


近日,UCloud UHadoop 通過提供獨立的HDFS存儲集群、獨立的Hive元數據管理和獨立的計算集群,實現了兼顧靈活性與穩定性的存儲計算分離架構,幫助用戶更好的提升資源利用率,增加大數據業務部署的靈活性,同時降低運營成本。
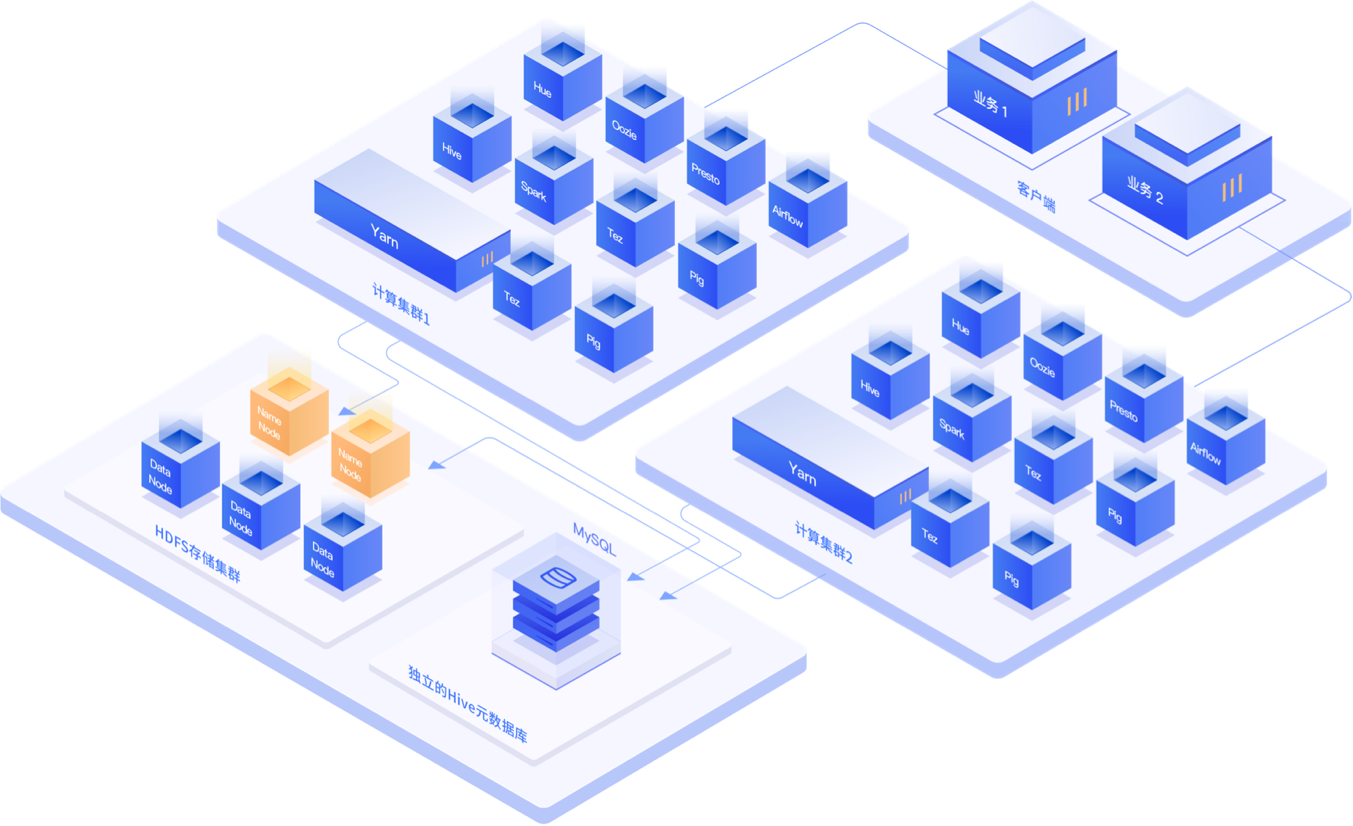
眾所周知,為了讓大規模分布式數據處理系統能發揮更好的性能,傳統的Hadoop架構是將計算節點和數據節點連在一起的。但隨著業務數據量爆發式增長以及企業對數據價值的不斷重視,數據存儲規模和數據計算需求經常是無法保持線性增長,計算和存儲這兩者之間隨之產生了“木桶效應”,極易造成資源的浪費,而用戶開始越來越關注數據存儲成本及計算成本的問題。
這時,計算與存儲資源的分離解耦,成為了一個非常合理的選擇。UCloud UHadoop帶來的計算與存儲的分離,完全消除了計算與存儲之間的“木桶效應”,在資源隔離、計算管理和存儲管理三個方面具有極大優勢,同時為業務創新、技術架構升級提供了更多的靈活性和可能性。
1. 不同業務計算資源的物理隔離,保障業務穩定
傳統模式下,用戶是通過配置資源隊列,來為不同業務分配計算資源,但這種方式實際上只能做到邏輯隔離,無法真正實現計算資源的物理隔離,不可避免會發生計算集群搶占資源的情況,業務與業務之間相互影響,導致業務狀態的不穩定。UCloud UHadoop 可以幫助用戶將不同業務拆分到不同計算集群上,實現計算資源的物理隔離,避免資源搶占、相互影響,從而保障業務持續穩定。
如離線業務與實時業務的隔離業務場景,用戶可以借助UCloud UHadoop將離線計算與實時計算 拆分成兩個計算集群,然后訪問獨立的HDFS存儲集群,有效隔離計算資源,保障業務的穩定。
2. 彈性管理計算資源,成本最優化
傳統資源配置下,計算資源調度水平受限于單臺機器的存儲容量。UCloud UHadoop實現了存儲與計算分離之后,用戶可根據業務需要,單獨增加計算節點,計算任務完成即可釋放計算資源,無需擔心臨時的大規模擴容帶來的成本飆升,更不用再進行跨集群數據拷貝操作,有效降低了管理集群的人力成本和服務器成本。
與此同時,若計算集群有故障或是計算集群框架升級,也不會直接影響獨立的HDFS集群中的數據,更好的保障了數據安全,同時也可縮短故障排查流程,降低集群運維成本。
3. HDFS存儲集群可單獨使用,更好滿足再分析需求
UCloud UHadoop提供獨立的HDFS存儲集群,用戶可以單獨使用存儲資源構建存儲集群,將歷史數據或者原始數據壓縮后進行歸檔存儲,當有數據分析的需求時,不需要進行數據遷移,即可完成數據分析任務,使用簡單、成本還低。
除了以上三個方面, UCloud UHadoop實現的存儲計算徹底分離,還可以讓多個不同版本Hadoop集群,分析底層同一份HDFS存儲集群中的數據,滿足了數據一致性要求,及歷史原因導致的多版本Hadoop集群共存問題。為優化集群整體成本,UCloud UHadoop 更是針對存儲計算分離場景推出了存儲更大、價格更低的機型,可根據不同數據量規模選擇不同節點機型,幫助用戶更好的降低成本。






 京公網安備 11010502049343號
京公網安備 11010502049343號