


Qwen-VL是支持中英文等多種語(yǔ)言的視覺(jué)語(yǔ)言(Vision Language,VL)模型,相較于此前的VL模型,Qwen-VL除了具備基本的圖文識(shí)別、描述、問(wèn)答及對(duì)話能力之外,還新增了視覺(jué)定位、圖像中文字理解等能力。
多模態(tài)是通用人工智能的重要技術(shù)演進(jìn)方向之一。業(yè)界普遍認(rèn)為,從單一感官的、僅支持文本輸入的語(yǔ)言模型,到“五官全開(kāi)”的,支持文本、圖像、音頻等多種信息輸入的多模態(tài)模型,蘊(yùn)含著大模型智能躍升的巨大可能。多模態(tài)能夠提升大模型對(duì)世界的理解程度,充分拓展大模型的使用場(chǎng)景。
視覺(jué)是人類的第一感官能力,也是研究者首先想賦予大模型的多模態(tài)能力。繼此前推出M6、OFA系列多模態(tài)模型之后,阿里云通義千問(wèn)團(tuán)隊(duì)又開(kāi)源了基于Qwen-7B的大規(guī)模視覺(jué)語(yǔ)言模型(Large Vision Language Model, LVLM)Qwen-VL。Qwen-VL及其視覺(jué)AI助手Qwen-VL-Chat均已上線ModelScope魔搭社區(qū),開(kāi)源、免費(fèi)、可商用。
用戶可從魔搭社區(qū)直接下載模型,也可通過(guò)阿里云靈積平臺(tái)訪問(wèn)調(diào)用Qwen-VL和Qwen-VL-Chat,阿里云為用戶提供包括模型訓(xùn)練、推理、部署、精調(diào)等在內(nèi)的全方位服務(wù)。
Qwen-VL可用于知識(shí)問(wèn)答、圖像標(biāo)題生成、圖像問(wèn)答、文檔問(wèn)答、細(xì)粒度視覺(jué)定位等場(chǎng)景。
比如,一位不懂中文的外國(guó)游客到醫(yī)院看病,不知怎么去往對(duì)應(yīng)科室,他拍下樓層導(dǎo)覽圖問(wèn)Qwen-VL“骨科在哪層”“耳鼻喉科去哪層”,Qwen-VL會(huì)根據(jù)圖片信息給出文字回復(fù),這是圖像問(wèn)答能力;再比如,輸入一張上海外灘的照片,讓Qwen-VL找出東方明珠,Qwen-VL能用檢測(cè)框準(zhǔn)確圈出對(duì)應(yīng)建筑,這是視覺(jué)定位能力。
Qwen-VL是業(yè)界首個(gè)支持中文開(kāi)放域定位的通用模型,開(kāi)放域視覺(jué)定位能力決定了大模型“視力”的精準(zhǔn)度,也即,能否在畫面中精準(zhǔn)地找出想找的事物,這對(duì)于VL模型在機(jī)器人操控等真實(shí)應(yīng)用場(chǎng)景的落地至關(guān)重要。


Qwen-VL以Qwen-7B為基座語(yǔ)言模型,在模型架構(gòu)上引入視覺(jué)編碼器,使得模型支持視覺(jué)信號(hào)輸入,并通過(guò)設(shè)計(jì)訓(xùn)練過(guò)程,讓模型具備對(duì)視覺(jué)信號(hào)的細(xì)粒度感知和理解能力。Qwen-VL支持的圖像輸入分辨率為448,此前開(kāi)源的LVLM模型通常僅支持224分辨率。在Qwen-VL 的基礎(chǔ)上,通義千問(wèn)團(tuán)隊(duì)使用對(duì)齊機(jī)制,打造了基于LLM的視覺(jué)AI助手Qwen-VL-Chat,可讓開(kāi)發(fā)者快速搭建具備多模態(tài)能力的對(duì)話應(yīng)用。
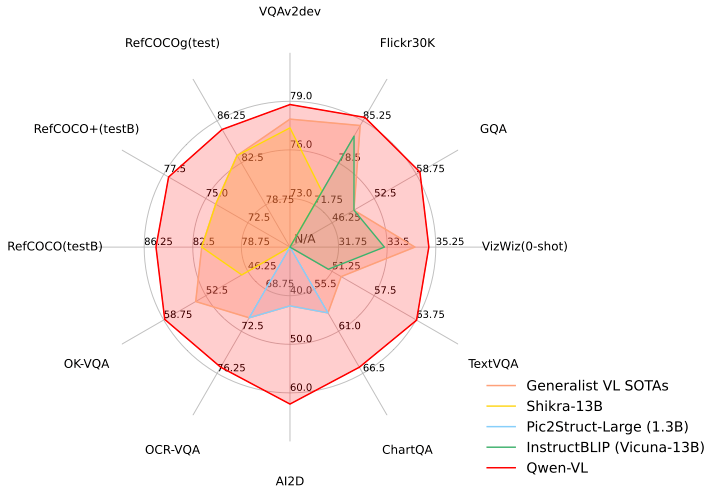
在四大類多模態(tài)任務(wù)(Zero-shot Caption/VQA/DocVQA/Grounding)的標(biāo)準(zhǔn)英文測(cè)評(píng)中,Qwen-VL取得了同等尺寸開(kāi)源LVLM的最好效果。為了測(cè)試模型的多模態(tài)對(duì)話能力,通義千問(wèn)團(tuán)隊(duì)構(gòu)建了一套基于GPT-4打分機(jī)制的測(cè)試集“試金石”,對(duì)Qwen-VL-Chat及其他模型進(jìn)行對(duì)比測(cè)試,Qwen-VL-Chat在中英文的對(duì)齊評(píng)測(cè)中均取得了開(kāi)源LVLM最好結(jié)果。
8月初,阿里云開(kāi)源通義千問(wèn)70億參數(shù)通用模型Qwen-7B和對(duì)話模型Qwen-7B-Chat,成為國(guó)內(nèi)首個(gè)加入大模型開(kāi)源行列的大型科技企業(yè)。通義千問(wèn)開(kāi)源模型剛一上線就廣受關(guān)注,當(dāng)周沖上HuggingFace趨勢(shì)榜單,不到一個(gè)月在GitHub收獲3400多星,模型累計(jì)下載量已突破40萬(wàn)。






開(kāi)源第二波!大規(guī)模視覺(jué)語(yǔ)言模型Qwen-VL上線魔搭社區(qū)")

 京公網(wǎng)安備 11010502049343號(hào)
京公網(wǎng)安備 11010502049343號(hào)