


寫在前面
做過分布式系統的人都知道,想要在大規模集群下處理高并發事務時同時滿足CAP(一致性、可用性、分區容錯),從理論上來說不可能,當然聽說最近谷歌已經實現了這樣的分布式系統,但是總的來說確實非常難。對于社交媒體的海量日志文件,如果我們也提出了需要確保高可用、持續寫入數據、按照記錄順序返回數據等三條要求,你覺得是否可以實現?FaceBook的LogDevice實現了。
什么是日志
日志是記錄一系列序列化的系統行為的信息,我們需要確保它們能夠被保存在可靠的地方。對于應用程序來說,日志的作用一般有兩個,即Troubleshooting和顯示程序運行狀態。好的日志記錄方式可以提供我們足夠多定位問題的依據。對于一些復雜系統,例如數據庫,日志可以承擔數據備份、同步作用,很多分布式數據庫都采用“write-ahead”方案,在節點數據同步時通過日志文件恢復數據。
日志一般具有三個特性:
面向記錄:寫入日志的一定是孤立的行,而不是一個字節。日志實質上是問題的最小單元,用戶也一定是讀取整行日志。日志的存儲原則上按照順序,即按照LSN(日志順序數字)存放,但是也不完全這么要求,所以日志系統可以優先高寫入需求,對寫入失敗容錯。日志天生就是遞增的:也就是說,日志是不會修改的,那么也就意味著,日志系統的設計應該是以高寫入、高讀取為目標,不需要擔心更新操作的數據一致性問題。日志存儲周期長:可能是一天,也可能是一個月,甚至于一年。這也就意味著,日志的刪除規則一般都是按照時間或者空間進行設定的,具有固定的規則。來個假如
假如我們要設計一個分布式日志存儲系統,你會怎么設計?
日志信息需要傳輸、存儲,為了實現穩定的數據交換,我們可以采用Kafka作為消息中間件。
Kafka實際上是一個消息發布訂閱系統。Producer向某個Topic發布消息,而Consumer訂閱某個Topic的消息,進而一旦有新的關于某個Topic的消息,Broker會傳遞給訂閱它的所有Consumer。在Kafka中,消息是按Topic組織的,而每個Topic又會分為多個Partition,這樣便于管理數據和進行負載均衡。同時,它也使用了Zookeeper進行負載均衡。
Kafka在磁盤上的存取代價為O(1),即便是普通服務器,每秒也能處理幾十萬條消息,并且它本身就是分布式架構,也支持將數據并行加載到Hadoop。
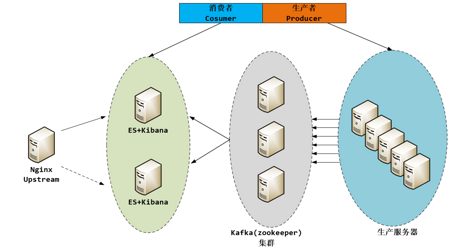
上面這張圖是一個典型的采用消息中間件進行日志數據交換的系統設計架構,但是沒有實現數據存儲,也沒有描述數據是如何被抽取并發送到Kafka的。
如果想要實現數據存儲,并描述清楚內部處理流程,我們可以采用怎么樣的日志處理系統架構呢?這里推薦你FaceBook的Scribe,它是一款開源的日志收集系統,在Facebook內部已經得到大量的應用。它能夠從各種日志源上收集日志,存儲到一個中央存儲系統 (可以是NFS,分布式文件系統等)上,以便于進行集中統計分析處理。
Scribe最重要的特點是容錯性好。當后端的存儲系統奔潰時,Scribe會將數據寫到本地磁盤上,當存儲系統恢復正常后,Scribe將日志重新加載到存儲系統中。
