










浪潮存儲AS5600G2在SPC-1全球存儲性能基準測試中,以752萬IOPS、0.472ms時延的測試值刷新全球16控存儲性能記錄。這一測試成績遠超業界中端存儲的性能,甚至已經超越絕大部分高端存儲性能,受到業界廣泛關注。
如何更加高效的提升存儲系統的應用性能,構建起一套類似汽車自動變速箱的技術系統,讓存儲系統可根據前端應用自適應和調配不同數據處理策略,實現智能的IO感知、路徑選擇、組織和調度;讓我們一起走近浪潮存儲的這項核心技術“智能加速引擎iTurbo”。
智能加速引擎iTurbo是浪潮存儲I/O軟件棧的一套完整的智能加速算法,涵蓋對介質、芯片、組件、OS等的優化,具備對I/O、路徑、數據塊、空間條帶、計算存儲網絡資源等關鍵要素的智能調度能力,即保障百萬級的命令和數據在一系列先進的硬件,如高性能處理器、FPGA、PCIe、Optance介質以及NVMe、RDMA協議組成的高速數據處理系統上暢通無阻和高效運行。
本篇文章我們揭秘iTurbo的核心技術之一:智能I/O感知。它包括智能緩存預讀和特征數據識別。
智能緩存預讀:實現“熱”升“冷”降的數據電梯
在介紹緩存預讀之前,我們首先要搞清楚關于緩存的兩個基本問題,一是為什么要用緩存,二是緩存是如何工作的。
首先,我們來看看為什么要用緩存。大家知道,CPU 的運行速度比磁盤的速度快很多倍,這樣會導致 CPU 需等待磁盤完成處理后才能繼續下一道指令, 緩存的處理速度能夠跟得上 CPU,它作為CPU與磁盤之間的過渡,很好的解決了這一問題。當CPU處理完數據后,將數據直接發送給緩存,然后立即向應用返回確認,緩存中數據達到一定水位定期寫入磁盤,從而提升效率。
其次,我們來探索下緩存的工作原理。在程序運行過程中,緩存會有一個局部性原理,即程序會頻繁訪問局部緩存。如果緩存地址變換頻繁,那么緩存中存放的數據就會頻繁改變;如果程序頻繁訪問局部數據,那么 緩存中的數據改變就不會很大。因而命中率就會提高,CPU 的運行效率也會提升。
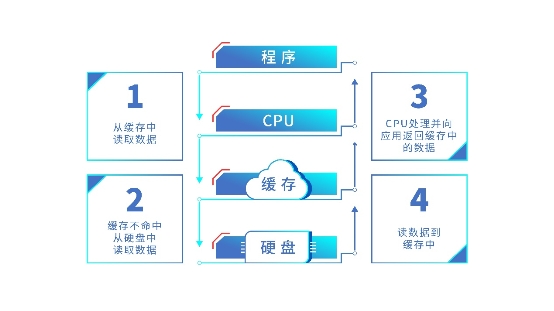
浪潮存儲的緩存工作原理
由此可知,衡量緩存管理的優劣有兩個指標:一是緩存命中率,命中率高,性能就高,否則反之;二是有效緩存的比率,有效緩存是指真正會被訪問到的緩存項,如果有效緩存的比率偏低,則相當部分磁盤帶寬會被浪費到讀取無用緩存上,而且無用緩存會間接導致系統緩存緊張,最后可能會嚴重影響性能。
現在我們清楚了緩存的工作原理及性能指標,那么為了充分發揮緩存的作用,僅僅依靠“暫存剛剛訪問過的數據”是遠遠不夠的,還要通過使用數據預讀算法——盡可能把將要使用的數據預先從內存中取到緩存里。那么關鍵問題來了,一是如何更精準的判斷哪些數據是應用程序將要使用的數據?二是當緩存寫滿時,如何判斷哪些數據被淘汰?這就是浪潮存儲緩存預讀算法的精髓所在。接下來我們就來深入剖析浪潮存儲緩存預讀的工作原理。
一方面,浪潮存儲基于緩存預讀,可精準判斷數據熱度。浪潮存儲的緩存預讀算法,可以根據歷史數據的I/O模式,通過智能分析、預判將要訪問的數據,提前將這些數據預讀到緩存中,提升緩存命中率,降低I/O訪問時延。這里主要有兩個關鍵技術要點:
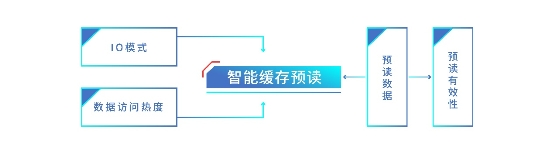
浪潮存儲的智能緩存預讀算法
一是自適應緩存預讀策略。讀I/O分為隨機讀和順序讀兩大類,為了保證預讀命中率,針對不同的I/O模式采用不同的預讀算法。對于順序讀根據區域地址進行順序預讀,對于隨機讀根據區域熱度進行預讀。根據不同的讀I/O模式兩種預讀策略動態調整,不僅可以保證很高的預讀命中率,同時有效率/覆蓋率也很好。
