











文/安妮 陳樺 編譯自 The Next Platform (來源:量子位 報道 | 公眾號 QbitAI)
在上周召開的Google I/O 大會上,谷歌正式公布了第二代TPU,又稱Cloud TPU或TPU 2。但是,谷歌并沒有詳細介紹自己的新芯片,只展示了一些照片。
The Next Platform今天發布一篇文章,基于谷歌提供的圖片和細節,帶你深入了解谷歌的TPU2。量子位編譯如下:
首先要說明的一點是,谷歌不太可能向公眾出售TPU的芯片、主板或是服務器。目前看來,TPU2還是一個只供內部使用的產品。只有極少數人可以通過TensorFlow研究云(TRC)直接訪問TPU2的硬件,因為這本身就是為研究人員設計的具有“高度選擇性”的項目。研究人員可以分享他們發現的TPU2可加速代碼類型。谷歌還推出了Google Compute Engine Cloud TPU Alpha項目,我們可以假定,這也是一個高度選擇性的項目。
谷歌設計TPU2的首要目的,肯定是為了加速其面向消費者的核心軟件(比如搜索、地圖、語音識別和無人車的研究等項目)深度學習的工作量。我們對Google TRC的粗略解讀是,Google想借此招募人員去研究適合TPU2的超網格的工作負載。
谷歌表示,TRC項目雖然開始規模較小,但之后會逐步擴大。如果Google的研究推廣到一般的應用程序,那么其他人員也可以直接訪問TPU2。那時Google將為其谷歌云平臺的公共云增添一個TensorFlow硬件實例。
TPU2能有今天,離不開去年Google I/O大會上第一代TPU的貢獻。一代TPU也是專為機器學習設計的特定目的芯片,還應用在了AlphaGo、搜索、翻譯、相冊等背后的機器學習模型中。 TPU通過兩個PCI-E 3.0 x8邊緣連接器連接協處理器(參見下面兩張照片的左下角),總共有16 GB/s的雙向帶寬。TPU消耗功率高達40瓦,遠高于PCI-E 電源規格,可為8位整數運算提供每秒92萬億次的運算,或為16位整數運算提供每秒23萬億次的運算。為了進行比較,Google聲稱,在半精度浮點數(FP16)情況下,TPU2可以達到每秒45萬億次的浮點運算。
TPU沒有內置的調度功能,也不能被虛擬化。它是一個直接連接到服務器主板的簡單矩陣乘法協處理器。

△ 谷歌的第一代TPU卡:A圖沒有散熱器;B圖有散熱器
在主板處理能力或其PCI-E 吞吐量超負載前,Google從不會透露有多少TPU連接到一個服務器主板。協處理器只需要做一件事,它需要以任務設置和拆卸的形式,從主機處理器獲取大量信息,并管理每個TPU數據的傳輸帶寬。
Google已將其TPU2設計用于四機架機柜,并將其稱為pod。機柜是相對于一組工作負載的標準機架配置(從半機架到多機架)。它為大型數據中心所有者提供更輕松廉價的購買、安裝和部署流程。例如,Microsoft的Azure Stack標準半機架就是一個機柜。
四機架機柜大小主要取決與Google正在使用的銅纜類型和全速運行的最大銅線長度。下圖顯示了機柜的高層次組織。
我們首先注意到,Google通過兩根電纜將每個TPU2板連接到一個服務器處理器板上。也可能是谷歌將每個TPU2板連接到兩個不同的處理器板,但是,即使是谷歌也不希望混淆該拓撲結構的安裝、編程和調度復雜性。如果在服務器主板和TPU2板之間存在一對一的連接,則要簡單得多。
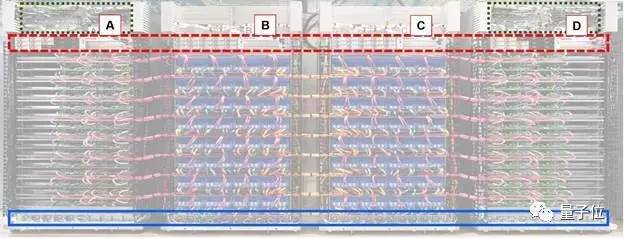
△ Google的TPU2機柜:A是CPU機架,B是TPU2機架,C是TPU2機架,D是CPU機架; 固體箱(藍色):不斷電電源系統(UPS); 虛線框(紅色)是電源; 虛線框(綠色)是機架式網絡交換機和機架式交換機頂部
谷歌展示了TPU2機柜的3張不同照片。在這3張照片中,配置和連線方式看起來一致。TPU2連線的顏色編碼有助于比較這些照片。