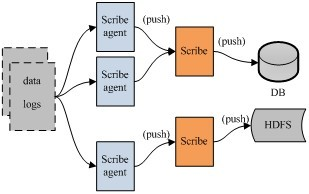
Scribe的架構比較簡單,主要包括三部分,分別為Scribe Agent, Scribe和存儲系統。Scribe Agent實際上是一個Thrift Client。Scribe接收到Thrift Client發送過來的數據,根據配置文件,將不同topic的數據發送給不同的對象。存儲系統實際上就是Scribe中的Store,當前Scribe支持非常多的Store。
貌似市面上已經有很多分布式日志收集系統了,為什么FaceBook還需要推出LogDevice呢?而且FaceBook自己已經有了Scribe,為什么還要繼續設計LogDevice?因為Scribe更多實現了日志數據的收集,它不是一個完整的日志處理、存儲、讀取服務,系統設計也較為死板,存儲更多依賴HDFS,使用過程中一定出現了不能滿足自身需求的情況。而對于開源的哪些分布式日志收集系統,更多的是集成各個開源組件,共同完成日志存儲系統設計需求。對于FaceBook的工程師來說,他們一貫秉承著用于創新的精神,想想Apache Cassandra,其實當時已經有HBase等成熟的NoSQL數據庫,但是由于存在中心節點等諸多設計上的限制,FaceBook自己搞了一個全新的無中心化設計的架構,即便在初期飽受質疑,后續也在不斷地改進,到目前為止,Cassandra真正進入到了它的黃金時代。
LogDevice
設計背景FaceBook擁有大量的分布式服務用于保存和處理數據,如果想要構建高可用的數據密集型分布式服務,FaceBook認為,一定需要保存日志。為了處理FaceBook內部日志的高強度負載、性能需求,FaceBook把LogDevice設計成了可以調節的系統,而不是一套方案應對所有需求。
需求整理對于日志服務的需求,也就是對于LogDevice的需求,第一條就是服務必須永遠在線,不允許出現離線狀態,因為FaceBook內部各個系統都需要保存日志,也就是說高可用。第二條是持久性,也就是說不允許丟數據,特別是返回客戶端寫入成功之后,絕對不能丟失數據。第三條是存在一定程度的數據讀取,并且通常是讀取最近寫入的日志數據,這一條實質上是要求寫入響應快。
設計思路對于整個日志系統來說,整個設計應該更加關注數據的寫入速度,怎么樣設計才能具有更快的寫入速度,并能支撐一定的讀取速度,所以需要看看數據是如何被寫入到LogDevice的。
如果需要提升日志文件的寫入速率,或者更高一點要求,希望沒有寫入速率限制,你該怎么實現?我們可以模仿分布式文件系統或者分布式數據庫的設計方式,采用多處副本方式,即一個文件有多個副本,那么每次日志寫入請求就有了幾處寫入地址選擇,而不是單一一個節點,或者幾個特定的節點。這樣做的好處是,當集群中的一部分節點宕機或者失去聯系時,日志寫入請求不會受到大規模的干擾,并且寫入負載能夠做到相對均衡。
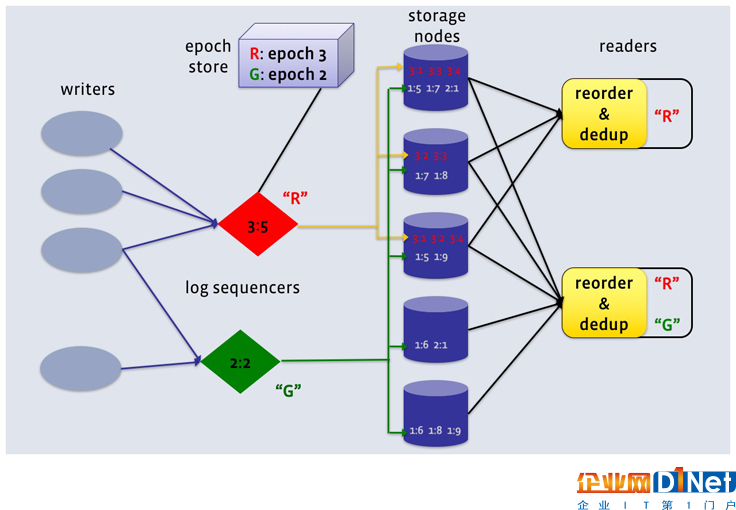
數據副本設計,有沒有其他系統實現?
