









本文對GitLab事件進行了全盤回顧,繼續追蹤GitLab在2月1日發布的申明,追溯各種問題根本原因。然后陳列了恢復在線后,GitLab聲明了哪些下一步舉措。最后摘錄了一些網友在Twitter和YouTube的評論,大多數人都對GitLab表達了自己的支持和寬容。
事件總覽
2017年1月31日18:00(UTC時間),GitLab通過推特發文承認300GB生產環境數據因為UNIX SA的誤操作,已經被徹底刪除(后發文補充說明已經挽回部分數據),引起業界一片嘩然。
2017年2月1日 18:14(UTC時間),GitLab.com恢復在線。通過使用一個之前的6小時備份數據庫,GitLab申明1月31日下午17:20(UTC時間)至晚上23:25(UTC時間)之間的數據已經被恢復并可以在生產環境使用,包括項目、問題、合并請求、用戶、注釋等等。
GitLab背景
GitLab目前是硅谷一顆冉冉升起的新星,它估值3.29千萬美元并且存放著寶貴的用戶數據。
GitLab是基于 Ruby on Rails 開發的一個開源的版本管理系統,它實現了一個自托管的Git項目倉庫,支持通過Web界面進行訪問公開的或者私人項目。
GitLab擁有與Github類似的功能,能夠瀏覽源代碼,管理缺陷和注釋。可以管理團隊對倉庫的訪問,非常易于瀏覽提交過的版本并提供一個文件歷史庫。團隊成員可以利用內置的簡單聊天程序進行交流。此外,GitLab提供了一個代碼片段收集功能,可以輕松實現代碼復用,便于日后有需要的時候進行查找。
自2012年上線以來,GitLab已經被超過10萬個公司或組織使用,包括IBM、Alibaba.com、Uber、Intel、VMWare等等。
事件影響
一句話概述
GitLab申明指出其一個數據庫出現了異常,導致GitLab.com丟失6個小時的數據庫數據(問題、合并請求、用戶、注釋等等),不過Git / wiki存儲庫和自托管安裝不受影響。
五點詳情
大約6個小時的數據丟失大約丟失5037個項目(其中4613個常規項目,74個fork, 350個import)。由于Git的repository沒有任何損失,所以GitLab可以重建數據事故之前已經存在的用戶/組的全部項目,但是并不能修復事故中的任何問題。丟失了大約4979(即5000)左右的注釋。可能丟失了707個用戶,很難準確進行評估(部分源自Kibana記錄)受影響的時間點:1月31日17:20之后創建的數據Offline前的種種掙扎
首次事故:垃圾郵件用戶的數據庫負載的峰值
2017年1月31日18:00(UTC時間)發現垃圾郵件發送者正在通過創建片段方式攻擊數據庫,目的是讓數據庫不穩定。工作人員隨即開始尋找問題并準備應對方案。
2017年1月31日18:00-21:00(UTC時間),工作人員(team-member-1 )正在預發布環境安裝pgpool和備份工具,為了拿到最新的生產環境數據他創建了一個LVM快照,這個快照會用于預發布環境,他希望可以重用這個快照用于引導其他的副本。這個操作在丟失數據前的6小時完成。
副本啟用的過程中發現存在問題,并且需要消耗大量時間(根據估計僅僅是初始化pg_basebackup同步過程就需要耗時20個小時以上)。LVM快照在工作人員可以修復問題之前又不能再其他副本上使用。整個修復過程都被這個問題耽擱下來。
2017年1月31日21:00(UTC時間),開始出現鎖定數據庫寫操作,并引起一些停機情況。進一步進行處理,措施包括鎖定垃圾郵件的發送IP、刪除一個用戶并啟用倉庫(造成47000個IP使用了相同的賬戶簽名,進而導致數據庫高負載)、刪除垃圾郵件用戶。
第二個事故:復制延遲觸發警報
2017年1月31日22:00(UTC時間),數據庫備份進展出現落后情況,查明造成原因是備份數據庫寫入操作時出現異常,導致沒有跟上備份節奏。
采取處理措施包括:嘗試修復db2數據庫,這時候備份落后了大概4GB。然后db2集群開始拒絕執行備份作業,db2集群拒絕連接到db1,調整max_wal_senders為db2,重啟PostgreSQL數據庫,隨即PostgreSQL數據庫提醒存在很多打開的連接,并拒絕啟動服務。管理人員隨即調整max_connections參數從8000調整至2000,PostgreSQL隨即啟動。注意,此時db2集群依然拒絕執行備份,處于未知原因的掛起狀態。
第三個事故:誤刪操作
2017年1月31日23:00(UTC時間),工作人員(team-member-1 )感覺pg_basebackup拒絕執行的原因是PostgreSQL數據文件夾已經存在,所以決定去移除這個文件夾。執行rm操作之后,該工作人員意識到命令正在db1.cluster.gitlab.com執行,而不是db2.cluster.gitlab.com。
2017年1月31日23:27(UTC時間),工作人員(team-member-1 )終止了刪除操作,300GB的數據僅剩余4.5GB。
下線,進入緊急狀態
GitLab決定下線GitLab.com并將事故通過推特向外公布,并且通過YouTube對外進行了修復過程的直播。