△ 三個谷歌TPU2機柜
谷歌展示了TPU2電路板的頂視圖,以及電路板前面板接口的近距離視圖。TPU2電路板的所有4個象限共享同一電源分配系統。我們認為,這4個TPU2電路板象限也通過簡單的網絡開關共享同一網絡連接。看起來,每個電路板象限都是一個獨立的子系統,而除此以外4個子系統之間并沒有相互連接。

△ TPU2板的俯視圖:A是四個TPU2芯片和散熱片;B是2個BlueLink 25GB / s電纜/ TPU2;C是兩種全路徑體系結構(OPA)電纜;D是電路板電源連接器,E很可能是一個網絡開關
前面板連接看起來像是QSFP網絡接口,但我從未在其他地方看到過。IBM BlueLink規范定義,對于最小25GB/s的配置(稱作‘子鏈接’),在上下行每個方向上需要8個200Gb/s信道(總共16個信道)。谷歌是OpenCAPI的成員,同時也是OpenPowerFoundation的創始成員,因此使用BlueLink規范是合理的。

△ TPU2面板連接
前面板中央的兩個接口看起來像是QSFP接口,介質為銅雙絞線,而不是光纖。這支持兩種網絡配置,分別為10Gbps以太網和100Gbps英特爾OPA連接。兩個100Gbps的OPA鏈路可以合并提供雙向25GB/s的帶寬,從而符合BlueLink規范要求的網速。因此我們認為,谷歌采用了100Gbps的OPA連接。
不過為了避免信號衰減帶來問題,這些銅纜、BlueLink或OPA的線纜長度不能超過3米。這意味著,CPU和TPU2電路板之間的物理距離不能超過3米。谷歌使用彩色編碼的線纜來連接,我猜測這是為了更方便地接線,避免出錯。可以看到,在前面板最前方的接口下方,有貼紙與線纜顏色一一對應。我們認為,顏色編碼表明,谷歌計劃更大規模地部署這些TPU2機柜。
白色線纜最有可能是1Gbps以太網連接,這個網絡用于系統管理。在照片中,我們并沒有看到,谷歌如何將管理網絡連接至TPU2電路板。不過,基于白色線纜的走線方式,我們可以假定,谷歌從機架背面將處理板連接至管理網絡。或許,處理板將通過OPA連接管理TPU2板,并評估這些電路板的健康狀況。
谷歌的TPU2機柜具有鏡像對稱性的特點。在下方圖片中,我們將處理器機柜D的照片進行鏡像翻轉,并與處理器機柜A進行比較。這兩個機柜看起來一模一樣,僅僅只是互為鏡像。在再下方的圖片中,可以看到機柜B和C也互為鏡像。


△ 比較兩個TPU2機架
谷歌的照片中并沒有展示足夠多的連線信息,以判斷電路板之間的準確網絡拓撲結構。不過這很可能是一種非常復雜的mesh網絡。
我們認為,CPU板是標準的英特爾至強雙socket主板,符合谷歌的1.5英寸服務器機架單元的尺寸。這是當前一代主板設計。考慮到對OPA的支持,這可能是Skylake主板(參見以下對功耗的探討)。我們猜測這是雙socket主板的原因僅僅在于,我沒有聽說過,在英特爾供應鏈中,有哪家廠商曾大量發貨單socket主板。不過,隨著AMD推出“Naples”Epyc X86服務器芯片,以及高通推出Centriq ARM服務器芯片,突出單socket配置,這樣的情況將發生改變。
我們認為,谷歌使用兩個OPA線纜將每塊CPU板連接至唯一的TPU2板,以實現25GB/s的總帶寬。這種一對一連接回答了關于TPU2的一個關鍵問題:谷歌在設計TPU2機柜時,將TPU2芯片與至強socket數量配比為2:1。這就是說,4顆TPU2芯片對應于一個雙socket至強服務器。
在深度學習任務中,GPU加速器采用的配比通常為4:1或6:1,而這種TPU2加速器與處理器之間的緊耦合與此有很大不同。2:1的配比表明,谷歌沿用了第一代TPU的設計哲學:“與GPU相比,TPU與FPU(浮點處理單元)之間關系更緊密。”處理器在谷歌TPU2架構中承擔了大量工作,同時把所有矩陣運算任務丟給了TPU2。
在TPU2機柜中,我們看不到任何存儲模塊。或許這正是下圖中機柜上方大量藍色光纖存在的原因。數據中心網絡連接至CPU板,同時沒有任何光纖連接至機柜B和C,而TPU2板上也沒有任何網絡連接。

