


雷鋒網(wǎng)AI科技評論消息,美國時間5月10日,NVIDIA CEO黃仁勛在開發(fā)者大會GTC2017上發(fā)布新一代GPU架構(gòu)Volta,首款核心為GV100,采用臺積電12nm制程,最大亮點(diǎn)是成倍提升了推理性能,意欲在目前稱霸機(jī)器學(xué)習(xí)訓(xùn)練場景的基礎(chǔ)上,在推理場景也成為最佳商用選擇。
GV100 GPU


據(jù)雷鋒網(wǎng)(公眾號:雷鋒網(wǎng))了解,Volta架構(gòu)GV100 GPU采用臺積電(TSMC)12nm FFN制程,具有5120個CUDA核心。相比上一代16nm制程的Pascal架構(gòu)GPU GP100,晶體管數(shù)目增加了38%,達(dá)到了驚人的211億個;核心面積也繼續(xù)增加33%,達(dá)到令人生畏的815mm2,約等于一塊Apple Watch的面積,據(jù)黃仁勛稱這樣的面積已經(jīng)達(dá)到了制造工藝極限。隨著核心的增大,GV100的單、雙精度浮點(diǎn)性能也大幅提升了41%。然而這還不是重點(diǎn),為了滿足GPU在機(jī)器學(xué)習(xí)中的性能需求,Volta架構(gòu)中引入了新的張量運(yùn)算指令Tensor Core,讓機(jī)器學(xué)習(xí)中訓(xùn)練速度提升約3倍、推理性能提升約10倍(相比上一代自家GPU GP100)。
GV100搭載在TESLA V100開發(fā)板上亮相,配合來自三星的16GB HBM2顯存,顯存帶寬也達(dá)到了900GB/s之高。
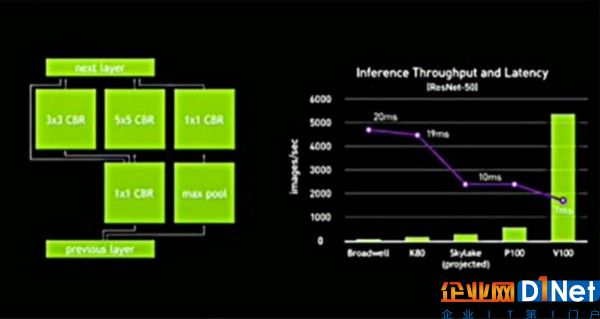
根據(jù)現(xiàn)場演講PPT,推理場景下,V100比上一代搭載GP100 CPU的P100板卡,圖像處理能力提升了約10倍,延遲也下降了約30%。在這樣的性能提升之下,GPU已經(jīng)可以讓FPGA和ASIC幾乎沒有用武之地,在商用場景中幾乎滿足全部計算需求。(詳細(xì)分析見文末)
DGX-1V、DGX Station

