


前段時間跟候選人聊天,一個有多年工作經驗的資深 iOS 工程師告訴我,他最近正在學習 Machine Learning 相關的知識。他覺得,對于程序員來說,技術進步大大超過世人的想象,如果你不跟隨時代進步,就會落后于時代。
我其實已經聽過很多人跟我說過類似的話。只不過不同人嘴里提到的詞匯各有不同——大數據、數據挖掘、機器學習、人工智能…… 這些當前火熱的概念各有不同,又有交叉,總之都是推動我們掌控好海量數據,并從中提取到有價值信息的技術。

程序員對這些技術躍躍欲試,知乎上「深度學習如何入門?」「普通程序員如何向人工智能靠攏?」等問題都有很高的關注度。我們在招聘市場也能夠看到,越來越多的技術候選人在跳槽時會思考,能否從事相關崗位的工作。
從 100offer 平臺上的數據來看,大數據相關職位的面試邀請占比也與日俱增。
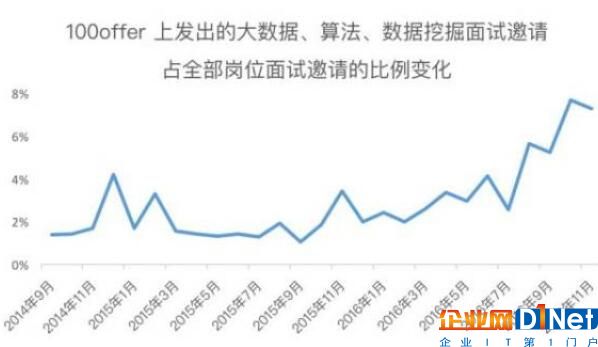
當前,很多候選人對大數據相關崗位的青睞并非偶然
處理器速度的加快,大規模數據處理技術的日漸成熟,讓我們從 Big Data 中快速提取有價值的信息成為可能。幾十年前神經網絡算法被提出之初,捉襟見肘的計算能力很難讓這個計算密集的算法發揮出它應有的作用。而現在,PB 級別的數據也可以在短時間內完成機器學習的模型訓練。這讓格靈深瞳、科大訊飛等高度依賴深度學習的圖像、語音識別公司得以對產品進行快速迭代。
互聯網行業的快速發展,讓不少公司擁有了成千上萬的用戶數據,各家都想挖掘這座儲量豐富的金礦,由此延伸出數據在自家業務不同應用場景中的巨大價值——京東、淘寶等電商網站利用用戶畫像做個性化推薦,PayPal、宜信等互聯網金融公司通過識別高危行為的特征實施風險控制,滴滴、達達等出行、配送業務利用交易數據進行實時定價從而使利潤最大化……
還有一些公司,借助大數據相關技術創造出新的業務模式——比如利用算法做個性化內容推薦的今日頭條、一點資訊,比如通過監測服務整合海量數據、做數據價值變現的 TalkingData,當然還有一些底層架構的支持服務商如阿里云、UCloud 也開通了托管集群、機器學習平臺等服務。
這些企業整體對大數據、數據挖掘相關人才的需求非常之大,導致行業內人才的供給相對不足。因而薪資通常也相對高一些。
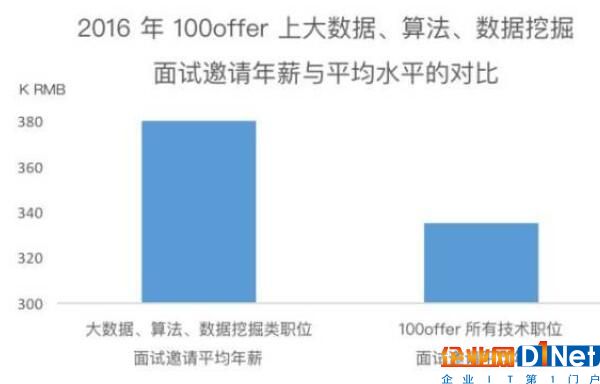
再加上這些崗位相比于傳統的軟件工程,有更高的挑戰空間和更大的難度,自然引得更多人才進入到這個領域。
最近,為了了解大數據相關工程師的招聘現狀,我們走訪了幾家緊需大數據相關人才的公司,與他們的技術 Leader 聊了聊相關人才的招聘現狀。
對于工程師來說,可以考慮的大數據相關崗位有哪些?