有,非常多,例如HDFS、Cassandra。我們這里還是以FaceBook自己出品的Cassandra為例。
Cassandra在多個節點上存儲副本以確保可用性和數據容錯。副本策略決定了副本的放置方法。集群中的副本數量被稱為復制因子,復制因子為1表示每行只有一個副本,復制因子為2表示每行有兩個副本,每個副本不在同一個節點。所有副本同等重要,沒有主次之分。作為一般規則,副本因子不應超過在集群中的節點的樹木。當副本因子超過節點數時,寫入不會成功,但讀取只要提供所期望的一致性級別即可滿足。目前Cassandra中實現了不同的副本策略,包括:
SimpleStrategy:復制數據副本到協調者節點的N-1個后繼節點上;NetworkTopologyStrategy:用于多數據中心部署。這種策略可以指定每個數據中心的副本數。在同數據中心中,它按順時針方向直到另一個機架放置副本。它嘗試著將副本放置在不同的機架上,因為同一機架經常因為電源、制冷和網絡問題導致不可用。多數據中心集群最常見的兩種配置方式是:
每個數據中心2個副本:此配置容忍每個副本組單節點的失敗,并且仍滿足一致性級別為ONE的讀操作。每個數據中心3個副本:此配置可以容忍在強一致性級別LOCAL_QUORUM基礎上的每個副本組1個節點的失敗,或者容忍一致性級別ONE的每個數據中心多個節點的失敗。LogDevice將日志里的記錄順序和實際存儲的順序區分開來,通過序列器產生一個學號,對每一行存儲的日志進行重新序列標定。一旦一行記錄被標定了這個序列號,接下來該條記錄(數據)就會被保存在集群中任一位置。注意,這里提到的序列號不是一個數字,而是一對數字,第一個數字叫做“ epoch number”,第二個是相對于第一個的偏移量。序列號生成器本身也是需要做好容災的,也就是說,一旦一個序列號生成器服務不在線,另一個一定要被立即啟用,而它生成的序列號要比當前已經存在的序列號大。FaceBook使用ZooKeeper保存序列號(Epoch Number)。
這里為什么要選擇ZooKeeper存儲序列號?
ZooKeeper作為Hadoop
項目中的一個子項目,是Hadoop集群管理的一個必不可少的模塊,它主要用來控制集群中的數據,如它管理Hadoop集群中的NameNode,還有HBase中Master節點的選舉機制、服務器之間的狀態同步等。除此之外,ZooKeeper還可以被用在構建高可用性集群、統一命名服務管理、分布式緩存機制設計、配置文件管理、集群管理、分布式鎖機制設計、隊列管理等等。
存儲序列號的思路配置文件管理類似。
配置文件的管理在分布式應用環境中很常見,例如同一個應用系統需要多臺PC Server運行,但是它們運行的應用系統的某些配置項是相同的,如果要修改這些相同的配置項,那么就必須同時修改每臺運行這個應用系統的PC Server,這樣非常麻煩而且容易出錯。諸如這樣的配置信息完全可以交給ZooKeeper來管理,將配置信息保存在ZooKeeper的某個目錄節點中,然后將所有需要修改的應用機器監控配置信息的狀態,一旦配置信息發生變化,每臺應用機器就會收到ZooKeeper的通知,然后從ZooKeeper獲取新的配置信息應用到系統中。
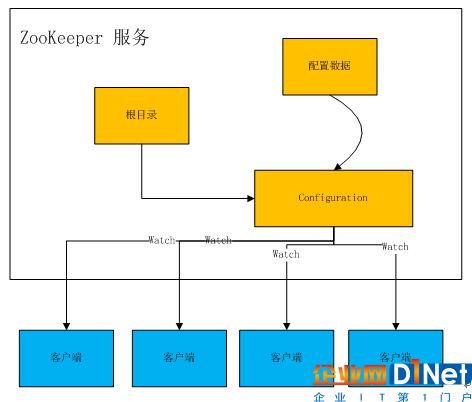
如上圖所示,實際應用時我們可以通過自動監測Master節點內是否形成了新的配置文件,并在檢測到形成了新的配置文件后主動上傳到ZooKeeper,并下發到各Slave節點加載到內存中用于搜索任務的處理,無需管理人員在發現Master節點形成了新的配置文件之后,重啟Master節點才將新的配置文件上傳,顯然降低了Master節點與Slave節點間配置文件同步的繁瑣性,提高了設備的智能性,降低了同步成本。
根據FaceBook的設計思路,由于日志文件本身是可以隨機讀的,并且很多節點上都存在數據,這有點像小文件存儲方式,每個節點上的數據都可以被讀取,因此不會造成IO和網絡資源的浪費。
數據是怎么做到負載均衡的?
