









前言
Yahoo Big ML團隊宣布開源TensorFlowOnSpark,他們用來在大數據集群的分布式深度學習最新的開源框架。
Yahoo Big ML團隊成員Lee Yang、Jun Shi、Bobbie Chern和Andy Feng日前合著了一篇文章,詳細介紹了他們開源的TensorFlowOnSpark的方方面面。
Yahoo開源的TensorFlowOnSpark使Google發起的TensorFlow深度學習開源框架與Apache Spark集群中的數據集兼容,一些組織為了處理大量不同類型的數據而進行維護,對他們來說無疑是個好消息。
Yahoo開源TensorFlowOnSpark采用了Apache 2.0協議許可,并在GitHub上發布。
深度學習通常涉及大量數據進行人工神經網絡訓練,比如說照片,然后指導神經網絡對新數據做出最佳猜測。深度學習在很多公司非常熱門。
差不多就在一年前,Yahoo開源CaffeOnSpark,為Caffe開源深度學習框架提供了Spark支持。而今天,Yahoo正在做同樣的工作,但這一次,帶來了不同的框架:TensorFlowOnSpark。
該團隊評估了SparkNet和TensorFrame等選擇,但最終,他們決定建立自己的框架。他們的軟件使用Spark工具,如SparkSQL、Mlib和Python notebook連接到Spark集群,但它也將和Hadoop合作。
Yahoo表示,把 TensorFlow 程序移植到 TensorFlowOnSpark 相對方便,并經過反公司內部的反復驗證。
InfoQ翻譯并整理本文。
正文
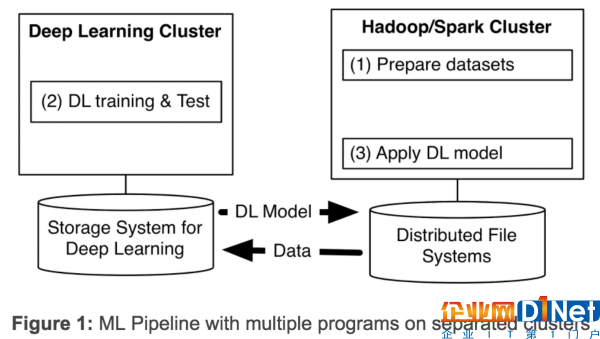
深度學習(DL)在最近幾年快馬加鞭地發展。在Yahoo,我們發現,為了從海量數據中獲得洞察力,需要部署分布式深度學習。現有的DL框架通常需要為深度學習設置單獨的集群,迫使我們為機器學習流程創建多個程序(見圖1)。擁有獨立的集群需要我們在它們之間傳遞大型數據集,從而引起不必要的系統復雜性和端到端的學習延遲。
去年我們通過開發和發布CaffeOnSpark來解決scaleout問題,我們的開源框架,支持在相同的Spark和Hadoop集群進行分布式深度學習和大數據處理。我們在Yahoo使用CaffeOnSpark來改善我們的NSFW圖像檢測,比如自動從現場直播等自動識別電競比賽等。借助社區的寶貴意見和貢獻,CaffeOnSpark已經升級,支持LSTM,帶有一個新的數據層,可用于訓練和測試交錯,還有一個Python API以及在Docker容器上的部署。對我們來說,這些極大提升了用戶體驗。但對于那些使用深層學習框架TensorFlow的用戶怎么辦呢 ?于是我們仿效之前的做法,開發了TensorFlowOnSpark。
在TensorFlow的首次發布后,谷歌在2016年4月發布了增強的TensorFlow與分布式深度學習功能。在2016年10月,TensorFlow宣布支持HDFS。然而,在Google云之外,用戶仍然需要一個專用于TensorFlow應用程序的集群。TensorFlow程序不能部署在現有的大數據集群上,從而增加了那些希望大規模利用這種技術的成本和延遲。
為了打破這個限制,一些社區項目將TensorFlow連接到Spark集群。SparkNet在Spark執行器添加了運行TensorFlow網絡的能力。DataBricks提出TensorFrame,用來使用TensorFlow程序操縱Apache Spark的DataFrames(數據幀)。雖然這些方法是在正確的方向邁出了一步,但我們檢查其代碼后,發現我們無法使多個TensorFlow進程直接相互通信,我們也無法實現異步分布式學習,我們還必須花費大量精力來遷移現有的TensorFlow程序。
