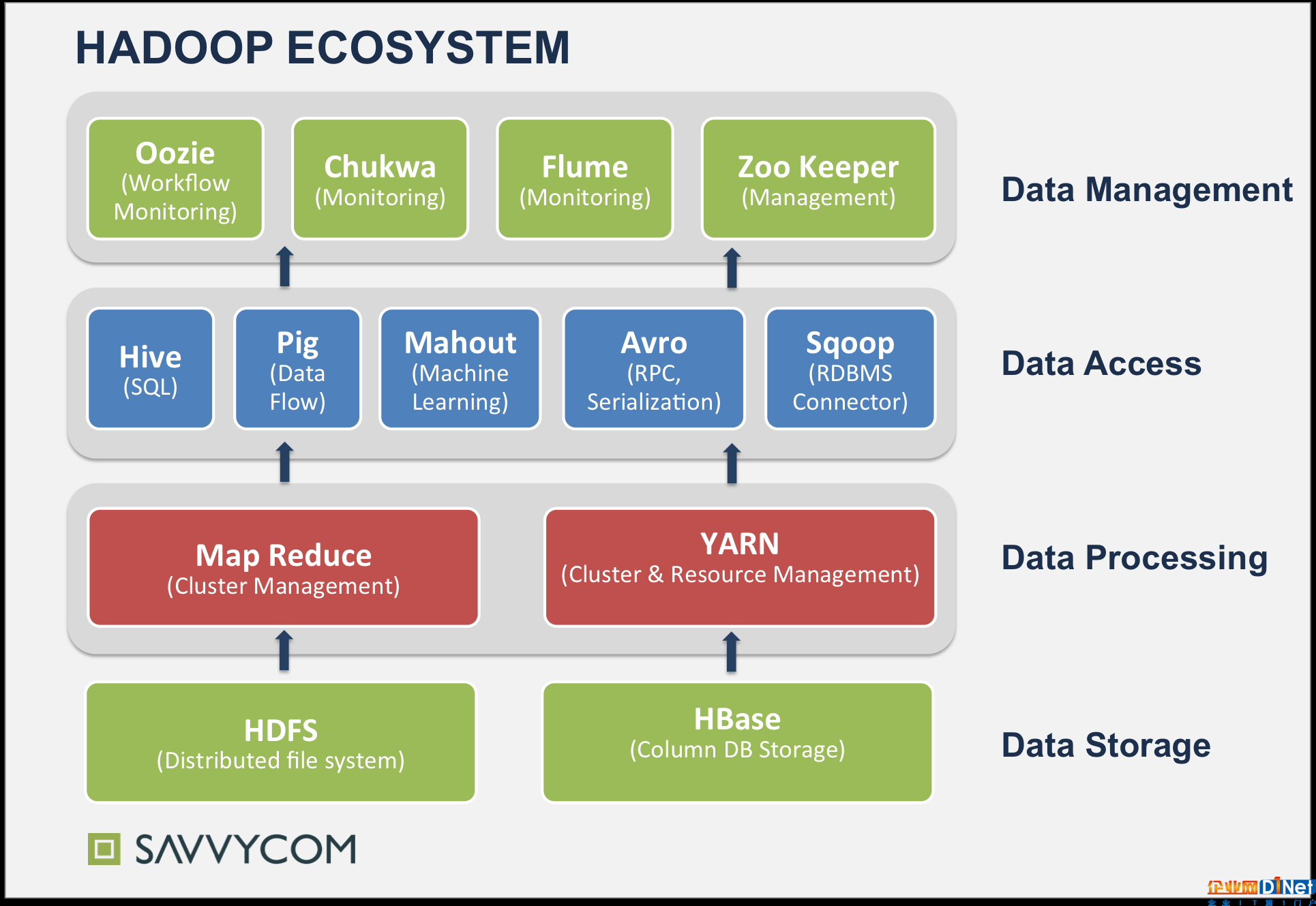
Cloudera是一家將Hadoop技術(shù)用于搜索引擎的公司,用戶可以采用全文搜索方式檢索存儲(chǔ)在HDFS(Hadoop分布式文件系統(tǒng))和Apache HBase里面的數(shù)據(jù),再加上開(kāi)源的搜索引擎Apache Solr,Cloudera提供了搜索功能,并結(jié)合Apache ZooKeeper進(jìn)行分布式處理的管理、索引切分以及高性能檢索。
PageRank谷歌Pagerank算法基于隨機(jī)沖浪模型,基本思想是基于網(wǎng)站之間的相互投票,即我們常說(shuō)的網(wǎng)站之間互相指向。如果判斷一個(gè)網(wǎng)站是高質(zhì)量站點(diǎn)時(shí),那么該網(wǎng)站應(yīng)該是被很多高質(zhì)量的網(wǎng)站引用又或者是該網(wǎng)站引用了大量的高質(zhì)量權(quán)威的站點(diǎn)。
- 國(guó)際化
坦白說(shuō),Google雖然做得非常好,無(wú)論是技術(shù)還是產(chǎn)品設(shè)計(jì),都很好。但是國(guó)際化確實(shí)是非常難做的,很多時(shí)候在細(xì)分領(lǐng)域還是會(huì)有其他搜索引擎的生存余地。例如在韓國(guó),Naver是用戶的首選,它本身基于Yahoo的Overture系統(tǒng),廣告系統(tǒng)則是自己開(kāi)發(fā)的。在捷克,我們則更多會(huì)使用Seznam。在瑞典,用戶更多選擇Eniro,它最初是瑞典的黃頁(yè)開(kāi)發(fā)公司。
國(guó)際化、個(gè)性化搜索、匿名搜索,這些都是Google這樣的產(chǎn)品所不能完全覆蓋到的,事實(shí)上,也沒(méi)有任何一款產(chǎn)品可以適用于所有需求。
自己實(shí)現(xiàn)搜索引擎
如果我們想要實(shí)現(xiàn)搜索引擎,最重要的是索引模塊和搜索模塊。索引模塊在不同的機(jī)器上各自進(jìn)行對(duì)資源的索引,并把索引文件統(tǒng)一傳輸?shù)酵粋€(gè)地方(可以是在遠(yuǎn)程服務(wù)器上,也可以是在本地)。搜索模塊則利用這些從多個(gè)索引模塊收集到的數(shù)據(jù)完成用戶的搜索請(qǐng)求。因此,我們可以理解兩個(gè)模塊之間相對(duì)是獨(dú)立的,它們之間的關(guān)聯(lián)不是通過(guò)代碼,而是通過(guò)索引和元數(shù)據(jù),如下圖所示。
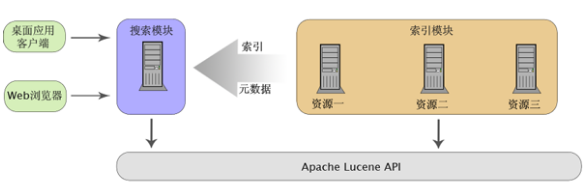
