


在談到開源人工智能項目時,人們通常會想到Google TensorFlow、PyTorch等模型框架項目,由于模型框架是訓練人工智能模型的關鍵組成部分,因此這些項目通常最受關注。但是人工智能并不是一種單一的技術,而是一個復雜的技術領域,涉及多個子領域和許多不同的組成部分。
向人工智能轉型的轉折點
一般而言,技術升級的轉折點是其回報遠遠超出成本。當將其應用于人工智能轉型時,它將涉及一些基本因素,其中包括模型(算法)、模型推斷和數據服務。
在談論模型時,人們需要了解利用人工智能技術的期望值。如果希望采用人工智能技術來擊敗和取代人類,例如采用人工智能驅動的對話機器人取代所有的客戶支持專家,那么對人工智能模型的需求將相當高,并且在短期內無法實現。
如果企業想讓客戶支持專家從單調繁瑣的日常工作中解脫出來,這意味著計劃利用人工智能技術提高人類的生產力和能力,那么現在的模型在許多情況下都能實現。
這聽起來令人鼓舞。但是關于模型的激烈爭論是,盡管一些模型可供使用,但卻沒有一個最佳的模型。那些雇傭人工智能科學家擁有這些技術發展水平(SOTA)模型的公司。如果只使用公共模型,那么會失去競爭優勢嗎?人們對此感到困惑,因為他們認為效率更高的模型會帶來更高的業務價值,但這種想法可能是錯誤的。在大多數情況下,模型有效性與商業價值之間的關系既不是線性的,也不是單調遞增的。這一函數的圖形如下所示。
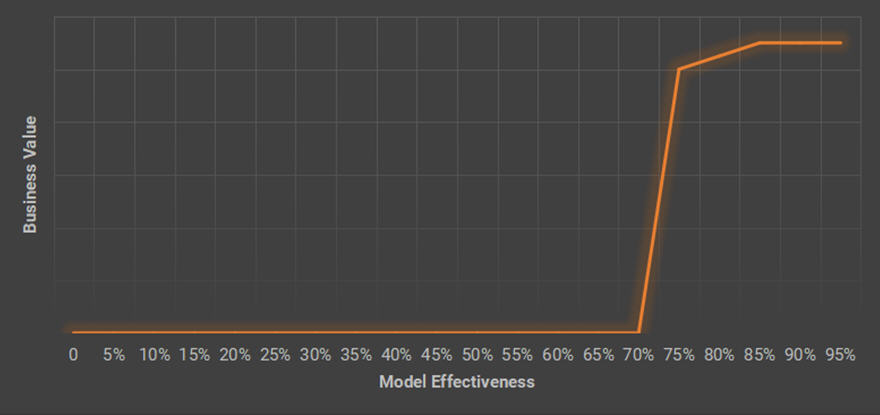
這是一個分段函數。在第一階段,在該模型在應用程序場景中實現實用之前,沒有任何業務價值。在第二階段,盡管理論上更好的模型應該具有更好的性能(響應時間和有效性等),但在實際場景中它可能并不那么明顯。以下進行一下了解。
在醫生確認患者是否患有肺部感染之前,需要對其肺部進行CT檢查,將生成約300張CT圖像。而經驗豐富的醫生將不得不花費5~15分鐘來研究這些CT圖像。在通常情況下,如果治療的患者數量不多不會有什么問題。但是,在極端情況下(例如持續蔓延的冠狀病毒疫情),患者數量激增將讓醫生不堪重負。
一個好消息是,數據科學家致力通過計算機視覺技術幫助醫生。他們訓練的模型可以在幾秒鐘內處理成百上千的CT圖像并提供診斷建議。因此,醫生只需花費1分鐘的時間就可以查看模型生成的結果。因此,在采用機器學習技術之前,醫生平均需要花費10分鐘的時間才能查看一次CT掃描生成的結果,而現在大約需要1分鐘。生產率提高了近90%。
如果有一個更快的模型,只需要3秒鐘就可以生成結果,那會怎么樣?如果有一個更有效的模型可以將準確度從80%提高到90%會怎么樣?醫生檢查的結果會更少嗎?其答案是否定的,這是因為該模型中,如果十分之一將會出錯,但并不知道哪個是錯誤的,醫生必須審查所有結果。因此不會節省更多的診斷時間。
此外,為了降低模型推理服務的成本,有時需要犧牲模型有效性。例如一個擁有5500萬張商標圖片的商業智能平臺提供商,該公司希望提供一項服務,允許用戶搜索這些商標的所有者。用戶通過上傳商標圖像作為輸入查詢而不是給出關鍵字來執行搜索。
其背后的技術是計算機視覺,例如VGG模型。如果企業在后端服務器上運行模型推理,則必須分配和預留數據中心的硬件資源。另一個選擇是部署一個規模更小的模型,這樣企業就可以把模型推理放在邊緣計算設備上(大多數情況下是智能手機)。它肯定會降低像GPU這樣昂貴的模型推理硬件的成本。這是另一個例子,SOTA模型不可能在所有場景中都具有競爭力。
