


近日,IDC“CXO卓越圈”在北京召開了“人工智能創造業務價值”的主題沙龍,來自金融、能源、零售、農業、醫療等行業的20位CXO現場參與。大家圍繞AI在企業數字化轉型中的作用和價值、AI應用落地路徑等問題進行了充分討論。
第四范式作為本次沙龍的聯合主辦方,創始人兼CEO戴文淵針對人工智能推動企業數字化轉型發表了自己的看法:隨著人工智能規模化落地,企業在制定AI轉型路線時可考慮“1+N”的應用場景模式,“1”是結合公司核心業務,把1個或幾個對業務影響最大的場景做到極致;“N”是用最高的效率規模化落地盡可能多的應用場景,使場景的總體價值最大化。
以下是戴文淵主題演講全文:
人工智能在今天是一個特別火又特別令人困惑的話題。火是因為被各行各業寄予厚望,困惑是因為目前公眾在新聞媒體上看到更多的AI集中在感知層,例如人臉識別、語音識別、無人車等。但回到我們的企業經營,似乎和無人車這樣的技術完全聯系不到一起去。享受著AI紅利的企業,例如BAT,也沒有哪家是靠人臉識別在經營的。第四范式一直致力于解決的問題,是如何把人工智能技術和各行各業企業的生產、經營能夠結合起來。一個企業、一個組織,通常自上而下分為戰略制定者、策略制定者、策略執行者三種角色。過去20年,互聯網和移動互聯網解決了策略執行的環節。未來的20年,人工智能將會通過改造“策略制定”的環節來提升企業業務。
第四范式的企業愿景是AI For Everyone,我們希望把人工智能技術帶到每一個行業,比如金融、零售、能源、安防、醫療、媒體等,幫助企業去實現智能化轉型。回到企業本身,無論是否使用AI技術,首先我們需要關心的是企業需要提升什么業務價值。
首先,每個企業可能都會有1個或多個核心業務,這些業務提升會帶動整個企業的提升。例如,最近幾年,互聯網應用越來越關心的“千人千面”,本質上是通過個性化服務應用提升客戶活躍度,降低客戶流失率。客戶活躍度的提升,會帶動企業整體的提升。對于零售或制造業企業,提升供應鏈效率,降低成本,也會帶動企業核心競爭力的提升。面對這些核心應用場景,我們需要AI做到“極致的效果”,因為每提升一個百分點的效果,對企業都至關重要。