因為順序讀是最簡單而普遍的,而隨機讀在內核來說也確實是難以預測的。內核通過驗證如下兩個條件來判定是否順序讀:該區域內容被第一次讀,并且讀的是首部;當前的讀請求與前一個讀請求在區域內的位置是連續的;如果不滿足上述順序性條件,就判定為隨機讀。預讀策略根據讀I/O模式不同動態調整。
二是預讀粒度動態調整。當確定了要進行順序預讀時,就需要決定合適的預讀粒度。預讀粒度太小的話,達不到應有的性能提升效果;預讀太多,又有可能載入太多程序不需要的內容,造成資源浪費。為此,浪潮存儲可根據實際的需求動態調整預讀數據內容的粒度,從而提高緩存的有效率。如果緩存命中率提高,后續的預讀粒度將逐次倍增,直到系統的最佳預讀大小;隨著緩存命中率降低,后續預讀粒度將逐漸減小,直到系統的最佳預讀大小。
另一方面,浪潮存儲基于緩存替換算法 實現低訪問數據下移。當緩存滿了怎么辦?不得覆蓋掉一個,覆蓋掉哪一個?這就是替換算法要解決的。浪潮存儲的緩存替換算法是基于預讀數據的命中率,結合數據的訪問熱度,淘汰最近最少用的那一塊,從而提升預讀數據的有效性,保證預讀持續、高效的正向性能提升。
浪潮存儲的設計思路是,如果一個數據在最近一段時間沒有被訪問到,那么在將來它被訪問的可能性也很小。也就是說,當限定的空間已存滿數據時,應當把最久沒有被訪問到的數據淘汰。具體實現算法如下:
硬件緩存每一行都有一個計數器,用來記錄被使用次數。
計數器變化規則:
− 每組4行時,計數器有兩位,計數值越小則說明越被常用
− 命中時被訪問行的計數置0,比其低的計數器加1,其余不變
− 未命中且該組未滿時,新行計數器置為0,其余全加1
− 未命中且該組已滿時,計數值為3的那一行中的主存塊被淘汰,新行計數器置為0,其余全加1
說到這里,估計大家還是沒有看懂,為了更加直觀的展示算法原理,我們舉個例子:
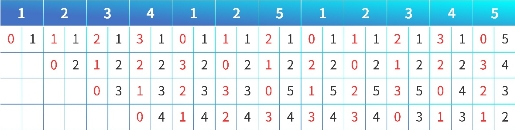
智能緩存替換算法原理
現在有四個格子,但是有 5 個不一樣的塊要進來,緩存替換過程如下:。
1 來,沒有命中,1 進入緩存。計數器為 02 來,沒有命中,2 進入緩存。2 計數器 0, 1計數器為 1(對應第三條)3 來同上4 來同上1 又來,命中,1 的計數器變為 0。其余加 1。2 又來,命中,2 的計數器變為 0。其余加 1。5 來了,但是現在 Cache 滿了。去掉哪一個呢?計數器最大的那個! …
特征數據識別:基于“逐字節”比對實現去重
根據用戶的數據特征建立數據特征表單,當新的數據請求與表單中的特征匹配時,說明該部分數據已經落盤,這部分數據可以避免重復寫入。特征匹配采用近似匹配的策略,存在兩份不同數據的特征一致的情況,為了確保用戶的數據安全,每份不同的數據都能一字不落的存放起來,浪潮存儲還對特征匹配的數據需要進行“逐字節”比較,為了降低逐字節比較時的訪盤時延,系統會智能感知特征數據的訪問熱度,將頻繁訪問的熱點特征數據提取到內存中,保證系統時延最低。
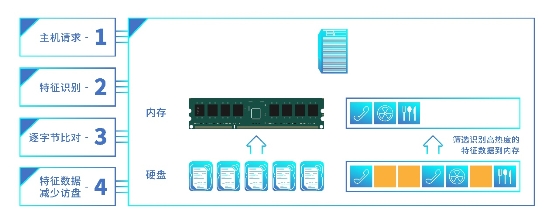
浪潮存儲的特征數據識別算法
總結一下,浪潮存儲的智能I/O感知,通過自適應緩存預讀算法對歷史數據I/O模式進行分析、判斷識別,對其提前讀取到緩存,從而達到緩存最高命中率。當緩存寫滿時,通過獨特的替換算法將使用最少數據的淘汰,將緩存發揮出其最大的價值,從而提升存儲整體I/O性能;通過特征數據識別和逐字節的比較,在確保數據安全的前提下減少數據落盤,從而提高存儲的性能及空間使用率。

















 京公網安備 11010502049343號
京公網安備 11010502049343號