△ 很多光纖帶寬連接到谷歌數據中心的其余部分
不管是TPU2還是CPU,每個機架上都有32個計算單位。每個機柜中有64個CPU板和64個TPU板,共有128個CPU芯片和256個TPU2芯片。
谷歌表示,其TRC包含1000個TPU2芯片,不過這個數字是去掉了零頭的。四個機柜包含1024個TPU2芯片。因此,四個機柜是Google已經部署了多少TPU2芯片的下限。在Google I/O上公布的照片中,可以看到三個機柜,也可能是四個。
現在我們還不清楚一個機柜中的CPU和TPU2芯片如何關聯,讓TPU2芯片可以通過超網格中的連接有效地共享數據。我們幾乎可以肯定,TRC不能跨機柜(256個TPU2芯片)處理單個任務。第一代TPU是一個簡單的協處理器,因此CPU負責處理所有數據流量。在這種架構中,CPU通過數據中心網絡訪問遠程存儲器數據。
谷歌沒有描述機柜的內存模型。TPU2芯片可以在OPA上使用遠程直接存儲器訪問(RDMA)從處理器板上的內存中加載自己的數據嗎?大概可以。
CPU板似乎也可能在機柜上執行相同操作,創建了大型共享內存池。該共享內存池不會像惠普企業版機器共享內存系統原型中的內存池那么快,但是有著25 GB/s的帶寬,它速度不會太慢,而是在兩位數太字節范圍內(每個DIMM 16GB,每個處理器有8個DIMM,每個板有兩個處理器,64個板產生16TB的內存)。
我們推測,在一個機柜上安排一個需要多個TPU2的任務看起來是這樣:
處理器池應該有一個機柜的超網格拓撲圖,哪些TPU2芯片可用于運行任務。
處理器組可能相互關聯,對每個TPU2進行編程,以明確地鏈接TPU2芯片之間的網格。
每個處理器板將數據和指令,加載到其配對的TPU2板上的四個TPU2芯片上,包括網狀互連的流量控制。
處理器在互連的TPU2芯片之間同步引導任務。
當任務完成時,處理器從TPU2芯片收集結果數據(該數據可能已經通過RDMA傳輸到全局存儲器池中),并將TPU2芯片標記為可用于另一任務。
這種方法的優點是TPU2芯片不需要理解多任務,虛擬化或多租戶,機柜上的所有這類運算都由CPU來處理。
這也意味著,如果Google想將云端TPU實例作為其谷歌云自定義機器類型IaaS的一種來提供,該實例將必須包括處理器和TPU2芯片。
目前我們還不清楚工作負載是否可以跨郵票進行縮放,并保留超級網格的低延遲和高吞吐量。雖然研究人員可以通過TRC訪問1,024個TPU2芯片中的一些,但將計算量擴展到整個機柜看起來是一個挑戰。研究人員或許能連接到多達256個TPU2芯片的集群,這足以令人印象深刻,因為云GPU連接目前才擴展到32個互連設備。
谷歌的第一代TPU運行時功耗40瓦,能以23 TOPS的速率執行16位整數矩陣乘法。TPU2的運行速度提高到45 TFLOPS,是上代的兩倍,同時通過升級到16位浮點運算,提高了計算復雜度。一個粗略的經驗法則表明,這樣功耗至少翻兩番:只是將運行速率提高一倍并升級到16位浮點運算,TPU2的功耗至少要提高到160瓦。
從散熱器的尺寸來看,TPU2的功耗可能更高,甚至高于200瓦。
TPU2板上,在TPU2芯片頂部有巨大的散熱片,它們是多年來我看到的最高的風冷散熱片。同時,它們還具有內部密封循環的水冷系統。在下圖中,我們將TPU2散熱片與過去幾個月看到的最大的散熱片相比較:

△ A是4個芯片構成的TPU2板側面圖;B是搭載雙IBM Power9的Zaius主板;C是雙IBM Power8的Minsky主板;D是雙英特爾至強的Facebook Yosemite主板;E是帶有散熱片的英偉達P100 SMX2模塊和Facebook Big Basin主板。
這些散熱器的尺寸都在高喊著“個個超過200瓦”。很容易看出,它們比上一代TPU上的40瓦散熱器大得多。這些散熱器的高度約能填滿兩個機架單元,接近3英寸。 (Google機架單元高度為1.5英寸,比行業標準1.75英寸U型稍矮)。
增加的功耗用在哪里了呢?
因此我們可以推測,TPU2芯片的內存容量也有所擴大,這有助于提高吞吐量,但同時也增加了功耗。
此外,Google從PCI-E插槽驅動單TPU(PCI-Express插槽向TPU卡供電)發展到單芯片TPU2板設計共享雙OPA端口和交換機,以及每個TPU2芯片兩個專用的BlueLink端口。OPA和BlueLink都增加了TPU2板級功耗。
Google的開放計算項目機架規格展示了功率為6千瓦,12千瓦和20千瓦的電力輸送配置文件;20千瓦的功率分配可以實現帶動90瓦的CPU。我們猜測,使用Skylake架構的Xeon處理器和處理大部分計算負載的TPU2芯片,機架A和D可能使用20千瓦電源。
機架B和C則不同。功率輸送為30千瓦,能夠為每個TPU2插槽提供200瓦的功率輸送,每個機架36千瓦將為每個TPU2插座提供250瓦的功率輸送。36千瓦是一種常見的高性能計算能力傳輸規范。我們相信,每芯片250瓦功耗也是Google為TPU2配置巨大散熱器的唯一原因。因此,單個TPU2機柜的功率傳輸可能在100千瓦至112千瓦范圍內,并且可能更接近較高數量。
這意味著TRC在滿負荷運行時消耗將近50萬瓦的功率。雖然四個機柜部署成本高昂,但卻是一次性的資本費用,并不占用大量的數據中心空間。然而,用50萬瓦的電力來持續資助學術研究,就算對Google這個規模的公司來說,也不是一筆小費用。如果TRC在一年內仍然運行,將表明Google正在認真為TPU2研究新用例。
TPU2機柜包含256個TPU2芯片。按每個TPU2芯片45 TFLOPS計算,每個機柜產生總共11.5 petaflops深度學習加速器的性能,計算它是16位浮點運算的峰值性能,也足以讓人印象深刻。深度學習訓練通常需要更高的精度,因此FP32矩陣乘法性能可能是FP16性能的四分之一,或者每個機柜約為2.9 petaflop,整個TRC是11.5 FP32 petaflops。
在峰值性能方面,這意味著在整個機柜上的FP16運算(不包括CPU性能貢獻或位于機柜之外的存儲),在每瓦100 - 115 gigaflops之間。
英特爾公布了雙插槽Skylake生成Xeon核心計數和功耗配置后,可以計算Xeon處理器的FP16和FP32性能,并將其增加到每瓦特的總體性能。
關于Google的TPU2機柜,還沒有足夠的信息讓我們能將其與英偉達Volta等商用產品進行比較。它們的架構差別太大,如果沒有基準,根本無法進行比較。僅僅是比較FP16峰值性能,就像對比兩臺處理器、內存、硬盤、顯卡都不一樣的PC,卻只考慮CPU主頻一樣。
也就是說,我們認為真正的比賽不在芯片級別。真正的挑戰在于擴展這些加速器的使用范圍。英偉達靠NVLink邁出了第一步,追求將自己的芯片獨立于CPU。 英偉達正在將其軟件基礎架構和工作負載從單一GPU擴展到GPU集群。
在谷歌推出第一代TPU時,選擇將其作為CPU的協處理器,到推出TPU2時,也只是將其擴展為處理器的2:1加速器。然而,TPU2超網格編程模型似乎還沒有可以擴展的工作負載類型。 Google正在尋求第三方幫助,來尋找可使用TPU2架構擴展的工作負載。

















 京公網安備 11010502049343號
京公網安備 11010502049343號