









過去幾十年中,大數據改變了一個又一個領域。在氣象科學領域,借助大數據,人們已經建立了更好的氣象模型,提前預報天氣;在高能物理領域,通過分析每秒4000萬次質子碰撞的數據,人類可以尋找曾經難以捉摸的希格斯玻色子的證據;在生命科學領域,通過大數據,研究人員得以在超過30億核苷酸的人類基因組中,探究其中至少一個版本的全序列,從而展開個性化基因研究;電商領域更是離不開大數據......我們知道,大數據的應用有很多,現在在教育行業,大數據應用也越來越多。
“正如越來越多的學生開始使用教育軟件和在線學習平臺,這些平臺獲取每一個學科、每一個學生的學習數據也變得越來越容易。”2017年1月10日,在論答公司(Learnta Inc.)于北京主辦的教育大數據研討會上,美國賓夕法尼亞大學(University of Pennsylvania)教育學院終身教授Ryan Baker指出。從Baker的分享中我們得知,教育數據挖掘至關重要,這些數據為教育平臺提供模型,這些模型讓學習系統從千人一面變成千人千面,從而改善目前的教育環境。具體情況如何,我們聽聽這個教授怎么說。
人類基因組測序
在美國,大量的學生每天都在使用Cognitive Tutor、ASSISTments、Reasoning Mind這樣的在線學習系統。比如,學生可以通過故事線索學數學,也可以在工作任務的情境中做語文題,甚至,孩子們一邊“打僵尸”一邊玩“數字游戲”:每個孩子都有很多武器,每件武器上都有自己的數字,如果要擊敗僵尸,武器上的數字必須整除僵尸胸口上的數字。
網絡教學(左下角:僵尸動作游戲Zombie Division)
Baker認為,這些個性化教育平臺至少要做到三件事:1、確定學生的有關數據;2、了解對于學生的學習來說什么是真正重要的;3、有針對性地為學生提供合適的教學。
所有這些在線學習系統都會產生大量的數據流。當一個學生使用一個在線學習平臺時,他每小時會產生數以百計的行為,多個學生就產生了教育大數據,比如在做出錯誤回答前可能會暫停和思考、尋求幫助、快速更改設置、從僵尸身邊跑開等,這些數據可以用于教育數據挖掘與分析。
這些教育數據挖掘有很多應用的方向,比如可以預測學生是否會輟學還是會成功完成學業;或者能自動檢測學生的學習投入程度、情感、學習策略等,目的就是為了更好地實現個性化教學;甚至可以給老師、家長提供學習分析報告,進行教育科學的基礎研究。
Baker說,通過教育數據挖掘,我們可以推斷學生的元認知(meta-cognition,即學生對自己認知的認識)以及學生是否會主動尋求幫助。同樣,也可以推測和推斷一個學生是否真正開始投入學習了,還是開始分心了。Baker舉了一個很有意思的親身經歷,看到有學生為了找正確答案而瞎蒙,在填空題里面填了“1”,發現不對,又改為填“2”,一直試到“38”這個數字,才找到正確答案。另外,有一些孩子會有非常難以解釋的行為,比如做數學題時不用方程的符號而是畫了一個笑臉。
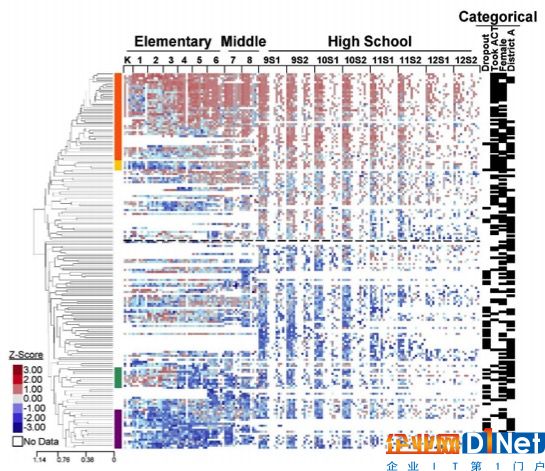
學生的成績與結果數據表
現在,基于教育大數據,Baker的研究團隊還有很多其他研究團隊都已經開發出了研究模型,這些模型可以根據數據來推斷學生是否厭倦、沮喪、困惑以及是否真正地投入到學習中去了也可以推斷學生在未來更長時間范圍內的學習結果:學生能夠記住剛才學到的知識嗎?學英語的時候,不僅現在能填對答案,在五年后還能用到嗎?學生在未來會不會有一個好的職業發展?
