









在近期舉行的PHPDublin見面會上,來自DynamicRes的架構(gòu)師Barry Sullivan被問到“什么是事件溯源”,作為對這個問題的回答,他在博客上寫下了這篇文章,詳細解釋了什么是事件溯源以及事件溯源有哪些好處。以下內(nèi)容翻譯自Barry的博客,已獲得作者授權(quán)。
Web開發(fā)的現(xiàn)狀
在詳細解釋事件溯源之前,先讓我們來看看Web開發(fā)的現(xiàn)狀。
當前的Web開發(fā)是以數(shù)據(jù)庫作為驅(qū)動的,在設計Web應用的時候,我們會自然而然地將系統(tǒng)設計與數(shù)據(jù)庫存儲機制聯(lián)系在一起。如果使用的是MySQL,我們就會把數(shù)據(jù)結(jié)構(gòu)設計成表,如果使用的是MongoDB,就會把數(shù)據(jù)結(jié)構(gòu)設計成文檔。這樣會強制我們只關(guān)注事物的當前狀態(tài),我們會想“怎樣保存這些數(shù)據(jù),以便將來可以再把它們拿出來(或者修改它們)”?
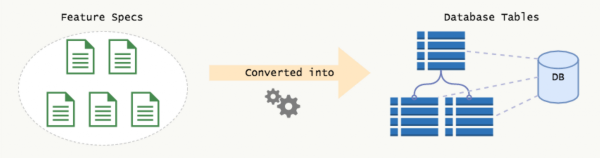
這種方式存在三個問題。
1. 有悖于我們的思維
人類的思考和交流并不是以狀態(tài)為中心。如果我們在咖啡店相遇,我會問你“最近可好”?如果你只是告訴我一堆狀態(tài)卻指望我從中猜出發(fā)生了什么事情,這是非常不合情理的。
“我有一幢房子、一輛汽車、一個冰箱、三個社交媒體賬號、一只貓咪,我的右腳有點痛,我不擅長聊天,我還有另一只貓咪……”
看到?jīng)]有?這樣我會瘋掉的。你應該告訴我,從上次見面之后都發(fā)生了哪些事情,這樣我才能知道你現(xiàn)在的狀況是什么樣子的。簡單地說,你應該告訴我一個故事,這個故事是由一連串事件組成的。
2. 單一的數(shù)據(jù)模型
在上圖中,讀寫操作使用了相同的模型。我們從寫數(shù)據(jù)的角度來設計表,然后基于這樣的結(jié)構(gòu)查詢數(shù)據(jù)。這對于小型的應用來說是沒有問題的,但用在大型的應用里就會有問題。隨著系統(tǒng)的增長,查詢會變得越來越復雜,總有一天,一個查詢可能會包含10個連接操作,代碼有100行那么多。系統(tǒng)很快就會變得脆弱無比,難以維護和變更。
3. 關(guān)鍵業(yè)務信息的丟失
這是一個大問題。在以表作為驅(qū)動的系統(tǒng)里,你只保存了系統(tǒng)的當前狀態(tài),你根本就無法知道系統(tǒng)是如何達到當前狀態(tài)的。如果我問你“這個用戶修改了幾次郵件地址”,你有辦法回答嗎?或者我再問“有多少人把一件商品添加到購物車里,然后又移除掉,直到一個月之后才買了那件商品”,你就更沒法回答了。你存儲數(shù)據(jù)的方式丟掉了很多有用的業(yè)務信息!
事件溯源
事件溯源與上述的情況恰好相反,它并不關(guān)心當前狀態(tài),而是關(guān)注持續(xù)不斷的變化事件。
舉個例子,假設我們有一個“購物車”,我們可以創(chuàng)建購物車,往里面添加商品或移除商品,然后結(jié)賬。
購物車的生命周期可以包含如下一系列事件:
創(chuàng)建購物車往購物車里添加商品再次往購物車里添加商品從購物車里移除商品結(jié)賬這些就是一個購物車的生命周期,包含了一系列事件。這就是事件溯源,非常簡單吧?
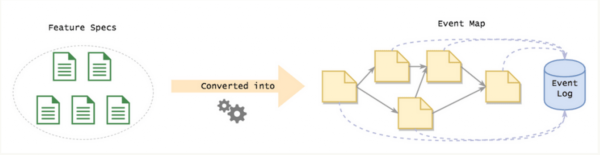
幾乎所有的流程都可以被看成一系列事件。在與領(lǐng)域?qū)<医徽剷r,他們不會提及“表”和“連接”,他們會將流程描述成一系列事件以及可以應用在這些事件上的規(guī)則。
如何實施業(yè)務規(guī)則?