對(duì)于索引的建立,我們需要注意性能問(wèn)題。當(dāng)需要進(jìn)行索引的資源數(shù)目不多時(shí),隔一定的時(shí)間進(jìn)行一次完全索引,不會(huì)占用很長(zhǎng)時(shí)間。但在大型應(yīng)用中,資源的容量是巨大的,如果每次都進(jìn)行完整的索引,耗費(fèi)的時(shí)間會(huì)很驚人。我們可以通過(guò)跳過(guò)已經(jīng)索引的資源內(nèi)容,刪除已不存在的資源內(nèi)容的索引,并進(jìn)行增量索引來(lái)解決這個(gè)問(wèn)題。這可能會(huì)涉及文件校驗(yàn)和索引刪除等。另一方面,框架可以提供查詢緩存功能,提高查詢效率。框架可以在內(nèi)存中建立一級(jí)緩存,并使用如 OSCache或 EHCache緩存框架,實(shí)現(xiàn)磁盤上的二級(jí)緩存。當(dāng)索引的內(nèi)容變化不頻繁時(shí),使用查詢緩存更會(huì)明顯地提高查詢速度、降低資源消耗。
搜索引擎解決方案
Sphinx俄羅斯一家公司開(kāi)源的全文搜索引擎軟件Sphinx,單一索引最大可包含1億條記錄,在1千萬(wàn)條記錄情況下的查詢速度為0.x秒(毫秒級(jí))。Sphinx創(chuàng)建索引的速度很快,根據(jù)網(wǎng)上的資料,Sphinx創(chuàng)建100萬(wàn)條記錄的索引只需3~4分鐘,創(chuàng)建1000萬(wàn)條記錄的索引可以在50分鐘內(nèi)完成,而只包含最新10萬(wàn)條記錄的增量索引,重建一次只需幾十秒。
OmniFindOmniFind 是 IBM 公司推出的企業(yè)級(jí)搜索解決方案。基于 UIMA (Unstructured Information Management Architecture) 技術(shù),它提供了強(qiáng)大的索引和獲取信息功能,支持巨大數(shù)量、多種類型的文檔資源(無(wú)論是結(jié)構(gòu)化還是非結(jié)構(gòu)化),并為 Lotus Domino 和 WebSphere Portal 專門進(jìn)行了優(yōu)化。
下一代搜索引擎
從技術(shù)和產(chǎn)品層面來(lái)看,接下來(lái)的幾年,甚至于更長(zhǎng)時(shí)間,應(yīng)該沒(méi)有哪一家搜索引擎可以撼動(dòng)谷歌的技術(shù)領(lǐng)先優(yōu)勢(shì)和產(chǎn)品地位。但是我們也可以發(fā)現(xiàn)一些現(xiàn)象,例如搜索假期租房的時(shí)候,人們更喜歡使用Airbub,而不是Google,這就是針對(duì)匿名/個(gè)性化搜索需求,這些需求是谷歌所不能完全覆蓋到的,畢竟原始數(shù)據(jù)并不在谷歌。我們可以看一個(gè)例子:DuckDuckGo。這是一款有別于大眾理解的搜索引擎,DuckDuckGo強(qiáng)調(diào)的是最佳答案,而不是更多的結(jié)果,所以每個(gè)人搜索相同關(guān)鍵詞時(shí),返回的結(jié)果是不一樣的。