思考,羅列問題清單
GitLab進一步對遇到的問題進行梳理和逐一解釋,包括:
** LVM鏡像**默認每24小時執行一次。工作人員(team-member-1 )事故發生6小時之前手動執行了一次。
常規備份也是24小時執行一次,但是工作人員(team-member-1 )無法確定存放于何處。另外一名工作人員(team-member-2)認為這意味著失效,因為產生的文件只有幾個字節。
一名工作人員(Team-member-3):PostgreSQL9.2的二進制文件開始運行,導致pg_dump失敗。由于數據庫版本設置為PostgreSQL9.6,最終導致SQL備份不啟用。
Azure上的磁盤鏡像只是針對NFS服務器,沒有針對數據庫服務器。
同步過程移除了webhooks。除非我們可以從過去24小時的常規備份中提取這些內容,否則將丟失。
復制過程極度脆弱,很易出錯,依賴于一系列Shell腳本,而這些腳本的注釋很差。
S3 備份過程沒有正常工作。
當備份失敗時,沒有可靠的警報/分頁,在dev host上面現在也看到這一點
綜上所述,5個備份/復制技術都沒有正常工作。無奈之下,我們最終啟用6小時之前的備份。
pg_basebackup需要等待主機啟動復制過程完畢,這個過程需要10分鐘。這個過程會導致我們認為復制過程卡住了。使用strace命令也看不出什么問題原因。
行動, 恢復過程
GitLab的官方聲明中說明了恢復過程的執行步驟:
** 2017年2月1日00:36**(UTC時間),備份db1.staging.gitlab.com數據。
** 2017年2月1日00:55**(UTC時間),掛載db1.staging.gitlab.com到db1.cluster.gitlab.com。從/var/opt/gitlab/postgresql/data/拷貝數據到生產環境/var/opt/gitlab/postgresql/data/。
2017年2月1日01:05(UTC時間),nfs-share01服務器被征用作為臨時備份服務器,放置于/var/opt/gitlab/db-meltdown。
2017年2月1日01:18(UTC時間),包括還存在的生產環境數據,包括pg_xlog,命名為20170131-db-meltodwn-backup.tar.gz。
下面這張圖顯示了刪除和隨后恢復事件的時間。
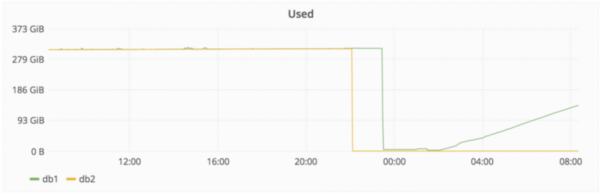
未完,GitLab下一步打算
Todo list
為不同的環境改變Linux終端的格式或者顏色,例如紅色代表生產環境,黃色代表測試環境。針對所有用戶在shell提示符處顯示機器的完整名字,例如db1.staging.gitlab.com,而不是僅僅是“db1”。: https://gitlab.com/gitlab-com/infrastructure/issues/1094
針對postgresql的文件夾拒絕執行rm -rf這樣的命令?可以設置命令執行保護或者針對數據庫文件夾有對應的備份措施。
為備份增加提醒:檢查S3倉庫之類的體型。增加圖形化界面,顯示時間變化后的備份大小,當下降超過10%時發出警報。:https://gitlab.com/gitlab-com/infrastructure/issues/1095
找出為什么PostgreSQL在max_connections被設置為8000之后突然出現問題,這個設置在2016年5月13日就已經完成了。因為這個問題的突然出現導致了其他很多問題。https://gitlab.com/gitlab-com/infrastructure/issues/1096
通過WAL歸檔增加備份閾值,這個方法對審計失敗也許有用。https://gitlab.com/gitlab-com/infrastructure/issues/1097
針對上線產品創建常見問題查找指南手冊。
從一個數據中心移動數據到另一個數據中心可以通過AxCopy完成:微軟聲稱這個工具比rsync要快很多。看上去這是Windows上面的問題,但是沒有任何Windows專家參與。
五天內公開自省報告
GitLab官方申明指出丟失生產環境數據是不可以接受的錯誤,5天之內GitLab將對外發布錯誤發生及保護措施失效的原因,并將發布一系列措施避免悲劇再次發生。
網友們的關注
GitLab致謝網友
GitLab申明最后感謝了共計42位網友的外援,他們通過Twitter和其他渠道上給出的技術建議。
網友留言
“keturu ta”的評價
我們在日本工作,我們能夠理解你們的痛苦和精神上的挫折。我們會一如既往地支持你們。
“Axel Dreyfus”的評價
現在已經很少看到這么開放的工作態度了。祝你們好運,永遠支持你們。千萬不要針對那個UNIX SA,他已經瘦了20磅(開玩笑)。
“Neer”的評價
這樣的事故對于任何人都有可能發生,我鼓勵涉及團隊不要有挫折感。這篇文章已經開始在社交媒體上流傳開來了,讓我感到這是一家非常公開和透明的公司。我之前沒有聽說過這個產品,但是從此以后我會開始使用它。
“Codepotato”的評價
感謝這樣的全面解釋。問題發生確實讓人感覺很丟臉,但是同時也體現了你們對外的開放態度。當務之急我們需要找到辦法提升恢復速度。
公開,直播修復過程
除了在網絡上對事故進行文字說明,GitLab還在YouTube上直播了其數據庫修復過程。該過程視頻時長8小時,共計有32萬人次觀看。https://www.youtube.com/watch?v=nc0hPGerSd4
寫在后面
事故處理過程中,GitLab采用了開放的態度,事故發生后第一時間對外公布,并對處理過程進行現場直播,讓全世界所有程序員都有機會一起參與恢復過程。GitLab也針對網友提出的關于肇事工作人員如何處理問題進行了官方回應,表態不會因為這次事件解雇事故相關技術人員。
正是由于這樣的開放性姿態,網友并沒有對事故的發生而進行謾罵、嘲諷,而是一起通過網絡對GitLab進行鼓勵,對處理事故團隊提供積極的技術建議。這樣的處理方式可以作為IT公司生產環境經典解決案例被寫入教科書。
















 京公網安備 11010502049343號
京公網安備 11010502049343號