大部分的業(yè)務操作都有硬性約束。對于購物車來說,它的約束就是“一件商品必須先被放進購物車后才能被移除”。如果一件商品沒有被添加到購物車里,又怎么能夠移除它?這種事件順序是不可能發(fā)生的。在沒有狀態(tài)的情況下,你怎樣才能知道“購物車里是否有這件商品”?
很簡單,你只要檢查之前是否發(fā)生過“商品被添加到購物車里”這個事件,這樣你就可以知道購物車里是否存在這件商品,然后移除它。
這樣不會浪費時間嗎?
一點也不。一般來說,要執(zhí)行約束,只需要獲得事件的一個很小子集。通過簡單的數(shù)據(jù)庫查詢就可以獲得有用的歷史事件,在加載完這些事件后重放它們,把它們“投射”出來,以此構(gòu)建你的數(shù)據(jù)集。這樣的操作其實是很快的,因為你使用的是本地的處理器,而不是執(zhí)行一系列SQL查詢(跨域網(wǎng)絡的調(diào)用要比本地操作慢得多,至少會相差兩個數(shù)量等級)。
如何展示數(shù)據(jù)?
如果說每一個狀態(tài)都是通過重放事件來獲得的,那么該如何抓取數(shù)據(jù)并把它們展示給用戶看?每次都需要抓取所有的數(shù)據(jù)然后再構(gòu)建這些數(shù)據(jù)集嗎?
答案是你沒必要這樣做,這樣做其實是很荒唐的。
你可以在后臺構(gòu)建數(shù)據(jù)集,然后把中間結(jié)果保存在數(shù)據(jù)庫里。這樣,用戶就可以在很短的時間內(nèi)查詢到這些數(shù)據(jù)。
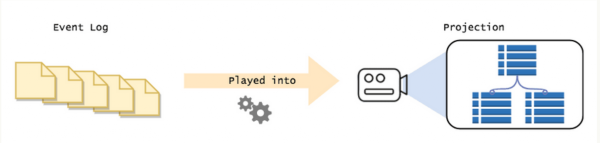
有了事件溯源,你就不再局限于當前的表結(jié)構(gòu)。需要做其他的查詢?只要設計一個新的結(jié)構(gòu)就可以了。你可以自由地實現(xiàn)各種讀取模型,在不需要它們的時候再把它們拋棄掉。
事件溯源的好處
1. 臨時的數(shù)據(jù)結(jié)構(gòu)
因為所有的狀態(tài)都可以通過重放事件獲得,所以就沒有必要把當前“狀態(tài)”與應用程序綁在一起。如果需要以新的方式查看數(shù)據(jù),直接創(chuàng)建新的數(shù)據(jù)視圖即可。不再需要繁雜的數(shù)據(jù)遷移腳本,要做的只是創(chuàng)建新視圖,拋棄舊視圖。我現(xiàn)在幾乎離不開事件溯源了。
2. 與領(lǐng)域?qū)<业臏贤ㄗ兊酶唵?/strong>
正如之前所述,領(lǐng)域?qū)<彝ǔI(yè)務流程描述成一系列事件,而不是狀態(tài)。基于事件溯源的系統(tǒng)與領(lǐng)域?qū)<业拿枋霾恢\而合,所以就沒有必要把他們的描述轉(zhuǎn)換成技術(shù)概念,這樣也避免了信息丟失。與領(lǐng)域?qū)<业臏贤ㄒ虼俗兊酶禹槙常驗槲覀冋谑褂盟麄兡軌蚶斫獾恼Z言與他們溝通,這也讓軟件開發(fā)變得很不一樣。
3. 極具表現(xiàn)力的模型
在事件溯源模型里,事件是一等對象,事件模型更加接近于實際的業(yè)務流程。這讓很多東西都變得清晰明了,你就不會陷入存儲技術(shù)的泥潭。
4. 生成報告更輕松
在事件溯源系統(tǒng)里,生成復雜的報告是一件輕而易舉的事情。你擁有完整的歷史事件,它們按照時間排序,你可以盡情地使用這些歷史數(shù)據(jù)。
以之前的例子為例,假設你想知道有多少個用戶從他們的購物車里移除了商品,卻在一周后購買了這些商品。按照一般的開發(fā)方式,通常需要幾周的時間才能開發(fā)出這個功能,而在發(fā)布之后,需要等上一段時間,等計算完所有數(shù)據(jù)之后才能生成報告。而在事件溯源系統(tǒng)里,你可以馬上得到報告。你還可以得到之前任何一個時間點的報告,仿佛擁有了一臺時光機。
5. 服務集成唾手可得