另一個(gè)方面技術(shù)趨勢(shì)是引入人工智能技術(shù)。在搜索體驗(yàn)上,通過(guò)大量算法的引入,對(duì)用戶搜索的內(nèi)容和訪問(wèn)偏好進(jìn)行分析,將標(biāo)題摘要進(jìn)行一定程度的優(yōu)化,以更容易理解的方式呈現(xiàn)給用戶。谷歌在搜索引擎AI化的步驟領(lǐng)先于其他廠商,2016年,隨著Amit Singhal被退休,John Giannandrea上位的交接班過(guò)程后,正式開(kāi)啟了自身的革命。Giannandrea是深度神經(jīng)網(wǎng)絡(luò)、近似人腦中的神經(jīng)元網(wǎng)絡(luò)研究方面的頂級(jí)專家,通過(guò)分析海量級(jí)的數(shù)字?jǐn)?shù)據(jù),這些神經(jīng)網(wǎng)絡(luò)可以學(xué)習(xí)排列方式,例如對(duì)圖片進(jìn)行分類、識(shí)別智能手機(jī)的語(yǔ)音控制等等,對(duì)應(yīng)也可以應(yīng)用在搜索引擎。因此,Singhal向Giannandrea的過(guò)渡,也意味著傳統(tǒng)人為干預(yù)的規(guī)則設(shè)置的搜索引擎向AI技術(shù)的過(guò)渡。引入深度學(xué)習(xí)技術(shù)之后的搜索引擎,通過(guò)不斷的模型訓(xùn)練,它會(huì)深層次地理解內(nèi)容,并為客戶提供更貼近實(shí)際需求的服務(wù),這才是它的有用,或者可怕之處。
作者介紹
周明耀,2004年畢業(yè)于浙江大學(xué),工學(xué)碩士。13年軟件研發(fā)經(jīng)驗(yàn),近10年技術(shù)團(tuán)隊(duì)管理經(jīng)驗(yàn),4年分布式計(jì)算、大數(shù)據(jù)技術(shù)經(jīng)驗(yàn)。出版書籍包括《大話Java性能優(yōu)化》、《深入理解JVM&G1 GC》、《技術(shù)領(lǐng)導(dǎo)力-碼農(nóng)如何才能帶團(tuán)隊(duì)》。個(gè)人微信號(hào)michael_tec,個(gè)人公眾號(hào)“麥克叔叔每晚10點(diǎn)說(shuō)”出品人,每天發(fā)布一篇技術(shù)短文






")

 京公網(wǎng)安備 11010502049343號(hào)
京公網(wǎng)安備 11010502049343號(hào)