其次,很多企業也往往面臨場景應用極其分散的情況。例如,大型金融企業,他們的業務往往較為分散。這種情況下,AI的規模化落地,往往比單場景的極致效果對企業更為重要。假設一個企業有一千個場景,其中一個場景提升10倍,對整個企業來說,只有百分之一的提升。而如果我們能高效地完成一千個場景的全面覆蓋,即使每個場景只提升1倍,那也百分之百的提升。所以,面對場景眾多的企業,AI的規模化落地能力是企業智能化轉型的關鍵。
我們習慣把企業的核心場景稱之為“1”,把眾多場景稱之為“N”。通常企業的智能化轉型需要一個“1+N”應用模式。這里需要指出的是,“1”不一定只有一個應用,有些企業可能會有若干個“1”這樣的核心應用,但一定不會很多。
企業的業務一定是和企業的發展目標相關的。例如,我們服務某知名國際零售集團,根據企業的發展目標,將其業務分為“開源”和“節流”兩大類。“開源”的目標主要和客戶相關,包括提升客戶留存率、單客戶價值、平均客戶留存時間等。手段上來說,可能有千人千面的推薦、coupon的營銷等。AI在里面可以通過優化推薦、營銷等環節,提升留存率、單客戶價值等核心指標。“節流”的目標主要是降低中后臺運營的成本和提升運營效率。通過提升供應鏈等環節的效率,降低成本,提升企業的競爭力。這其中,個性化服務、供應鏈是核心應用,是“1”,1個百分點的提升就足以改變企業的競爭格局。而眾多細分場景,如各種單據的OCR、各種場景的語音識別、智能客服、流程機器人等,是“N”,規模化的落地可以提升企業的整體效率。