在標準的Web開發(fā)流程里,集成兩個系統(tǒng)通常會導致他們之間的耦合,而事件溯源系統(tǒng)通過事件來解耦被集成的系統(tǒng)。當一個系統(tǒng)發(fā)生某系事件需要觸發(fā)另一個系統(tǒng)的某個流程時,只需要寫一個事件監(jiān)聽器即可。這種機制可以讓你在不修改已有領(lǐng)域代碼的情況下增加新的集成邏輯或特性。
例如,你想要在用戶注冊的時候發(fā)送一封歡迎郵件給他們,你只需要創(chuàng)建一個事件監(jiān)聽器,監(jiān)聽“用戶注冊”事件,而不需要去修改注冊邏輯代碼。
6. 在一般的數(shù)據(jù)庫上也能健步如飛
你不需要使用多么奇特的數(shù)據(jù)庫來存儲事件,一般的MySQL數(shù)據(jù)庫就足以。數(shù)據(jù)庫都針對追加操作進行過優(yōu)化,所以存儲數(shù)據(jù)的速度是很快的。這也就是為什么事件溯源在當前的技術(shù)條件下能夠良好運作,保存事件都是追加操作。
7. 可以隨意更換數(shù)據(jù)庫
基于事件溯源的數(shù)據(jù)結(jié)構(gòu)都是臨時性的,所以你可以使用你喜歡的數(shù)據(jù)庫來存儲狀態(tài),也就是說你完全可以選擇最好的工具來完成你的工作。如果你發(fā)現(xiàn)了更好的工具,可以在任何時候把舊工具替換掉。我們目前正在從MySQL遷移到OrientDB,可以說是輕而易舉。
事件溯源的不足
天下沒有完美的東西,事件溯源給我們帶來了諸多好處,但也存在一些不足。
1. 最終一致性
事件溯源只能保證最終一致性。也就是說,在一個事件發(fā)生了之后,其他系統(tǒng)不會立即感知到它,在它們收到事件之前會有一定的延遲(比如100毫秒),所以你所投射的數(shù)據(jù)可能不是最新的。這看起來似乎是一個大問題,但其實不是的。例如,基于ReactJS構(gòu)建的Web應用會基于用戶的操作事件構(gòu)建狀態(tài),查詢端出現(xiàn)幾毫秒的延遲并不會有什么問題。
老實講,這可以說是塞翁失馬,焉知非福。最終一致性的系統(tǒng)具有容錯能力,可以解決服務中斷問題。如果使用微服務架構(gòu)或無服務器架構(gòu)來構(gòu)建分布式系統(tǒng),就需要通過最終一致性來保證穩(wěn)定性。
2. 事件結(jié)構(gòu)發(fā)生變化
事件結(jié)構(gòu)會發(fā)生變化,如果事先沒有考慮到這個問題,后續(xù)處理起來會有些麻煩。如果事件結(jié)構(gòu)發(fā)生變化,需要寫一個更新器來轉(zhuǎn)換新舊事件。轉(zhuǎn)換過程可以在將數(shù)據(jù)從數(shù)據(jù)存儲中讀取出來之后進行。這個沒有它看起來那么難,只需要準備好應對策略就可以了。
3. 開發(fā)人員需要改變思維
目前的Web開發(fā)主要還是以狀態(tài)作為驅(qū)動,所以開發(fā)者習慣了從表的角度看待問題,而不是事件。我發(fā)現(xiàn)要讓開發(fā)者改變思維需要一些時間,因為他們需要時間來改變習慣。最好的解決辦法是讓有經(jīng)驗的事件溯源開發(fā)者與傳統(tǒng)的開發(fā)者結(jié)對。
總結(jié)
我很喜歡事件溯源,在構(gòu)建大規(guī)模分布式系統(tǒng)時,它幫助我們解決了很多問題。我們可以使用領(lǐng)域?qū)<夷軌蛄私獾恼Z言與他們進行溝通,我們可以自由地改變和適配系統(tǒng)。盡管事件溯源有一定的學習曲線,但一旦你進入到這個領(lǐng)域,就不會想要回頭。
查看英文原文:Event Sourcing: What it is and why it's awesome
















 京公網(wǎng)安備 11010502049343號
京公網(wǎng)安備 11010502049343號