TensorFlowOnSpark
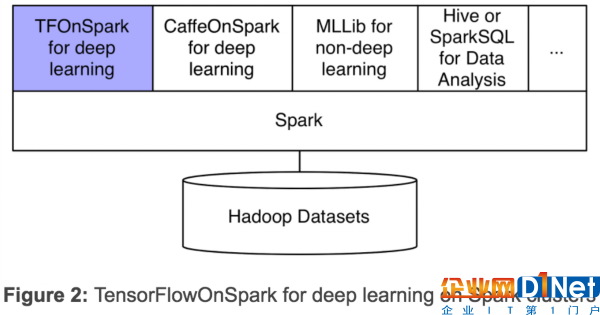
我們的新框架TensorFlowOnSpark(TFoS),支持TensorFlow在Spark和Hadoop集群上分布式執行。如上圖2所示,TensorFlowOnSpark被設計為與SparkSQL、MLlib和其他Spark庫一起在一個單獨流水線或程序(如Python notebook)中運行。
TensorFlowOnSpark支持所有類型的TensorFlow程序,可以實現異步和同步的訓練和推理。它支持模型并行性和數據的并行處理,以及TensorFlow工具(如Spark集群上的TensorBoard)。
任何TensorFlow程序都可以輕松地修改為在TensorFlowOnSpark上運行。通常情況下,需要改變的Python代碼少于10行。許多Yahoo平臺使用TensorFlow的開發人員很容易遷移TensorFlow程序,以便在TensorFlowOnSpark上執行。
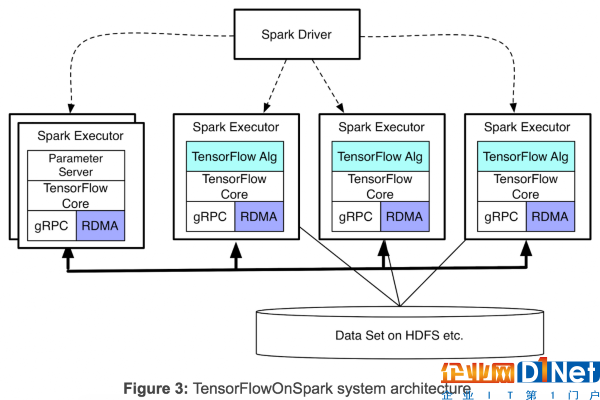
TensorFlowOnSpark支持TensorFlow進程(計算節點和參數服務節點)之間的直接張量通信。過程到過程的直接通信機制使TensorFlowOnSpark程序能夠在增加的機器上很輕松的進行擴展。如圖3所示,TensorFlowOnSpark不涉及張量通信中的Spark驅動程序,因此實現了與獨立TensorFlow集群類似的可擴展性。
TensorFlowOnSpark提供兩種不同的模式來提取訓練和推理數據:
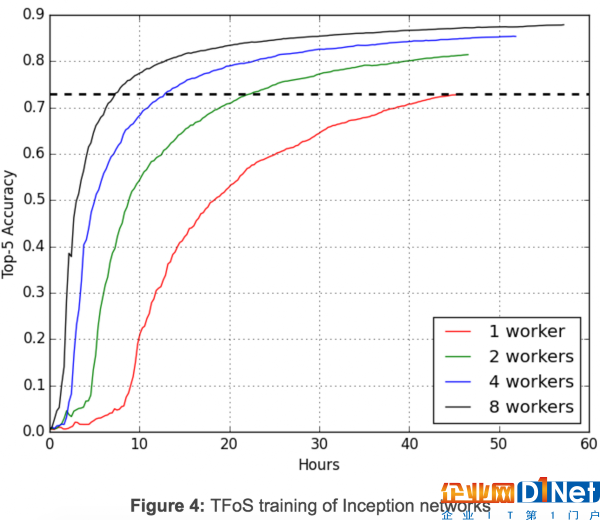
**TensorFlow QueueRunners:**TensorFlowOnSpark利用TensorFlow的file readers和QueueRunners直接從HDFS文件中讀取數據。Spark不涉及訪問數據。 Spark Feeding :Spark RDD數據被傳輸到每個Spark執行器里,隨后的數據將通過feed_dict傳入TensorFlow圖。圖4說明初始圖像分類中同時進行的分布式訓練如何使用TFoS中通過QueueRunners的一個簡單設置進行擴展:每個節點一個GPU、一個讀入以及批處理為32。四個TFoS工作同時進行,訓練100,000步。兩天后,當這些工作完成時,這些工作的前5個準確度分別為0.730、0.814、0.854和0.879。精確度達到0.730的單計算節點工作需要46小時,對于雙計算節點則需要22.5小時,4計算節點需要13小時,8計算節點工需要7.5小時。TFoS因此實現了接近模型訓練的近線性可擴展性。這是非常令人鼓舞的,雖然TFoS可擴展性會因不同的型號和超級數而有所不同。
分布式TensorFlow的RDMA
在Yahoo的Hadoop集群上,GPU節點通過以太網和Infiniband連接。Infiniband提供更快的連接,并支持通過RDMA直接訪問其他服務器的內存。然而,當前TensorFlow版本僅支持使用gRPC}通過以太網的分布式學習。為了加快分布式學習,我們增強了TensorFlow C ++層,以支持Infiniband上的RDMA。