FaceBook沒有在文章中描述實現原理。我們可以看看HDFS是怎么實現的。
數據平衡過程由于平衡算法的原因造成它是一個迭代的、周而復始的過程。每一次迭代的最終目的是讓高負載的機器能夠降低數據負載,所以數據平衡會最大程度上地使用網絡帶寬。下圖1數據平衡流程交互圖顯示了數據平衡服務內部的交互情況,
包括NameNode和DataNode。
步驟分析如下:
數據平衡服務首先要求NameNode生成DataNode數據分布分析報告。選擇所有的DataNode機器后,要求NameNode匯總數據分布的具體情況。確定具體數據塊遷移路線圖,保證網絡內最短路徑,并且確保原始數據塊被刪除。實際開始數據塊遷移任務。數據遷移任務完成后,通過NameNode可以刪除原始數據塊。NameNode在確保滿足數據塊最低副本條件下選擇一塊數據塊刪除。NameNode通知數據平衡服務任務全部完成。HDFS數據在各個數據節點間可能保存的格式不一致。當存放新的數據塊(一個文件包含多個數據塊)時,NameNode在選擇數據節點作為其存儲地點前需要考慮以下幾點因素:
當數據節點正在寫入一個數據塊時,會自動在本節點內保存一個副本。跨節點備份數據塊。相同節點內的備份數據塊可以節約網絡消耗。HDFS數據均勻分布在整個集群的數據節點上。FaceBook采用內存+磁盤的方式存儲日志,HDD硬盤可以達到100-200MBps每秒的順序讀寫速度,隨機讀寫速度頂峰可以達到100-140MBps每秒。用來存儲日志的服務被稱為LogsDB,它是針對寫入性能進行特殊優化過的。LogsDB本身又是構建于RocksDB之上的,RocksDB是基于LSM樹的有序Key-Value存儲層。RocksDB的每一個實例對應LogsDB的分區,當寫入日志文件時,會寫入到最新的分區,也就是最近訪問過的RocksDB實例(以log id、LSN排序),然后以順序方式保存到磁盤(稱為SST文件)。這種方式確保了寫入的方式是順序方式,但是需要合并文件(當達到LogsDB分區的最大文件數量時)。
總結
就在我寫文章的時候,微博因為“鹿晗介紹女朋友”事件奔潰了,系統啟動之后的數據同步、驗證過程,日志的作用非常重要。目前LogDevice還沒有開源,但是從它的介紹來看,它應該是結合了FaceBook內部的多個開源項目的精髓,例如Cassandra,它的無中心化存儲、碎片化存儲(SSTable)、SSTable文件合并等等優秀的特性,為確保日志文件的高速寫入、快速讀取提供技術支撐。FaceBook已經明確今年年底會開源LogDevice,喜歡分布式實時處理、存儲系統的同學們,就等著它了。
作者介紹
周明耀,2004年畢業于浙江大學,工學碩士。13年軟件研發經驗,近10年技術團隊管理經驗,4年分布式計算、大數據技術經驗。出版書籍包括《大話Java性能優化》、《深入理解JVM&G1 GC》、《技術領導力-碼農如何才能帶團隊》。個人微信號michael_tec,個人公眾號“麥克叔叔每晚10點說”,每天發布一篇技術短文。
感謝郭蕾對本文的審校。








 京公網安備 11010502049343號
京公網安備 11010502049343號