


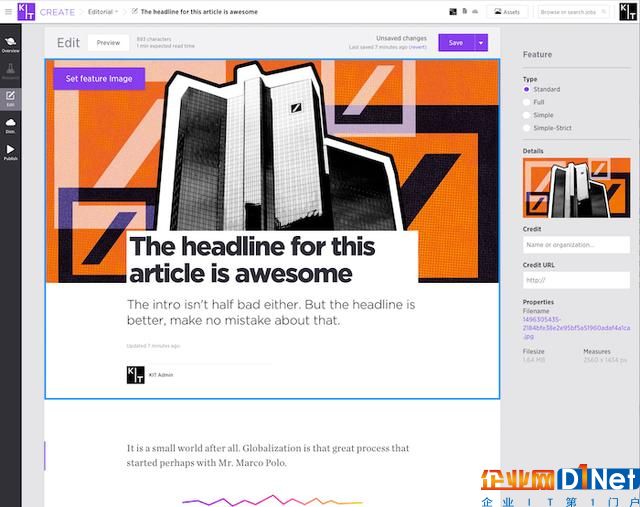
每當瑞典創業公司Kit的員工開始制作故事時——無論是Facebook上的美食類視頻,還是Kit網站上關于燃煤發電廠的一段文字介紹——他們都必須填入17個類別的元數據,使公司可以對故事進行分類。
這些數據點包含145個不同分類(總共可能產生430億種組合),例如故事的基調(故事是否有趣?)和故事的意圖(故事是為了讓讀者感到驚訝,還是希望向讀者解釋什么?)。
基于故事形式和發布平臺,對于每個故事,Kit也會收集200多個不同的數據輸出點,包括讀者在頁面上花費的時間、滾動的深度、觸達率和參與度等等。
Kit聯合創始人、產品副總裁弗雷德里克·斯特羅姆伯格(Fredrik Stromberg)表示,收集所有這些信息的目的是開發“Kit核心”。這是一種對編輯內容的分類,并且可以幫助該公司更全面地了解,什么樣的故事能取得成功。
他表示:“我們正在這努力建設整個過程的編輯部分。許多由數據驅動的編輯團隊都在關注這個問題:我們想要寫些什么?這里存在大量數據挖掘、數據分析和文本分析引擎。它們會關注內容本身,得出的結論包括:更短一些才好,或者你應該在這里插入7張圖片。我們試圖在‘什么’和‘這會造成什么’之間找到合適的空間。我能否以這種結構化的方式來創建編輯任務,而他人可以接受這些任務并知道如何去做?”
這就是“故事引擎”的核心,這一內容管理系統(CMS)參與了Kit編輯過程的各個方面,無論是故事構思,還是創作、出版和發行。Kit是一家多平臺發行商。無論最終發布平臺是什么,內容都會來自故事引擎,并由故事引擎去發布。這使得Kit可以以更精確的方式去分類故事,并針對每個平臺優化內容。
斯特羅姆伯格常常會舉的一個例子是,假設在地中海沿岸發生了兩起船舶事故。其中一場涉及12名試圖前往意大利的敘利亞難民,而另一場則涉及直布羅陀海岸附近的12名英國游客。盡管這兩個故事都可以被定義為事故,但卻是全然不同的兩種故事。
他表示:“這將造成我們報道方式的不同,盡管以機器分析方式來看,兩者是一樣的。與此同時,奧運會和諾貝爾和平獎頒獎典禮的報道可能完全相同。我們正在努力弄明白,如何以最佳方式去講故事,這是個大膽的目標。”
該公司利用了員工輸入的元數據,并分析用戶如何在不同平臺上消費不同類型的故事和內容。
Kit聯合創始人及CEO皮德·伯尼爾(Peder Bonnier)表示:“通常,你會在CMS中看到故事,無論是視頻、文章,還是圖片。你會用Javascript腳本或谷歌(微博)Analytics工具來分析故事的表現。隨后,你會有一系列與這條故事相關的分發項目,例如Facebook帖子、Twitter消息或Instagram內容。以系統性的方式將這些關聯在一起很困難,你能做出的最佳判斷或許是:我們最好在周四將它發布至Facebook。然而,我們在同一系統中去做所有這些工作。我們創建工作,將其分類,隨后創建一系列分發項目,并再次分類。這意味著我們可以這樣說:如果你希望獲得大量用戶參與,那么應當以這樣的方式去制作。”
Kit創立于2014年,創始團隊包括伯尼爾、斯特羅姆伯格,以及現任總編輯羅伯特·布蘭斯特羅姆(Robert Brannstrom)。該公司于2015年春季開始發行內容,目前有30名員工,其中一半屬于編輯團隊。
該公司獲得了來自媒體巨頭Bonnier旗下風投部門Bonnier Growth Media的5000萬瑞典克朗(約合570萬美元)投資。
伯尼爾表示:“我們的業務完全基于如何以最佳方式講述特定的故事,并將這樣的信息賣給廣告主。”
網站編輯被鼓勵進行各種實驗,因此Kit可以看看,不同類型的故事都有什么樣的表現,并繼續開發新的內容形式。例如,關于美食類視頻,以往講故事的順序是先概述所有食材,隨后才介紹如何制作一道菜。然而目前,編輯決定去除對食材的介紹,直接講述如何做菜。








 京公網安備 11010502049343號
京公網安備 11010502049343號