人們已經處在人工智能轉型的轉折點。接下來的問題是,如何走過這一轉折點,并采用人工智能技術來增強業務能力。
可用模型是先決條件。但是,如果只具有模型,也無法輕松開發人工智能程序。像傳統應用程序一樣,數據服務始終是至關重要的部分。可以看到,它已成為當今采用人工智能的重要組成部分。這就是為什么啟動開源項目Milvus來加速采用人工智能的原因。
采用人工智能的數據挑戰
一些企業嘗試通過人工智能技術處理的大多數數據都是非結構化的,因此期望Milvus項目為非結構化數據服務提供堅實的基礎。
人們通常將數據分為結構化數據、半結構化數據、非結構化數據這三種。結構化數據包括數字、日期、字符串等。半結構化數據通常包括特定格式的文本信息,例如各種計算機系統日志。非結構化數據包括圖片、視頻、語音、自然語言和任何其他不能由計算機直接處理的數據。
據估計,非結構化數據至少占數字數據世界的80%。例如,人們可能每天與其家人、朋友或同事發送和接收數kB的短信。但即使只在移動設備上拍一張照片,例如采用具有1200萬像素的攝像頭iPhone 11,一張照片高達幾兆字節。那么如果拍攝720p分辨率的視頻呢?
一些企業開發了關系數據庫、大數據等技術來高效地處理結構化數據。而半結構化數據可以通過基于文本的搜索引擎Lucene、Solr、Elastic search等進行處理,但是對于大量的非結構化數據,在以往并沒有有效的分析方法。直到深度學習技術在近年來興起,非結構化數據處理技術得到了快速的發展。
非結構化數據服務
嵌入是深度學習的一個術語,是指通過模型將非結構化數據轉換為特征向量。由于特征向量是數字數組,因此很容易由計算機處理。因此,非結構化數據的分析可以轉換為矢量計算。
一個最普遍的論點是特征向量似乎是非結構化數據處理的中間結果。那么是否有必要建立通用的矢量相似度搜索引擎?是否應將其包括在模型中?
專家認為,特征向量不僅僅是中間結果。它是深度學習場景中非結構化數據的知識表示。這也稱為特征學習。
另一個論點是,由于特征向量還包含數值,為什么不對現有的數據處理平臺(例如數據庫)或計算框架(例如Spark)執行向量計算。
確切地說,向量由數字列表組成。這導致矢量計算和數值運算之間的兩個重大區別。
首先,向量和數字最頻繁的運算是不同的。對于數字來說,加減乘除是最常見的運算。但是對于向量,最常見的要求是計算相似度。人們會看到,在這里給出了計算歐幾里德距離的公式,向量的計算比普通的數值計算要高得多。
其次,數據的索引組織不同。在兩個數字之間,可以互相比較數值。這樣就可以像B樹那樣根據算法來創建數字索引。但是在兩個向量之間,無法進行比較。只能計算它們之間的相似性。因此矢量索引通常是基于近似最近鄰神經網絡算法。
由于這些顯著的差異,傳統的數據庫和大數據技術很難滿足矢量分析的要求。他們支持的算法和他們關注的場景都是不同的。
版權聲明:本文為企業網D1Net編譯,轉載需注明出處為:企業網D1Net,如果不注明出處,企業網D1Net將保留追究其法律責任的權利。








 京公網安備 11010502049343號
京公網安備 11010502049343號