


目前,以Optane形式推出的存儲級內存(SCM)已經與三星公司的Z-SSD齊頭并進,且可供服務器設備加以使用。而這將意味著什么呢?
SCM——亦被稱作持久性存儲器(簡稱PEEM)——是采用英特爾/美光方面的3D XPoint介質或三星公司的Z-SSD構建的一款存儲速度更快的非易失性存儲器版本,其中三星方面的Z-SSD是經由NAND LLC(每單元1 bit)調整而來。此外,其存儲速度高于閃存但低于DRAM,自然其市場定價也介于兩者之間。
SCM的速度足夠快,可將其作為DRAM的附屬設備并通過應用程序與系統軟件以將其轉化為內存使用。然而,由于SCM的存儲性質是持久性的,故而應用程序無需傳統的IO堆棧代碼即可從SCM中完成數據的讀取與寫入。
那么,SCM會對服務器與存儲產生怎樣的影響呢?
下面這張圖即可揭示謎底:
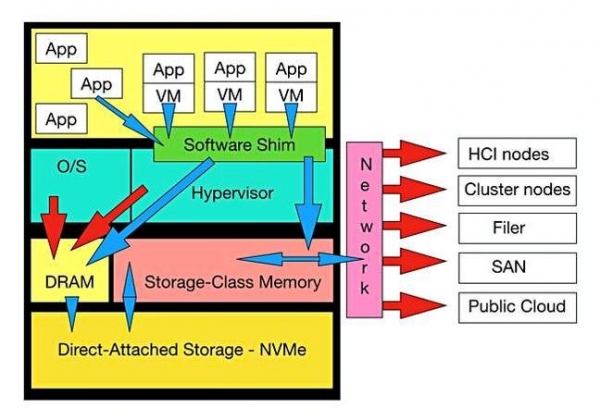
服務器中SCM的作用解析(圖片來源:Dave Hitz)
如圖所示,圖片頂端有一組應用程序(App)與虛擬機中的應用程序(App/VM),其中Apps在帶有操作系統的物理服務器上運行,而App/VM則運行于配有管理程序的虛擬化服務器。
由于上圖中沒有展示容器,故而我們暫將其視為另一種服務器的虛擬化形式。如今,App與App/VM均使用DRAM將IO操作傳送至本地直連或外部存儲(如紅色箭頭所示)。
而如果安裝了SCM,理論上其將與DRAM并行放置。那么一些軟件則需要將DRAM + SCM作為一套單獨的內存地址空間/實體呈現給App與App/VM(如藍色箭頭所示)。
該圖將其作為介于O/S、虛擬機管理程序以及App之間的一套軟件墊片機制。對于這些運行代碼而言,SCM如同內存一般擴展DRAM并確保能夠大幅提高IO受限的App與App/VM的運行速度。
另外,可將SCM看作一款帶有緩存管理軟件的透明緩存——簡而言之即為“墊片”。
SCM適用于熱門數據,其能夠完成數據的初步加載并將新創建的數據轉換為長期存儲。因此,藍色箭頭表示其能夠與服務器中的直連存儲設備實現連接或通過網絡以連接外部存儲設備。
其中的緩存管理軟件或墊片可能是系統級應用程序——例如NetApp的Plexistor,也可能是服務器操作系統或管理程序的一部分。那么在這種情況下,首當其沖的問題就是:物理服務器的操作系統——具體包括Windows、Unix與Linux——將如何支持SCM呢?
其次則是虛擬機管理程序——諸如vSphere、XEN與VM——又將如何實現其對SCM的支持呢?
硬件角度
提及硬件方面,那么這里還存在一個更為基礎的問題,即SCM介質是如何在服務器內部完成安裝的呢?是通過標準驅動架或PCIe插槽中的PCIe接口驅動器還是通過使用NV-DIMM形式直接安裝至內存總線呢?
后者無疑是最快的連接方式,但卻需要一套NV-DIMM標準以確保任何行業標準的X86服務器——即是指任一時期的服務器——能夠使用,并且據了解,制造商方面正在考慮使用IBM POWER、富士通/甲骨文的 SPARC以及ARM處理器。
有關硬件方面的另一問題即是:由誰來完成安裝呢?答案顯然是服務器供應商。而如果是選用1U 刀片式服務器或2U x 24插槽主力機型,那么機箱內部可用于其他組件(例如SSD)的空間會進一步減少,所以DRAM、SCM與本地存儲之間應該保持怎樣的一個平衡呢?
