


瘦弱的身材,安靜的性格,戴著一副厚厚的眼鏡,你絕對猜不到如此其貌不揚的Quoc Le,正式引領(lǐng)人工智能革命的領(lǐng)軍人物之一。
2011年,Le和他的博士生導(dǎo)師Andrew Ng、谷歌同時Jeff Dean和谷歌研究員Greg Corrado,共同創(chuàng)建了谷歌大腦(Google Brain)。目標(biāo)是在谷歌龐大的數(shù)據(jù)背景下探索深度學(xué)習(xí)。在此之前,Le在斯坦福大學(xué)開展了一些關(guān)于無監(jiān)督深度學(xué)習(xí)的開創(chuàng)性工作。
2012年,Le在ICML上發(fā)表了一篇文章,引起了人們對深度學(xué)習(xí)的濃厚興趣:他開發(fā)了一種深度神經(jīng)網(wǎng)絡(luò)模型,可以根據(jù)Youtube上的1000萬張數(shù)字圖像以及ImageNet數(shù)據(jù)集中的3000多個對象來識別貓。這個巨型系統(tǒng)由16000臺機器和10億個突觸組成,是以往研究規(guī)模的100倍。同年,Le又發(fā)表了關(guān)于AlexNet的論文,對整個深度學(xué)習(xí)領(lǐng)域產(chǎn)生了牽引力。
雖然后來證明無監(jiān)督學(xué)習(xí)方法對于商業(yè)用途是不切實際的(至少在那段時間),但Le在2015年《Wired》采訪中表示,“如果我們能挖掘一種算法來解決這個問題就太好不過了,因為實際的情況是,我們無標(biāo)記的數(shù)據(jù)遠遠多于有標(biāo)記的數(shù)據(jù)。”
從“序列”到“序列學(xué)習(xí)”
Le在2013年畢業(yè)后正式加入谷歌,成為一名研究科學(xué)家,很快就在機器翻譯領(lǐng)域取得了驚人的突破(機器翻譯是機器學(xué)習(xí)領(lǐng)域最活躍的研究領(lǐng)域之一)。
為了實現(xiàn)這一結(jié)果,他必須超越已有深度學(xué)習(xí)的方法,這些方法適用于圖像和語音,可以使用固定大小的輸入進行分析。 而對于自然語言,句子的長度各不相同,詞語的順序也很重要。
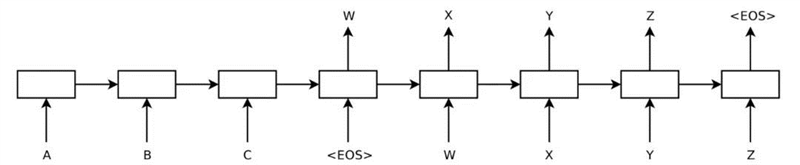
2014年,Le與谷歌研究人員Ilya Sutskever和Oriol Vinyals一起提出了序列到序列(seq2seq)學(xué)習(xí)。它是一個通用的encoder-decoder框架,訓(xùn)練模型將序列從一個域轉(zhuǎn)換到另一個域(例如不同語言之間的句子)。
seq2seq學(xué)習(xí)在工程設(shè)計選擇方面的需求較少,并允許Google翻譯系統(tǒng)高效準(zhǔn)確地處理非常大的數(shù)據(jù)集。 它主要用于機器翻譯系統(tǒng),并被證明適用于更廣泛的任務(wù),包括文本摘要,會話AI和問答。
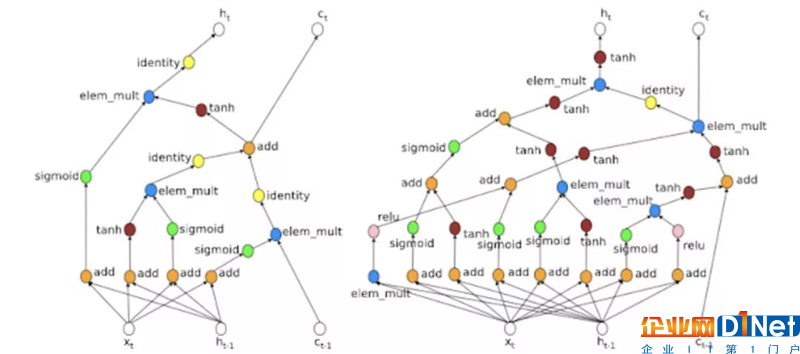
Le進一步發(fā)明了doc2vec,這是一種非監(jiān)督算法,它從句子、段落和文檔等不同長度的文本片段中學(xué)習(xí)固定長度的特征表示。Doc2vec是word2vec的擴展,word2vec于2013年由谷歌成員Tomas Mikolov發(fā)布。其思想是每個單詞都可以用一個向量表示,這個向量可以從集合文本中自動學(xué)習(xí)。Le添加了段落向量,因此模型可以生成文檔的表示形式,從而不考慮文檔的長度。
Le的研究最終得到了回報。在2016年,谷歌宣布了神經(jīng)機器翻譯系統(tǒng),它利用AI進行學(xué)習(xí),能夠得到更好更自然的翻譯。
2015年,Le在榮登MIT Technology Review的“35歲以下創(chuàng)新者”排行榜,因為他的目標(biāo)是“讓軟件變得更智能,幫助人們提高生活品質(zhì)”。
AutoML:神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)自我提升
訓(xùn)練深層神經(jīng)網(wǎng)絡(luò)需要大量的標(biāo)記數(shù)據(jù)和反復(fù)的實驗:選擇一個架構(gòu),構(gòu)建隱含層,并根據(jù)輸出調(diào)整權(quán)重。對于機器學(xué)習(xí)專業(yè)知識有限的人來說,訓(xùn)練過程時既費時又費力的。
2016年,Le和另一位谷歌同事Barret Zoph提出了神經(jīng)結(jié)構(gòu)搜索。他們使用一個循環(huán)網(wǎng)絡(luò)來生成神經(jīng)網(wǎng)絡(luò)的模型描述,并通過強化學(xué)習(xí)來訓(xùn)練這個RNN,以最大限度地提高在驗證集上生成的體系結(jié)構(gòu)的預(yù)期精度。
這種新方法可以幫助研究人員設(shè)計一種新的網(wǎng)絡(luò)體系結(jié)構(gòu),在CIFA-10數(shù)據(jù)集的測試集精度方面與人類發(fā)明的最佳體系結(jié)構(gòu)相匹配。一年后,Le和Zoph將他們的研究提升到了一個新的高度,他們提出了NASNet-A,一個可移植的大型圖像數(shù)據(jù)集架構(gòu)。
Le的研究為AutoML奠定了基礎(chǔ),AutoML是一套谷歌產(chǎn)品,專為缺乏機器學(xué)習(xí)經(jīng)驗和資源的開發(fā)人員設(shè)計的。 然而,在早期階段,AutoML是用于解決現(xiàn)實問題的:數(shù)據(jù)科學(xué)家使用AutoML建立了一個基于面條圖像識別餐廳的模型,準(zhǔn)確度幾乎達到95%; 日本開發(fā)人員使用AutoML構(gòu)建了一個可以使用其品牌名稱對圖像進行分類的模型。
在過去的六年里,Le一直處于深度學(xué)習(xí)發(fā)展的前沿。這位36歲的谷歌研究科學(xué)家現(xiàn)在準(zhǔn)備將深度學(xué)習(xí)提升到一個新的高度。






軍人物 谷歌AutoML幕后的傳奇英雄")

 京公網(wǎng)安備 11010502049343號
京公網(wǎng)安備 11010502049343號