從各家招聘的工程師來看,與大數據打交道的核心工程師通常分為這么兩大類
大數據平臺/開發工程師
他們的工作重心在于數據的收集、存儲、管理與處理。
通常比較偏底層基礎架構的開發和維護,需要這些工程師對 Hadoop/Spark 生態有比較清晰的認識,懂分布式集群的開發和維護。熟悉 NoSQL,了解 ETL,了解數據倉庫的構建,還可能接觸機器學習平臺等平臺搭建。
有些大數據開發工程師做的工作可能也會偏重于應用層,將算法工程師訓練好的模型在邏輯應用層進行實現,不過有些公司會將此類工程師歸入軟件開發團隊而非大數據團隊。
算法&數據挖掘工程師
此類工程師的工作重心在于數據的價值挖掘。
他們通常利用算法、機器學習等手段,從海量數據中挖掘出有價值的信息,或者解決業務上的問題。雖然技能構成類似,但是在不同團隊中,因為面對的業務場景不同,對算法 & 數據挖掘工程師需要的技能有不同側重點。因而這個類目下還可細分為兩個子類:
a. 算法工程師
這類團隊面對的問題通常是明確而又有更高難度的,比如人臉識別、比如在線支付的風險攔截。這些問題經過了清晰的定義和高度的抽象,本身又存在足夠的難度,需要工程師在所研究的問題上有足夠的專注力,對相關的算法有足夠深度的了解,才能夠把模型調到極致,進而解決問題。這類工程師的 Title 一般是「算法工程師」。
b. 數據挖掘工程師
有的團隊面對的挑戰不限于某一個具體問題,而在于如何將復雜的業務邏輯轉化為算法、模型問題,從而利用海量數據解決這個問題。這類問題不需要工程師在算法上探索得足夠深入,但是需要足夠的廣度和交叉技能。他們需要了解常見的機器學習算法,并知曉各種算法的利弊。同時他們也要有迅速理解業務的能力,知曉數據的來源、去向和處理的過程,并對數據有高度的敏感性。這類工程師的 Title 以「數據挖掘工程師」居多。
從技術 Leader 對人才的要求看,轉崗機會在哪里?
沒有一個技術 Leader 不希望自己手下是一班虎將。他們期盼團隊中每個工程師都是能獨當一面的全才。
基礎的邏輯、英文等素質是必須的,聰明、學習能力強是未來成長空間的保障,計算機基礎需要扎實,最好做過大規模集群的開發和調優,會數據處理,還熟悉聚類、分類、推薦、NLP、神經網絡等各種常見算法,如果還實現過、優化過上層的數據應用就更好了……
嗯,以上就是技術 Leader 心中完美的大數據相關候選人形象。
但是,如果都以盡善盡美的標準進行招聘的話,恐怕沒幾個團隊能夠招到人。現在大數據、數據挖掘火起來本身就沒幾年,如果想招到一個有多年經驗的全才,難度不是一般的高。在這點上,各位技術 Leader 都有清晰的認識。
不過,全才難招,并不代表 Leader 會放低招聘要求。他們絕不容忍整個團隊的戰斗力受到影響。面對招聘難題,他們會有一些對應的措施——
1. 可以不求全才,但要求團隊成員各有所長,整體可形成配合
剛剛提到了,要想為大數據相關崗位找到一個各方面條件都不錯的人才,難度非常大。因而技術 Leader 會更加務實地去招聘「更適合的人」——針對不同崗位吸收具有不同特長的人才。
以格靈深瞳為例,這是一家計算機視覺領域的大數據公司,團隊中既需要對算法進行過透徹研究的人才,把圖像識別有關算法模型調整到極致,也需要工程實力比較強的人才,將訓練好的算法模型在產品中進行高性能的實現,或者幫助團隊搭建一整套視頻圖像數據采集、標注、機器學習、自動化測試、產品實現的平臺。
