


3月15日,經過多年技術沉淀與積累,依托于過硬的AI算法自研團隊,容聯云正式推出AI能力平臺“AI Kernel(云梯)”。
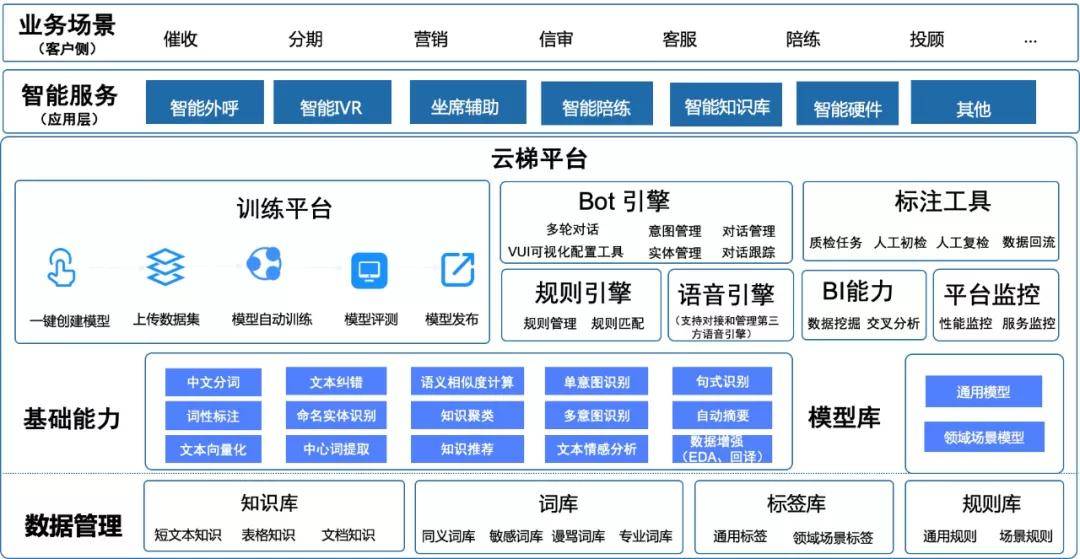
AI Kernel面向企業和集成開發商,提供基于自研算法封裝的NLP原子能力、全生命周期管理的自學習平臺與bot對話能能力等AI服務,幫助企業或集成開發商降低AI入門門檻,賦予其AI應用開發的自主建設能力,統籌管理企業AI能力和數據資源,實現智能化應用產品的快速落地。
云梯降低AI門檻 助力企業向平臺化建設轉型
當下,智能化發展是大勢所趨,企業在智能化進程中通常會面臨許問題。首先,AI開發是復合型的系統工程,需要既精通AI又懂工程,既理解技術又理解業務的復合型人才實現融合創新。但在AI人才供給緊張的今天,企業較難招到也難留住合適的AI人才。同時,算法模型的構建及訓練極其繁復、且算力要求高,技術瓶頸多,需要承擔巨額的開發成本。
其次,企業傳統的“煙囪式、項目制”開發模式,成本高、不易集成,過程重復,缺乏能力沉淀,缺少優化、協同、自動化輔助,業務響應緩慢。沒有統一的數據訪問渠道和統一的模型運行、監控平臺,以及更新、維護機制,基礎資源分散管理,未得到充分利用,造成浪費。
第三,隨著企業AI應用的不斷增加,各系統核心AI能力無法統一,大量寶貴的用戶數據分散在不同系統無法復用。客戶化AI應用需要依賴廠家進行定制開發,無法滿足日益增長的業務對開發敏捷度的要求。
容聯云AI Kernel打造更加包容、敏捷、高效的AI能力服務,降低企業AI入門門檻,幫助企業解決項目制、煙囪式AI建設存在的弊端,統籌管理NLP原子能力、模型和數據資源,同時提供可視化的線上模型訓練工具,助力企業向平臺化建設轉型,更容易、更快速地搭建適合業務場景需求的人工智能應用。
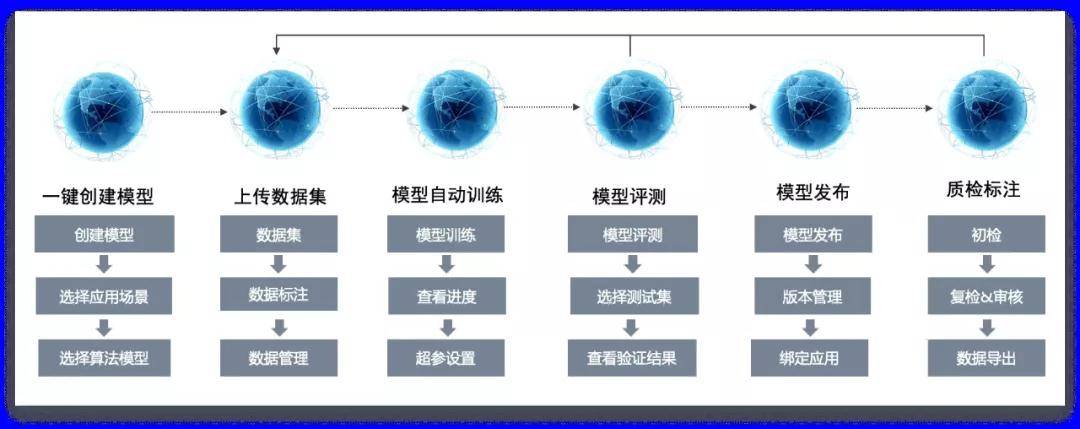
AI Kernel開放的自學習平臺,打通線上數據集管理、模型訓練、模型評測、模型發布等一體化流程。企業只需上傳數據集,勾選平臺已開放的各種算法組合,即可實現場景模型的自動訓練與評測。同時,平臺已沉淀和開放大量通用模型和領域模型,供平臺租戶直接使用,降低AI應用冷啟環節的耗時。
此外,AI Kernel開放API/SDK,輸出容聯AI原子化能力。企業或者集成開發商可以通過調用容聯AI原子能力靈活開發對話機器人、文本處理等智能化應用。開放NLP原子能力包含分詞詞性、文本糾錯、中心詞提取、語義相似度計算、意圖識別、情感分息等能力。