“1”一定要做到極致的效果,這類標桿型應用對于AI系統的要求較高。一是高維,也就是精細,越高維度的AI,其效果上能做到越精細。過去的專家模型,往往維度(規則數量)在幾個到幾千個不等。傳統意義上的高維模型,往往局限在萬級別的維度以下。第四范式開發的高維機器學習引擎,最高可支持到萬億(10^12)維度,通過極致的機器算力,實現遠超傳統幾個數量級的精準性。二是實時,隨著服務線上化以及對極致體驗的要求,對業務的實時響應要求越來越高。尤其面對高維,我們發現往往過去能做到實時的系統,做不到高維;能做到高維的系統,做不到實時。為此,第四范式自主研發了RTiDB系統,實現萬億維度模型毫秒級響應的精準決策。三是閉環(自學習能力),任何系統都不可能完美,都可能會犯錯。我們更怕的不是AI犯錯誤,而是AI持續不斷地犯同樣的錯誤。因此,持續利用業務應用過程中的反饋數據進行系統自我更新與優化的能力,是未來AI系統極其重要的核心能力。我們也經常發現,AI系統的最大提升,很多時候并不來自于系統上線的那一刻,而是來自于上線以后經年累月的自我迭代提升。

“N”追求的是規模化落地,現在我們服務的很多企業都面臨著“全面AI改造”,在面對1千個甚至1萬個場景時,如果每個都做到極致,代價和效率是不夠的。實現規模化落地和極致效果的路徑不完全一樣。首先需要建立一個統一的方法論,讓更多人用統一方法規模化生產AI。第四范式建立了一個以“庫伯學習圈”理論為基礎的AI方法論,并基于此構建了“先知”平臺,將AI開發分成“行為數據采集、反饋數據采集、模型訓練、模型應用”四個標準步驟,我們幫助客戶和合作伙伴的開發者在先知上按照這樣的一二三四去產生AI。以我們服務的某大型央企為例,其開發者數量眾多,AI開發者卻非常有限,我們為其提供了統一的方法論和平臺,讓開發者針對業務目標,在上面開發各種各樣的AI應用。
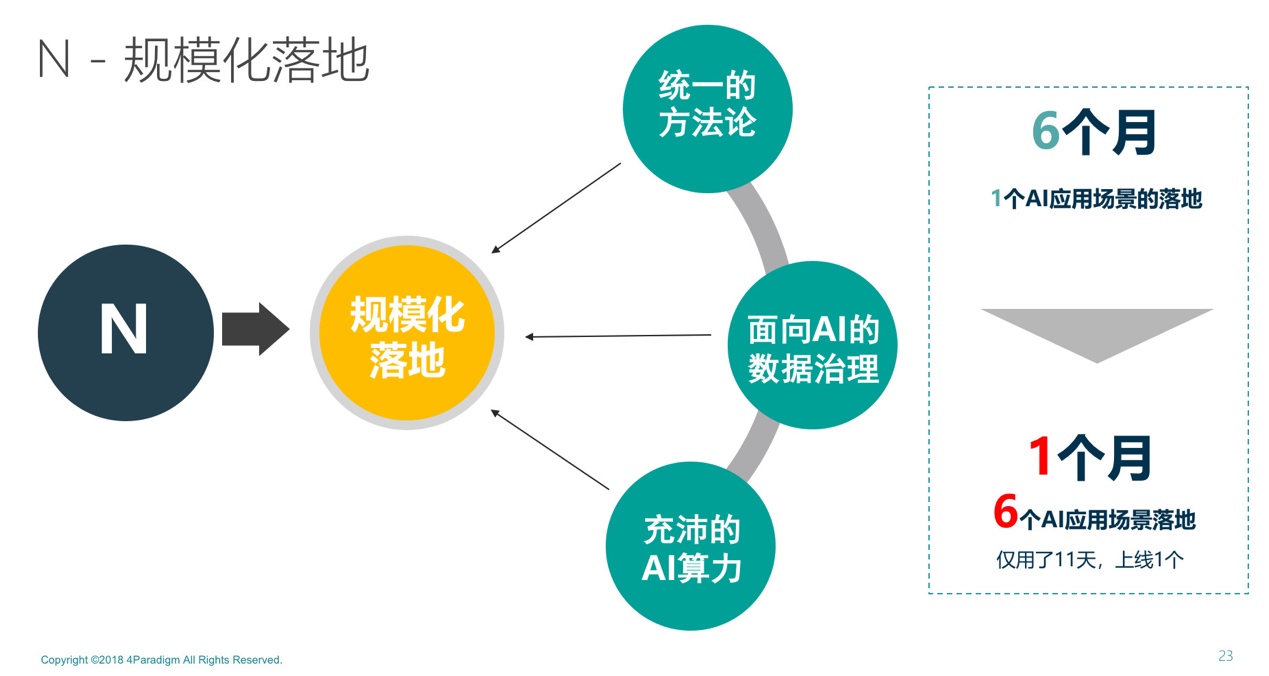
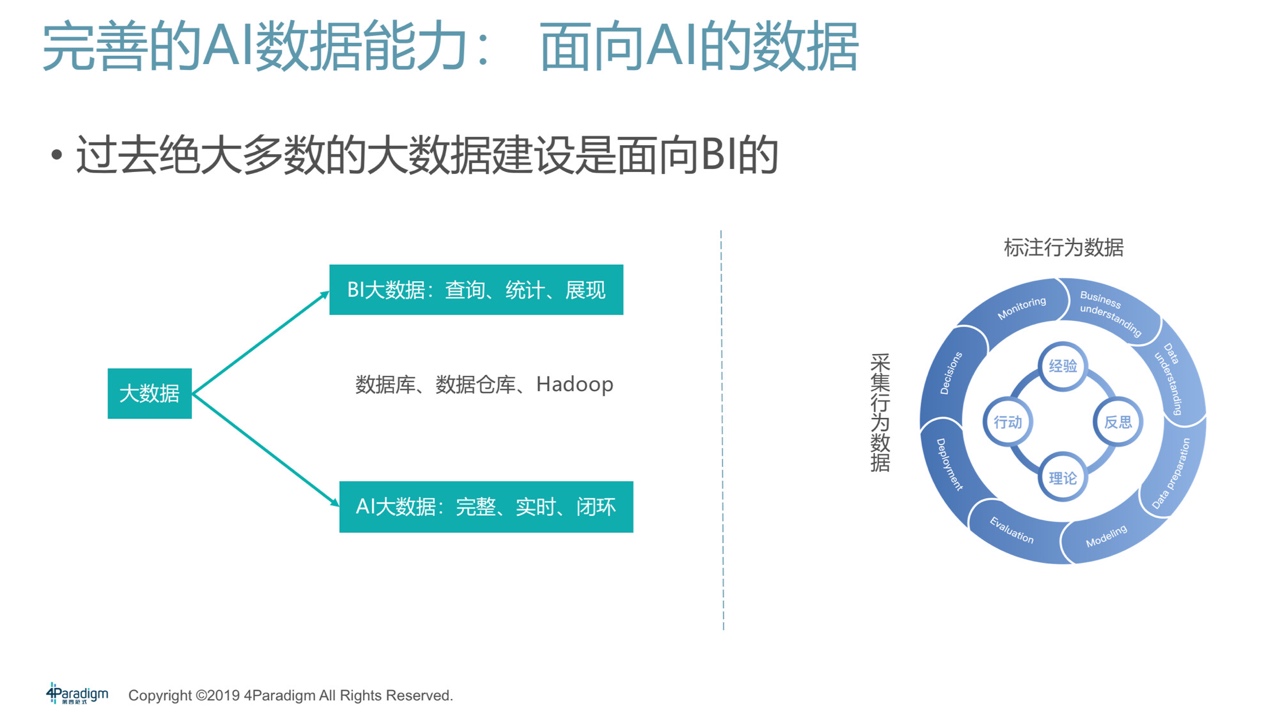