對于前一種工程師,他需要在深度學習算法甚至于在計算視覺領域都有過深入的研究,編程能力可以稍弱一些;而對于后一種工程師,如果他擁有強悍的工程能力,即使沒有在深度學習算法上進行過深入研究,也可以很快接手對應的工作。這兩種人才需在工作中進行密切的配合,共同推動公司產品的產出與優化。
即使在算法工程師團隊內部,不同成員之間的技能側重點也可能各不相同。
比如個性化內容推薦資訊平臺——一點資訊的算法團隊中,一部分工程師會專注于核心算法問題的研究,對解決一個非常明確的問題(比如通過語義分析進行文章分類的問題,如何判斷「標題黨」的問題等等),他們需要有足夠深度的了解;另外一部分工程師,則專注于算法模型在產品中的應用,他們應該對業務非常有 sense,具備強悍的分析能力,能夠從復雜的業務問題中理出頭緒,將業務問題抽象為算法問題,并利用合適的模型去解決。兩者一個偏重于核心算法的研究,一個偏重業務分析與實現,工作中互為補充,共同優化個性化內容推薦的體驗。
對于后者來說,因為對核心算法能力要求沒有前者那么高,更重視代碼能力與業務 sense,因而這個團隊可以包容背景更豐富的人才,比如已經補充過算法知識的普通工程師,以及在研究生階段對算法有一些了解的應屆生。
雇主對大數據相關候選人的經驗、背景有更大接受空間,這就給了非大數據相關候選人進入大數據、算法團隊的機會。此時,梳理清楚自己現有技能對于新團隊的價值非常重要,這是促使新團隊決定吸收自己的關鍵。
現在在云計算服務商 UCloud 工作的宋翔,過去四五年一直致力于計算機底層系統的研究。在百度,他曾經為深度學習算法提供支持,用硬件和底層系統優化,加快機器學習算法的運算速度。進入 UCloud 之初,宋翔主要研究的方向也是如何利用 GPU 服務器進行運算加速。
后來,考慮到越來越多企業依賴機器學習進行數據挖掘,UCloud 期望推出一個兼容主流開源機器學習系統的 Paas,使得使用這個機器學習平臺的工程師能夠專注于模型訓練本身,而無需考慮模型部署、系統性能、擴展性、計算資源等問題。
宋翔在底層系統優化上的特長剛好可以在這項工作中發揮,因而他立刻被賦予主導這個平臺搭建的任務。
讓算法在機器上運轉得夠快,才能夠縮短模型迭代的時間,加速模型優化的過程。大部分算法工程師可能對此了解甚少,但是宋翔可以充分發揮自己的特長,利用硬件和底層系統加速機器學習算法。
當需要訓練的數據量特別大的時候,比如幾十 T 以上甚至 PB 級的時候,在分布式系統中, I/O 或者網絡可能成為瓶頸了,這時需要系統工程師的介入,看怎么優化數據傳輸使得 I/O 的使用率提高;看怎么去存儲,用 HDFS 還是用 Key Value Store 或者其他存儲方式,可以讓你更快地拿到數據去計算,或者你用磁盤的存儲還是 SSD 存儲 或者 in-memory 的存儲。這其中,系統工程師也需要平衡成本和效率之間的關系。系統工程師還可以幫助你設計一個系統,讓算法工程師快速地提交任務,或者方便地同時訓練多個模型,嘗試多個參數。系統工程師非常擅長把本來串行的工作拆分之后變成并行工作。比如可以把數據預處理和深度學習運算做一個并發,等等。除了對底層系統有深入了解之外,他現在也在了解機器學習的算法。他帶領的小團隊中,除了有2名系統工程師之外,還有兩名算法工程師,他一直鼓勵兩種工程師互相學習,共同提高,這樣才能夠讓整個團隊效率最大化。如果系統工程師對算法不了解的話,可能也不知道怎么去優化算法運行的效率;算法工程師也應大概了解不同模型在CPU、GPU機器上的運算速度,幫助自己設計出更高效的算法。
