









Google開發了一種可以接受多種形式輸入并能生成多種形式輸出的算法。
目前,大部分機器學習應用程序都只能關注一個領域。機器翻譯一次只能建立一個語言對的模型,而圖像識別算法一次只執行一個任務(例如描述圖像、判斷圖像所屬類別或在圖像中查找對象)。然而,我們的大腦在執行所有任務時都能表現得很好,并且能夠將知識從一個領域轉移到另一個領域。大腦甚至可以將通過聽學到的知識轉換成其他領域的知識:看到或者讀到的知識。
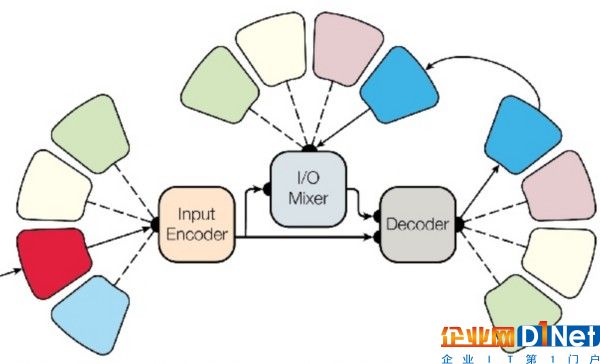
Google開發了一個能夠執行8個不同領域任務的模型:語音識別、圖像分類和添加標題、句法解析、英德互譯和英法互譯。這個模型由編碼器、解碼器和“輸入輸出混頻器”組成,其中“輸入輸出混頻器”會將先前的輸入和輸出饋送到解碼器。如下圖所示,每個“花瓣”表示一種形式(聲音、文本或圖像)。神經網絡可以通過任意一種輸入和輸出的形式來學習每個任務。
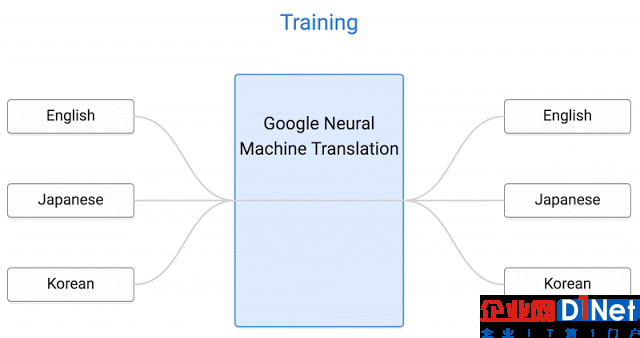
2016年11月,Google發布了zero-shot翻譯。該算法將所有句子映射到“中間語言”,“中間語言”指的是一種對于每種輸入語言和輸出語言都相同的句子。Google只針對英韓語言對和英日語言對進行了訓練,也就是說這個神經網絡并未學習過對應的日韓語言對,但這時這個神經網絡就能夠進行日韓互譯了。
Google報告稱,使用MultiModel時使用少量訓練數據的任務表現更好。機器學習模型通常在使用更多訓練數據的時候表現更好。使用MultiModel可以從多個領域獲取額外的數據。需要注意的是,使用這種方法并沒有打破標準任務任何已有的記錄。
MultiModel作為Tensor2Tensor庫的一部分在GitHub開源。有關這個模型更詳細的方法和研究結果可以在arxiv.com的論文One Model To Learn Them All中找到。
查看英文原文:Google Presents MultiModel: A Neural Network Capable of Learning Multiple Tasks in Multiple Domains
















 京公網安備 11010502049343號
京公網安備 11010502049343號