隨著GV100 GPU發(fā)布,NVIDIA的深度學(xué)習(xí)超級計算機(jī)也進(jìn)行了升級。老款DGX-1把原有Pascal GPU升級為Volta GPU,名字也更新為DGX-1V。它內(nèi)置八塊 Tesla V100開發(fā)板,合計顯存128G、運(yùn)算能力為 960 Tensor TFLOPS,即將邁入下一個時代。黃仁勛表示,過去 Titan X 需花費(fèi)八天訓(xùn)練的神經(jīng)網(wǎng)絡(luò),用 DGX-1V 只需八個小時。它相當(dāng)于是“把 400 個服務(wù)器裝進(jìn)一個盒子里”。
DGX Station 則是縮小版的 DGX-1V,黃仁勛稱其為“Personal DGX”,堪稱是終極個人深度學(xué)習(xí)電腦,各方面指標(biāo)均為DGX-1V的一半,但仍然已經(jīng)非常強(qiáng)大。英偉達(dá)內(nèi)部使用DGX Station已經(jīng)很久,每個工程師要么有 DGX-1V,要么有 DGX Station,再要么兩個都有。既然它確實(shí)能夠滿足工程師的需求,英偉達(dá)決定把這款產(chǎn)品推廣給公眾市場。
NVIDIA意圖通過GV100完全稱霸機(jī)器學(xué)習(xí)硬件市場
據(jù)雷鋒網(wǎng)AI科技評論了解,機(jī)器學(xué)習(xí)中需要用到高計算性能的場景有兩種,一種是訓(xùn)練,通過反復(fù)計算來調(diào)整神經(jīng)網(wǎng)絡(luò)架構(gòu)內(nèi)的參數(shù);另一種是推理,用已經(jīng)確定的參數(shù)批量化解決預(yù)定任務(wù)。而在這兩種場景中,共有三種硬件在進(jìn)行競爭,GPU、FPGA和ASIC。
GPU(以前是Graphics Processing Unit圖形計算單元,如今已經(jīng)是General Processing Unit通用計算單元)具有高的計算能力、高級開發(fā)環(huán)境、不影響機(jī)器學(xué)習(xí)算法切換的優(yōu)點(diǎn),雖然同等計算能力下能耗最高,但仍然在算法開發(fā)和機(jī)器學(xué)習(xí)訓(xùn)練場景中占據(jù)絕對的市場地位。
FPGA(Field-Programmable Gate Array,現(xiàn)場可編程矩陣門)是一種半成型的硬件,需要通過編程定義其中的單元配置和鏈接架構(gòu)才能進(jìn)行計算,相當(dāng)于也具有很高的通用性,功耗也較低,但開發(fā)成本很高、不便于隨時修改,訓(xùn)練場景下的性能不如GPU。
ASIC(Application Specific Integrated Circuits,專用集成電路)是根據(jù)確定的算法設(shè)計制造的專用電路,看起來就是一塊普通的芯片。由于是專用電路,可以高效低能耗地完成設(shè)計任務(wù),但是由于是專用設(shè)計的,所以只能執(zhí)行本來設(shè)計的任務(wù),在做出來以后想要改變算法是不可能的。谷歌的TPU(Tensor Processing Unit張量處理單元)就是一種介于ASIC和FPGA之間的芯片,只有部分的可定制性,目的是對確定算法的高效執(zhí)行。
所以目前的狀況是,雖然GPU在算法開發(fā)和機(jī)器學(xué)習(xí)訓(xùn)練場景中占有絕對地位;但是由于FPGA和ASIC在任務(wù)和算法確定的情況下,在長期穩(wěn)定大規(guī)模執(zhí)行(推理)方面有很大優(yōu)勢,所以GPU跟FPGA和ASIC之間還算互有進(jìn)退,尤其GPU相同性能下功耗很高,對大規(guī)模計算中心來說電費(fèi)都是很高的負(fù)擔(dān)。但隨著GV100對推理計算能力的約10倍提升,商用場景下已經(jīng)沒有必要為了推理場景更換硬件了,同一套GPU可以在訓(xùn)練場景的計算能力和推理場景的計算能力同時達(dá)到同功耗下最佳,還具有最好的拓展和修改能力,簡直別無所求。
面對提升如此明顯的GPU,一眾投身機(jī)器學(xué)習(xí)硬件的FGPA和ASIC廠商前景令人擔(dān)憂。也許現(xiàn)在唯一能讓他們松口氣的就是GV100 GPU的量產(chǎn)出貨時間要到2017年三四季度。等2018年,希望大規(guī)模部署后的GV100能用成倍提升后的性能給我們帶來新的驚喜。
AI科技評論招聘季全新啟動!
很多讀者在思考,“我和AI科技評論的距離在哪里?”答案就是:一封求職信。
AI科技評論自創(chuàng)立以來,圍繞學(xué)界和業(yè)界鰲頭,一直為讀者提供專業(yè)的AI學(xué)界、業(yè)界、開發(fā)者內(nèi)容報道。我們與學(xué)術(shù)界一流專家保持密切聯(lián)系,獲得第一手學(xué)術(shù)進(jìn)展;我們深入巨頭公司AI實(shí)驗(yàn)室,洞悉最新產(chǎn)業(yè)變化;我們覆蓋A類國際學(xué)術(shù)會議,發(fā)現(xiàn)和推動學(xué)術(shù)界和產(chǎn)業(yè)界的不斷融合。
而你只要加入我們,就可以一起來記錄這個風(fēng)起云涌的人工智能時代!






的新GPU來了,F(xiàn)PGA和ASIC要扔掉嗎?")

 京公網(wǎng)安備 11010502049343號
京公網(wǎng)安備 11010502049343號