對于期望轉崗為大數據相關的普通工程師來說,一旦通過自身擅長的技能切入新團隊之后,就有了更多橫向發展的機會,幫助自己在大數據相關領域建立更強競爭力。
2. 相比于苛求當前技能水平,更看重扎實的基礎和成長空間
無論何種工程師,雇主都希望人才具備綜合素質,而非片面苛求當前的技能水平。特別是對于當前市場供給偏少的大數據相關領域,已經在大數據、算法方面有所建樹的人才畢竟只占少數。具備不錯的基礎素養,并擁有巨大潛力的工程師也很受企業青睞。這些工程師可以利用已有的工程實力完成一部分基礎工作,并在經過1-2年的鍛煉之后,接手更復雜的問題。
我們可以把大數據相關工程師能力模型抽象為以下的核心技能金字塔
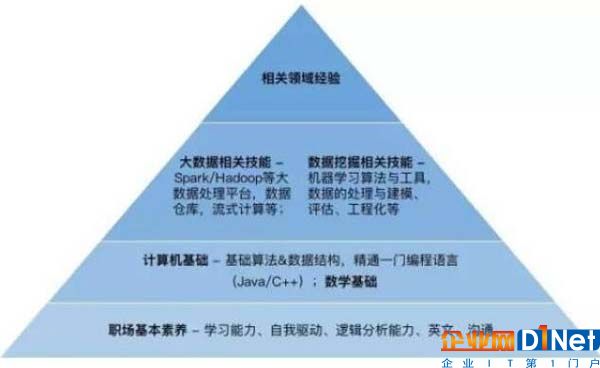
越是偏金字塔底部的素養,對于企業來說越是重要。最底部的基礎素養,代表的是未來的成長空間。當前互聯網高速發展,每家企業都是跑步前進,如果一個當前技能不錯的工程師,未來成長空間有限,也可能變成企業的負擔。
再上一層的計算機基礎 – 基本的算法與數據結構,某一門編程語言的精通,是幾乎每個工程師崗位都重視的能力。一個基礎不扎實的程序員,可能會讓企業懷疑其學習能力。扎實的基礎,會為應用技能的學習掃除障礙,更容易建立深度的理解;而數學基礎對于算法理解上的幫助十分重要。
這最下方的兩層構成了一個工程師人才的基礎素養。如果底層的基礎比較扎實,掌握應用層技能所需要的時間也許比我們預想的要少一些。
格靈深瞳技術副總裁 – 鄧亞峰提到:
對于計算機視覺領域算法工程師,我們當然希望招募無論在基礎層面還是應用層面,技能都完備的候選人。但是如果你算法、數據結構比較強,編程語言上對 C++ 比較理解,那你在應用層的學習上,可能會比其他人快很多。比如在深度學習上付出 1-2 年的時間,在圖像 domain knowledge 上付出半年到一年就可以有基礎的了解。其實現在計算機視覺領域更加依靠深度學習之后,特征選取等依賴 domain knowledge 的門檻已經降下來了,因而我曾見到不少有很好基礎的人,包括一些基礎扎實的應屆生,在圖像領域工作了半年到一年之后就能拿到不錯的成績。在看待大數據工程師的招聘上,TalkingData 的技術 VP 閆志濤和首席數據科學家張夏天也提到:
TalkingData 的大數據工程師工作中非常依賴 Spark 技能,但是了解 Spark 本身并沒有那么難,因而候選人的 Spark 技能對我而言并不是最強吸引點。相比于對 Spark 了解更多的人,我更愿意招收那些 Java 學得好的人。因為 Spark 的接口學習起來相對容易,但是要想精通 Java 是一件很難的事情。如果你把 Java 或者 C++ 學透了,你對計算機技術的認識是不一樣的。這其實是道和術的問題。TalkingData 的 兩位 Leader 也為我舉了一個自家團隊中的例子:
他們在14年招收了一位專科學校畢業的工程師,在上一家公司做過一點推薦算法,會寫 Hadoop Mapreduce,但是并沒有在大數據上有深入的研究。這位工程師當時的大數據技能并不能達到 TalkingData 的招聘標準,不過好在他思維清晰,看待問題有自己獨特的想法。加之 Java 基礎不錯,在上一家公司做事情也很扎實,所以就招聘進來了。
說到這里,兩位 Leader 坦言「當時幸好還不怎么挑簡歷,也許按照后來的標準未必能把這位工程師招聘進來。
不曾想到,這位工程師主動性非常強,Leader 只需給到工作方向,他就會驅動自己學習相關知識,快速完成目標。2年以后,這位工程師的 Spark 能力已經鍛煉得非常強悍,用 Leader 的話說「可以以一當十」;他對大數據、機器學習都有濃厚的興趣,Spark 基礎夯實之后,又轉崗到了算法工程師團隊,寫出了 TalkingData 機器學習平臺的核心代碼,這個平臺大大提高了團隊的機器學習效率。
從上邊的例子中,我們也可以額外收獲一個信息,相比于跳槽轉崗,內部轉崗會更容易一些。因為在公司內部中,企業有充分的時間考察工程師的能力、潛力。企業對工程師的認可度提升之后,才會更加放心的予以新的挑戰。
趙平是宜信技術研發中心的一位工程師,加入宜信之前,他曾幫助中國移動機頂盒業務的后端架構進行服務化轉型。抱著對基礎平臺架構的濃厚興趣,趙平加入了宜信。他在這家公司做的第一個項目是分布式存儲系統的設計和開發。第一個項目完美收官之后,他的學習能力、基礎能力備受褒獎。當宜信開始組建大數據平臺團隊時,趙平看到了自己理想的職業發展方向并提交了轉崗申請,基于他過往的優異表現,順利地拿到了這個工作機會。
轉崗之后,趙平也遇到了一些挑戰,比如大數據涉及的知識點、需要用到的工具更加豐富,Spark,Scala,HBase,MongoDB…,數不清的技能都需要邊用邊學,持續惡補;比如思維方式上,需要從原來的定時數據處理思維向 Spark 所代表的流式實時處理思維轉變。不過基于他扎實的基礎,以及之前做分布式存儲系統經驗的平滑過渡,加之整個團隊中良好技術氛圍的協助,最終順利完成第一個大數據項目的開發工作。
對希望轉做大數據相關工作的普通工程師,一些中肯的建議
在文章的末尾,我們基于文章中提到的多個案例,總結一下幫助普通工程師走向大數據相關崗位的幾個 tips 吧:
重視基礎。無論各種崗位,基礎是成長的基石。發揮專長。從能夠發揮自己現有專長的崗位做起,可以讓新團隊更歡迎你的加入。比如算法模型的工程化,偏重于業務的數據挖掘,大數據平臺開發,機器學習系統開發等等,這些工作對于普通工程師更容易上手。而普通工程師直接轉偏研究方向的算法工程師,難度更高。準備充分。請預先做好相關知識的學習,有動手實踐更佳。如果沒有一點準備,雇主如何相信你對這個領域真的有興趣呢?考慮同公司轉崗。在同公司轉崗阻力更小。亦可考慮加入一家重視大數據的公司,再轉崗。最后,如果你確實對大數據、數據挖掘有濃厚興趣,最好的辦法是立刻開始實踐。也許你不會以此為職業,但是可以多一技傍身。
也許,未來這些技能對于程序員而言,就好比現在 MS Office 對于職場人一樣普遍。








 京公網安備 11010502049343號
京公網安備 11010502049343號