并且,這些模型已經被大規模地應用于自適應學習系統,為成千上萬的的學生所使用。
Baker列舉了全球七個大規模應用教育大數據分析模型的自適應學習系統,包括:
1、Knewton,系統自動決定下一步該給學生推送什么樣的學習問題,已經在全球范圍實際應用于多個學科。
2、ALEKS,基于先行知識結構和知識點模型,為學生推薦學習內容,已經應用于美國高中與大學的數學和科學學科。
3、Cognitive Tutor,自動檢測學生的知識掌握情況,把握教學進度,直到學生最終掌握知識;同時,自動檢測學生的學習專注程度,為學校做出相關分析報告。已經應用于美國的初中和高中數學學科。
4、Learnta(論答自適應學習系統),基于先行知識結構和知識點模型,為學生推薦學習內容;同時,自動檢測學生的知識掌握情況,把握教學進度,直至最終掌握每一個知識點。根據中國學生的學習需求而本土化開發,目前涵蓋數學和英語學科。
5、Reasoning Mind,自動檢測學生的學習專注度,為每個地區的教學管理員提供教師教學效果的報告,已經應用于美國的小學數學教育。
6、Duolingo(多鄰國),自動檢測學生的記憶,建議學生應當在什么時候復習之前學過的知識,已經在世界范圍內應用于外語詞匯的學習。
7、Civitas, Course Signals, Zogotech, 這些系統提供各種風險預測模型,給老師和學習顧問提供可具體實施和操作的學生信息,已經在世界范圍內的大學開始應用。
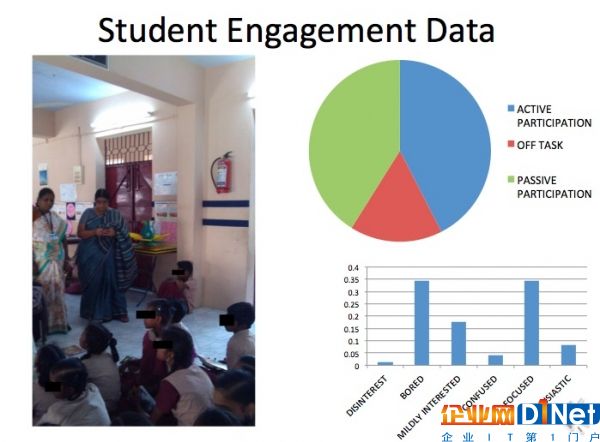
印度老師用手里的移動端采集學生的學習投入程度數據
Baker說,有足夠的實證研究證據證明,這七個學習系統中至少有以下兩個系統對于學生的學習是有顯著效果的:
其中一個是由胡祥恩教授在美國領導開展的多項實證研究項目,證明了ALEKS系統能夠有效提高各個不同族裔的美國學生的數學學習成績。
ALEKS系統
第二個是論答(Learnta)的自適應學習系統。Ryan Baker的研究團隊和論答公司合作,基于中國三個不同地區開展了三個實證研究項目,研究結果表明,學生通過論答自適應學習系統學習,比通過一個傳統的在線學習系統學習效果更好。
論答自適應學習系統
從長遠角度,Baker分析了這些教育大數據算法模型的潛在發展方向:
首先,通過學生知識和學習模型,來確定學生在什么時候需要更多支持,在學生掌握上一個知識之前,不會推薦該學生去學習下一個知識;而當學生需要支持的時候,系統會自動介入,并同時告訴該學生的老師和父母。
其次,通過學習投入程度模型,來檢測學生什么時候開始變得厭倦或者沮喪,并相應地調整學習任務,比如為那些厭倦的學生選擇一些更有趣的學習活動,為沮喪的學生選擇相對容易一些的學習任務。學習投入程度模型也可以用來確定為了讓學生更投入學習,需要什么樣的學習活動,最終甚至可以確定需要在什么時候提供、給什么樣的學生提供這些學習活動。
另外,還能告訴老師和父母,學生在什么時候開始在學習上變得分心。
最后,當一名學生沒有真正學會時,學習模型就可以檢測出來,并相應提供更多的練習,用不同的方法為學生提供解析,或者鼓勵學生自己去闡釋問題。
Baker最后總結道,這些不同的模型和方法現在都有很多應用的案例。教育人工智能(Artificial Intelligence in Education)、智能輔導系統(Intelligent Tutoring System)、教育數據挖掘(Educational Data Mining)、學習數據分析(Learning Analytics)等研究領域已經有大量有關這些模型和方法的研究文獻。下一步的目標應當是在系統中不斷優化現在已經成功應用的模型和方法,最大限度地造福于中國和全世界數十億的學生。
據悉,Baker是美國賓夕法尼亞大學(University of Pennsylvania)教育學院終身教授、學習數據分析研究中心(Penn Center for Learning Analytics)主任,國際教育數據挖掘協會(International Educational Data Mining Society)的創始人、《教育數據挖掘》雜志(Journal of Educational Data Mining)的主編。Baker教授在各類期刊和會議發表了260余篇學術論文,先后主持了美國科學基金會(National Science Foundation),蓋茨基金會(Gates Foundation)等研究基金的多項項目,累計獲得研究經費超過1600萬美元。Baker的研究實驗室同時與亞洲,南美洲,以及歐洲的大學和研究機構開展合作項目。Baker本人也在哥倫比亞大學教育學院(Teachers College, Columbia University)和愛丁堡大學同時擔任教職,并在Coursera 和 edX 慕課平臺上開設了“Big Data in Education”《教育大數據》課程,注冊學生來自100多個國家和地區。
本次活動的合辦方包括賓夕法尼亞大學學習分析學研究中心(Penn Center for Learning Analytics)、中國人民大學統計與大數據研究院、華中師范大學心理學院、Knewton公司、芥末堆。
















 京公網安備 11010502049343號
京公網安備 11010502049343號