


為什么要為時間序列來建立專門的數據庫?明明我們就有很多方法來處理時序數據,例如在SQL數據庫中通過時間列的排序來解決或者是選擇Cassandra這樣的分布式數據庫。但是,這些方法雖然能夠解決時序數據的問題,但是卻需要進行大量的工作,十分耗時。那么怎么才能更好的解決時序數據呢?
首先,我們先來看一下時序數據的種類:常規和不規則。
開發人員比較常見和熟悉的是常規時間序列,它只在規定的時間間隔內進行測量,如每10秒鐘一次,通常會發生在傳感器中,定期讀取數據。常規時間序列代表了一些基本的原始事件流或分發。
不規則時間序列則對應離散事件,主要是針對API,例如股票交易。如果要以1分鐘間隔計算API的平均響應時間,可以聚合各個請求以生成常規時間序列。
現代TSDB需要能夠處理常規和不規則的事件和度量,它們要有通用的元數據來描述用戶可能要查詢的東西。例如主機名,應用程序,區域,傳感器ID,建筑物,股票名稱,投資組合名稱或者是其它任何維度的數據。時間序列添加元數據要允許客戶切片,并創建摘要。
時間序列應用與規模
時序數據庫與其他數據庫用例和工作負載的區別。
時間序列數據專注于快速攝取。也就是說,時序數據庫需要經常插入新數據。使用傳感器數據用例時,我們常常會發現滯后的數據收集,這時也要將數據附加進行。
高精度數據保存時間較短,中等或更低精度的摘要數據保留時間較長。這也意味著用戶必須不斷從數據庫中刪除數據。這是一個非常不同于正常數據庫設計來處理的工作量。
代理或數據庫本身必須連續計算來自高精度數據的摘要以進行長期存儲。這些計算既包括一些簡單的聚合,同時也有一些復雜計算。
時間序列的查詢模式可能與其他數據庫工作負載有很大的不同。在大多數情況下,查詢是在所請求的時間范圍內提取一段數據。但對于即時計算聚合和縮減樣本的數據庫,常常會流失很多數據,所以快速迭代數據來計算聚合對于時間序列用例至關重要。
使用SQL數據庫時間序列的問題
許多用戶在使用時間序列之前,是將其數據存儲在常見的SQL RDBMS(如PostgreSQL或MySQL)中。一般來說,短期內還是可以滿足需求的,但隨著數據規模的增加,事情就開始失控了。

結論:關系型數據庫不是為了解決具體的時間序列問題而設計的,所以試圖讓他們解決問題是不現實的。
基于分布式數據庫
與SQL變體一樣,在類似Cassandra的分布式數據庫之上構建時間序列解決方案需要相當多的應用級代碼。
首先,需要決定如何構建數據。Cassandra中的行被存儲在一個復制組,這意味著需要考慮如何構造行鍵,以確保集群得到正確利用。之后還需要編寫應用程序邏輯來對時間序列用例進行其他查詢處理。然后,編寫采樣邏輯來處理創建可用于長期可視化的較低精度樣本。最后,在查詢不同維度的許多時間序列和計算聚合時,需要確保查詢性能。
結論:編寫所有這些應用程序代碼通常需要有能力的后端工程師進行幾個月的時間。
為什么要建立一個時間序列數據平臺?
減輕開發者的工作
我們經常會看到開發者不斷編寫代碼來解決相同的問題,如果我們將其引入到平臺或者是數據庫中,開發者的代碼量就會減少,解決問題的時間就會被優化。
時間是特殊的
除了可用性目標之外,我們還可以圍繞時間序列的特性進行一些數據庫的優化,例如,在插入時聚合和縮小樣本,在用戶想要釋放空間時自動排除高精度數據。甚至還可以構建針對時間序列數據進行優化的壓縮。
超越數據庫,使開發更容易
專為時序數據構建數據庫的一個優點就是它可以超越數據庫。我們發現大多數用戶遇到了一系列需要解決的問題,如何收集數據,如何存儲數據,如何處理和監視數據,以及如何可視化。
使用通用API可以使社區更容易的構建解決方案。用 line protocol來表示時間序列數據,用于寫入和查詢的HTTP API,以及用于處理的Kapacitor……隨著時間的推移,我們可以對常見的用例來預先構建組件。
主流的時間序列數據庫
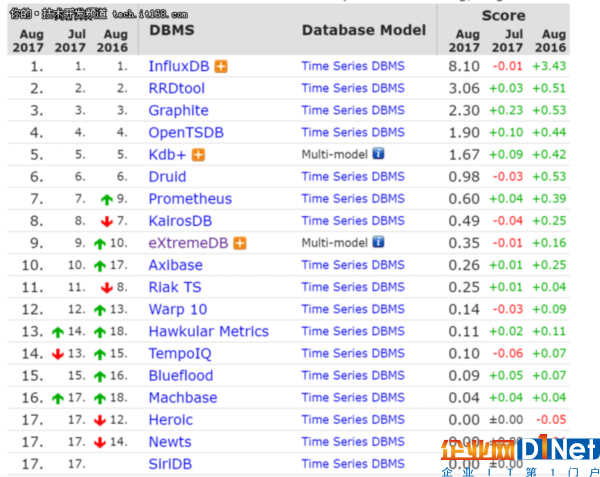
前文對于時間序列數據庫解釋了那么多,最后我們就來看看主流的時間序列數據庫有哪些?根據DB-Engines排行榜,在300多個數據庫中,時間序列數據庫共有17個,但可惜的是目前市場份額還是有點低。








 京公網安備 11010502049343號
京公網安備 11010502049343號