中文分詞與詞性標注:平臺將自然語言文本切分成語義合理、完整的詞匯序列,并為每個詞匯賦予一個詞性,如:動詞、名詞、介詞等。
- 意圖識別:基于規則模板+深度學習算法,平臺可快速解析用戶意圖,支持單意圖和多意圖識別。
- 實體識別:基于bert+bilstm+crf模型,實時自動抽取文本中具有特定意義的實體,如:人名、地名、機構名等。
- 文本糾錯:自動更正文本中存在錯誤的字段,降低由于文本錯誤帶來的語義解析不準或閱讀障礙。
- 語義相似度計算:基于海量數據訓練的網絡模型,計算句子之間的相似度,實現高精度語義相似度比對。
- 中心詞提取:基于BERT多任務訓練和MMR重排算法,自動提取文本核心關鍵詞語。
- 知識聚類:對大量未標注數據進行自動聚類,實現快速創建業務場景和知識擴充。
- 情感分析:對文本話術情感的積極性、消極性等進行精準的意見挖掘和傾向性分析。
- 自動摘要:自動預測文本片段中的關鍵信息生成文本摘要,提煉文本主題。
- 句式識別:基于深度學習文本分類模型,支持對句子句式進行識別,如:肯定句、否定句、疑問句、感嘆句等。
- 數據增強:借助EDA、回譯等手段,實現有限數據樣本的自動擴寫,幫助解決文本數據量不足或不均衡問題。
AI能力平臺為企業數字化提供有力支撐
容聯AI Kernel將企業標準化數據統一管理,方便復用和沉淀,統一的服務接口規范,支持服務動態編排組合。可視化集數據-訓練-評測-發布一體化的平臺,支持14項訓練超參設置,采用混淆矩陣4指標評測模型效果,支持自動拆分評測集,訓練-評測過程完全自動化進行,無須人工干預,評測完成郵件通知,支持多任務并行訓練,集中管理歷史數據/歷史模型版本,方便查詢回退。在統一資源管控(計算資源、存儲資源等),支持資源彈性調度,確保資源得到合理利用,避免資源浪費的同時,AI Kernel支持私有云、本地化部署方式。
目前,平臺已服務于金融、銀行、保險、證券、石化、汽車等諸多領域的智能營銷、智能催收、智能服務、智能質檢等應用場景。
作為容聯云AI能力的出口之一,AI Kernel加速了企業AI開發應用創新的速度,助力企業釋放AI的價值,為企業數字化提供有力的支撐。





 京公網安備 11010502049343號
京公網安備 11010502049343號