


在銀行欺詐檢測,市場實時競價或網絡入侵檢測等領域通常是什么樣的數據集呢?
在這些領域使用的數據通常有不到1%少量但“有趣的”事件,例如欺詐者利用信用卡,用戶點擊廣告或者損壞的服務器掃描網絡。
然而,大多數機器學習算法對于不平衡數據集的處理不是很好。 以下七種技術可以幫你訓練分類器來檢測異常類。
1.使用正確的評估指標
對使用不平衡數據生成的模型應用不恰當的評估指標可能是危險的。
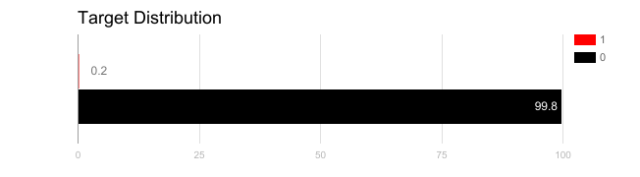
想象一下,我們的訓練數據如上圖所示。 如果使用精度來衡量模型的好壞,使用將所有測試樣本分類為“0”的模型具有很好的準確性(99.8%),但顯然這種模型不會為我們提供任何有價值的信息。
在這種情況下,可以應用其他替代評估指標,例如:
精度/特異性:有多少個選定的相關實例。
調用/靈敏度:選擇了多少個相關實例。
F1得分:精度和召回的諧波平均值。
MCC:觀察和預測的二進制分類之間的相關系數。
AUC:正確率與誤報率之間的關系。
2.重新采樣訓練集
除了使用不同的評估標準外,還可以選擇不同的數據集。使平衡數據集不平衡的兩種方法:欠采樣和過采樣。
欠采樣通過減少冗余類的大小來平衡數據集。當數據量足夠時使用此方法。通過將所有樣本保存在少數類中,并在多數類中隨機選擇相等數量的樣本,可以檢索平衡的新數據集以進一步建模。
相反,當數據量不足時會使用過采樣,嘗試通過增加稀有樣本的數量來平衡數據集。不是去除樣本的多樣性,而是通過使用諸如重復,自舉或SMOTE等方法生成新樣本(合成少數過采樣技術)
請注意,一種重采樣方法與另一種相比沒有絕對的優勢。這兩種方法的應用取決于它適用的用例和數據集本身。過度取樣和欠采樣不足結合使用也會有很好的效果。
3.以正確的方式使用K-fold交叉驗證
值得注意的是,使用過采樣方法來解決不平衡問題時,應適當地應用交叉驗證。切記,過采樣會觀察到稀有的樣本,并根據分布函數自舉生成新的隨機數據。如果在過采樣之后應用交叉驗證,那么我們所做的就是將模型過度適應于特定的人工引導結果。這就是為什么在過采樣數據之前應該始終進行交叉驗證,就像實現特征選擇一樣。只有對數據進行重復采樣,可以將隨機性引入到數據集中,以確保不會出現過擬合問題。
4.組合不同的重采樣數據集
生成通用模型的最簡單方法是使用更多的數據。問題是,開箱即用的分類器,如邏輯回歸或機森隨林,傾向于通過丟棄稀有樣例來推廣。一個簡單的最佳實現是建立n個模型,使用少數類的所有樣本和數量充足類別的n個不同樣本。假如您想要組合10個模型,需要少數類1000例,隨機抽取10.000例多數類的樣本。然后,只需將10000個樣本分成10個塊,訓練出10個不同的模型。
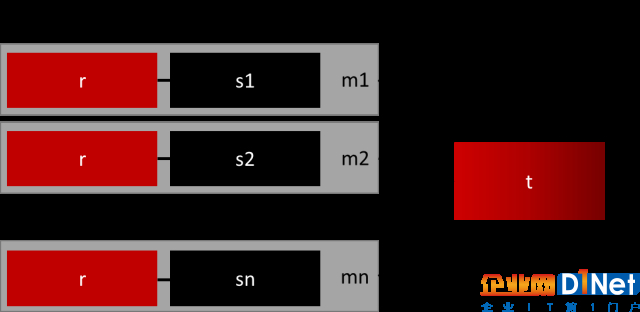
如果您有大量數據,那么這種方法很簡單,完美地實現水平擴展,因此您可以在不同的集群節點上訓練和運行模型。集合模型也趨于一般化,使得該方法容易處理。
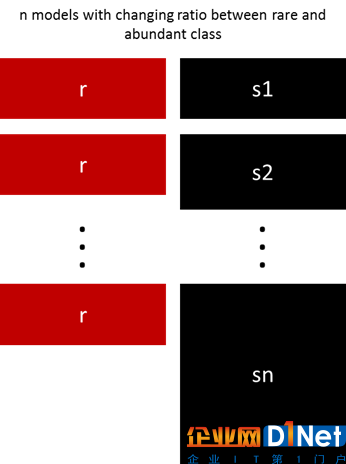
5.用不同比例重新采樣
以前的方法可以通過少數類和多數類之間的比例進行微調。最好的比例在很大程度上取決于所使用的數據和模型。但是,不是在整體中以相同的比例訓練所有模型,合并不同的比例值得嘗試。 所以如果訓練了10個模型,對一個模型比例為1:1(少數:多數),另一個1:3甚至是2:1的模型是有意義的。 根據使用的模型可以影響一個類獲得的權重。
6. 對多數類進行聚類
Sergey Quora提出了一種優雅的方法[2]。他建議不要依賴隨機樣本來覆蓋訓練樣本的種類,而是將r個分組中的多數類進行聚類,其中r為r中的樣本數。對于每個組,只保留質心(樣本的中心)。然后該模型僅保留了少數類和樣本質心來訓練。
7.設計自己的模型
以前的所有方法都集中在數據上,并將模型作為固定的組件。但事實上,如果模型適用于不平衡數據,則不需要對數據進行重新采樣。如果數據樣本沒有太多的傾斜,著名的XGBoost已經是一個很好的起點,因為該模型內部對數據進行了很好的處理,它訓練的數據并不是不平衡的。但是再次,如果數據被重新采樣,它只是悄悄進行。
通過設計一個損失函數來懲罰少數類的錯誤分類,而不是多數類,可以設計出許多自然泛化為支持少數類的模型。例如,調整SVM以相同的比例懲罰未被充分代表的少數類的分類錯誤。
綜上所述
這不是一份獨家的技術清單,而是處理不平衡數據的一個起點。
沒有適合所有問題的最佳方法或模型,強烈建議您嘗試不同的技術和模型來評估哪些方法最有效。 可以嘗試創造性地結合不同的方法。
同樣重要的是,要注意在不平衡類出現的許多領域(例如欺詐檢測,實時競價)中,“市場規則”正在不斷變化。所以,要查看一下過去的數據是否已經過時了。








 京公網安備 11010502049343號
京公網安備 11010502049343號