為結合我們發布的TFoS,我們除了默認的“GRPC”協議外,還引入了新的TensorFlow服務器協議。任何分布式TensorFlow程序可以通過指定利用tf.train.ServerDef()或tf.train.Server()中的protocol="grpc_rdma"來使用增強版的TensorFlow。
使用此新協議,就需要創建RDMA匯集管理器以確保張量直接寫入遠程服務器的內存。我們最小化張量緩沖區的創建:Tensor緩沖區在開始時分配一次,然后在一個TensorFlow作業的所有訓練步驟中重復使用。從我們早期的實驗與大型模型(如VGG-19網絡)來看,業已證明,與現有GRPC相比,我們的TDMA實現在訓練時間上顯著加速了。
由于支持RDMA是一個高度要求的能力(見TensorFlow issue#2916),我們決定把現有的實現版本作為一個alpha版向TensorFlow社區開放。在接下來的幾周內,我們將進一步優化RDMA實現,并分享一些詳細的基準測試結果。
簡單的CLI和API
TFoS程序由標準的Apache Spark命令spark-submit來啟動。如下圖所示,用戶可以在CLI中指定Spark執行器的數目,每個執行器的GPU數量和參數服務器的數目。用戶還可以指定是否要使用TensorBoard(-tensorboard)和/或RDMA(-rdma)。
spark-submit –master ${MASTER} ${TFoS_HOME}/examples/slim/train_image_classifier.py –model_name inception_v3 –train_dir hdfs://default/slim_train –dataset_dir hdfs://default/data/imagenet –dataset_name imagenet –dataset_split_name train –cluster_size ${NUM_EXEC} –num_gpus ${NUM_GPU} –num_ps_tasks ${NUM_PS} –sync_replicas –replicas_to_aggregate ${NUM_WORKERS} –tensorboard –rdmaTFoS提供了一個高層次的Python API(在我們示例Python notebook說明):
TFCluster.reserve() … construct a TensorFlow cluster from Spark executors TFCluster.start() … launch Tensorflow program on the executors TFCluster.train() or TFCluster.inference() … feed RDD data to TensorFlow processes TFCluster.shutdown() … shutdown Tensorflow execution on executors開放源碼
TensorFlowOnSpark、TensorFlow的RDMA增強包、多個示例程序(包括MNIST,cifar10,創建以來,VGG)來說明TensorFlow方案TensorFlowOnSpark,并充分利用RDMA的簡單轉換過程。亞馬遜機器映像也可對AWS EC2應用TensorFlowOnSpark。
感謝杜小芳對本文的審校。
















 京公網安備 11010502049343號
京公網安備 11010502049343號