其次,AI規模化應用過程中要有完善的數據治理能力,尤其是對于大中型的企業,數據治理非常重要。可能我們過去已經做了大數據系統,但往往是面向BI建設的,BI大數據主要是幫助人去總結一些經驗,因此更強調查詢、統計、可視化等功能。AI大數據是給機器看的數據,需要的是完整、實時和支持機器自學習的閉環。兩個大數據系統的設計理念天然不同,我們經常會看到企業由于過去建設了面向BI的大數據系統,又將AI建設在這個系統之上,非但沒有幫到AI,反倒成為AI落地的障礙。因此,大規模AI實踐過程中企業需要一套面向AI的數據治理系統,能夠存取PB級甚至更大量的日志、支持實時存儲、形成一個線上數據采集和處理的閉環等。
最后是AI算力,以往大家關注的焦點主要集中在兩個方面:一是通過購買大量的服務器和GPU來提升算力;二是通過芯片實現AI的加速。但是算力是一個完整的體系架構,甚至不僅僅包括硬件,而是軟件和硬件的“結合體”,只有了解AI算法的運算架構與邏輯,才能針對硬件去做深層次的優化。AI系統其實是有“套路”的設計,具備固定的計算模式,它需要的是一個專用計算,不像大數據和軟件需要的是通用計算。基于專用計算的特點,算法和軟件其實可以直接定義好計算,提前把計算的部分去硬件化。此外,過去傳統的通用通信協議、存儲系統也同樣面臨著無法支撐AI的困境,需要針對于AI算法的特性進行深度優化。以TCP的通信協議為例,該協議通過“三次握手”建立可靠的數據交換機制,保證數據傳輸不丟失。但AI只需要在傳輸過程中,保證數據的統計特性即可,傳輸100份數據與傳輸90份數據的統計結果差異微乎其微。
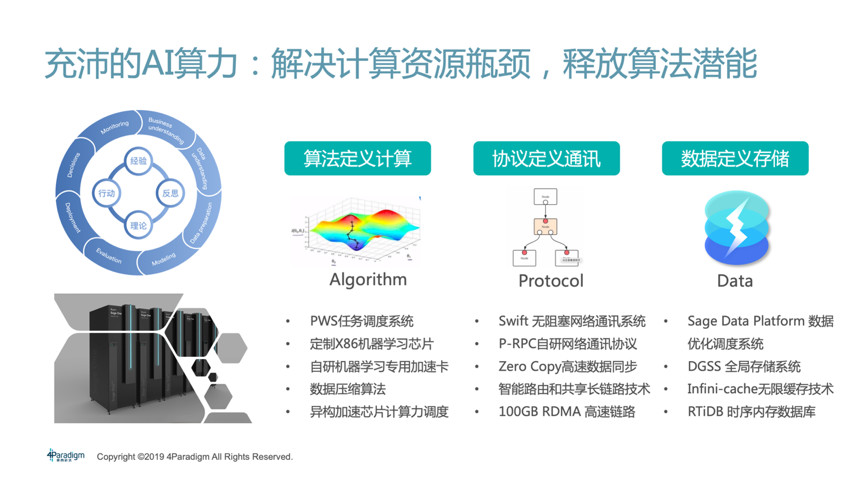
第四范式從去年開始研究開發新的硬件體系SageOne,我們不是為了去生產硬件,而是為了設計軟硬一體的方案,產出更適合人工智能專用算法的算力架構。目前第四范式設計的軟硬一體優化的服務器能夠做到TCO(總擁有成本)比傳統服務器降低一倍,到年底的時候希望有數量級的提升,會大幅降低企業AI落地門檻及總擁有成本。








 京公網安備 11010502049343號
京公網安備 11010502049343號