這對現在市場上的服務器供應商而言將會是一個棘手的問題,而其中就包括了思科、戴爾、富士通、HPE、華為、聯想、SuperMicro與Vantara等。
最后,SCM DIMM的生產制造又該由誰負責呢?迄今為止,盡管獨立的NV-DIMM供應商(例如Diablo Technologies)已經為此背水一戰,而結果卻一目了然,其生產制造必然是由SCM介質制造商負責——目前即是指英特爾/美光與三星公司。美光與三星都生產DRAM、NAND以及DIMM,并且兩家公司與服務器供應商都有一定的合作關系以出售其DRAM與NAND。
至此,我們已然明確物理供應鏈與SCM介質制造商以及服務器供應商之間的依存關系。所以,處于這一生態系統以外的任何一方都將很難以任何形式——無論是2.5英寸驅動器、附加卡還是NV-DIMM等——完成SCM介質驅動器的銷售。
軟件角度
軟件方面的問題在于操作系統與虛擬機管理程序供應商是否需要提供所需的SCM軟件或創建一套獨立的軟件系統——如同NetApp的Plexistor、Hazelcast或其他未知的開源項目(如Memcached)——以提供一套獨立的SCM系統。
無論結果如何,可以肯定的是,為了快速推進SCM的實施,相關應用程序皆應無需作出任何對應變更。
超融合方面
超融合型基礎設施(HCI)設備供應商會對SCM的采用做出怎樣的反應?答案很有可能是:a)HCI設備供應商為避免其性能落后,從而希望能夠采用SCM;b)希望在HCI節點上完成SCM的整合。
這對于思科、戴爾EMC(VxRack/Rail)、HPE以及如今的NetApp、Nutanix、Pivot3、Scale與各軟件HCIA供應商——諸如DataCore、Maxta等——而言將會是一個難題。
據悉,由于Nutanix收購了Pernixdata,故而其在這方面具有一定的優勢。Pernixdata方面的技術提供了管理程序級別的緩存。那么,SCM可以實現跨服務器(或HCI節點)整合以提供單個邏輯SCM資源池嗎?
目前,對于以上問題我們還尚未得出一個較為明確的答案。
網絡角度
SCM后端能夠將冷門數據轉移至長期存儲設備,此即意味著在傳統IO堆棧意義上,SCM后端可作為一套IO使用——除采用NVMe over Fabrics連接的場景下。所以,以上所提及的數據存儲轉移工作需要由組成SCM后端的代碼完成,而目標設備則可以是服務器本地或遠程設備(文件管理器、SAN或公共云)。
上文展示的圖表展示了包括HCI與集群節點在內的網絡列表,我們認為這對于HCI與集群供應商將會是一個難題。此外,與存儲陣列的網絡連接也將成為存儲陣列行業與存儲陣列互連生態系統——指以太網/iSCSI/NFS、光纖通道與InfiniBand供應商等——即將面臨的一大難題。
網絡互連需要一套成熟的NVMe over Fabrics標準,以便前端的服務器與后端的陣列能夠使用一套標準的NVMeoF HBA或適配器實現對通路中任一端的連接。然而,由于NVMeoF將作為必要的網絡管道,因此諸如博科或Mellanox這樣的供應商則無需再為SCM作出任何針對性調整。
存儲陣列角度
存儲陣列方面的相關人員可能認為其需要為此做出一定的貢獻以確保能夠將熱門數據作為SCM緩存的最佳使用區間。然而,由于端對端的NVMe連接可能會讓數據繞過其控制器,從而導致他們對于驅動器的狀態失去控制,并且如果服務器中的應用程序無法響應,他們就無法準確地將數據服務應用于驅動器內的數據,所以綜合以上的原因看來,存儲陣列方面的研究人員可能不會在服務器與其陣列之間建立端到端的NVMe連接。
Datrium、Excelero以及其他存儲陣列都配有一個服務器,所以原則上是可以完成的。
陣列供應商可以做的就是對來自于控制器緩存的NVMe fabric傳入請求提供服務并以此獲得NVMeoF級的速度,而在此過程中無需將其陣列轉換化為實質上的閃存JBOD——即純粹的、控制器旁路的端到端NVMe。
事實上,陣列控制器可以使用SCM以完成此類緩存,而NetApp正在致力于研究這一課題。
SAN、文件管理器以及對象存儲對SCM的態度與應用方式可能會存在一定的差異,但在這里我們就不再一一進行介紹了。
Nirvana即將推出——但仍需要一段時日
在安裝SCM之后再配合NVMe,無疑能夠令長期存儲服務器獲得比當今服務器更高的執行效率。機器學習、數據庫響應與分析也將會隨著服務器能夠承載的與實時處理的數據量提升而徹底改變。
然而,僅僅是安裝SCM介質并不足以直接完成上述效能。這一系列的技術領域與技術供應商都必須團結一致,共同努力才能夠完成這個顛覆性的技術革命。
SCM似乎已經不再是一個不可企及的目標,而是一個能夠實現的可能——盡管還需要時間以進一步發展相關技術。我們相信,在2019年或之后的某個時間點上,我們終將真正迎來SCM Nirvana 1.0。








 京公網安備 11010502049343號
京公網安備 11010502049343號