


今天展示的可能是大家最為推崇的一種對深度學習的構建。DeepLearning11搭載10個NVIDIA GeForce GTX 1080 Ti 11GB GPU,是Mellanox的 Infiniband系列,外形尺寸是4.5U。該系統與DeepLearning10之間有重要的區別,主要是添加了8個GTX 1080 Ti顯卡。 DeepLearning11 采用single-root的設計 ,這種設計已經在深度學習領域中流行起來了。
之前已經有了許多深度學習的構建,很多機器已經投入使用。其中有一些較小的版本,包括之前發布的DeepLearning01和DeepLearning02。它們僅僅是個開端,但DeepLearning11完全不同。現在這個架構已經被世界前十的超大規模深度學習企業所使用。
DeepLearning11:組件
如果我們要求使用NVIDIA可能會被告知需要購買特斯拉(Tesla)或Quadro卡。但NVIDIA特別要求服務器原始設備制造商(OEM)不要在服務器中使用他們的GTX卡。當然,這僅僅意味著經銷商在交付客戶之前安裝這些卡。

該系統采用的是超微的 SYS-4028GR-TR2,它是市場上主流的高GPU密度系統之一。TR2非常重要,因為它是機箱的single root 版本,不同于DeepLearning10的-TR dual root 系統。

▲DeepLearning11 GTX 1080 Ti Same CPU
與DeepLearning10的構建相似,DeepLearning11具有“隆起”,使系統總體積達到4.5U。你可以從服務器“Humping”趨勢在數據中心的部分了解到更多。它使我們能夠在自己的系統中也使用NVIDIA GeForce GTX卡。

▲超微4028GR-TR/ -TR2
我們正在使用Mellanox ConnectX-3 Pro VPI適配器,它既支持40GbE(主實驗室網絡)也支持56Gbps的 Infiniband(深度學習網絡)。盡管已經在使用它,但是使用FDR Infiniband與RDMA在目前來說還是十分受歡迎的。1GbE或是10GbE的網絡根本不能足夠快地供給這些機器。于是我們在在實驗室中安裝了一個Intel Omni-Path交換機,這將是該實驗室的首個100Gbps結構。

▲Mellanox ConnectX-3 Pro
在CPU和RAM方面,我們使用了2個Intel Xeon E5-2628L V4 CPU和256GB ECC DDR4 RAM。Intel Xeon E5-2650 V4是這些系統的常見芯片,它們是最低端的主流處理器,支持9.6GT / s QPI的速度。而我們正在使用的是英特爾至強E5-2628L V4 CPU,因為單根設計會賦予另一個重要的優勢,將不再只是GPU間的QPI流量。雖然有可能可以使用單個GPU來為系統供電,但是我們仍然使用兩種更高的RAM容量——16GB的RDIMM因為比較便宜。這些系統可以承受高達24個DDR4的LRDIMM從而獲得大量的內存容量。
對于那些使用NVIDIA nccl庫的深度學習者來說,常見的PCIe是非常重要的。這也是許多深入學習的構建不會轉換到更高的PCIe數量的原因,它通常是更高的延遲或是更受限制的設計,如AMD EPYC與Infinity Fabric。
系統成本
在成本明細方面,如果使用英特爾E5-2650 V4芯片,這可能是什么樣子:
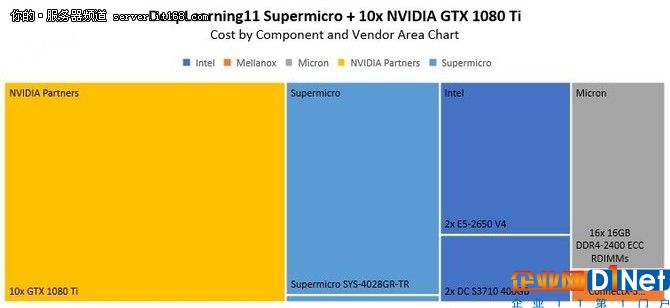
與AWS g2.16大型實例類型相比,總價約16,500美元的投資回收期在90天以內。以下是相關的托管費用。
將DeepLearning11 的10個GPU示例與DeepRearning10的8個GPU進行比較,你可以看到,在整體系統成本方面,大約25%的性能損失較小:

正如人們所想象的那樣,添加更多的gpu意味著系統其余部分的開銷將有可能超過這些gpu。因此,如果你的應用程序可擴展性比較好,每個系統可能得到10個gpu。
DeepLearning11:環境因素
我們的系統有四個psu,這對于10個 GPU的配置是必要的。為了測試這個,我們讓系統運行一個巨大的模型幾天,看看有多少功耗被使用。以下是是10個GPU服務器的能耗,看起來就像是PDU運行Tensorflow GAN的工作負載的情況:
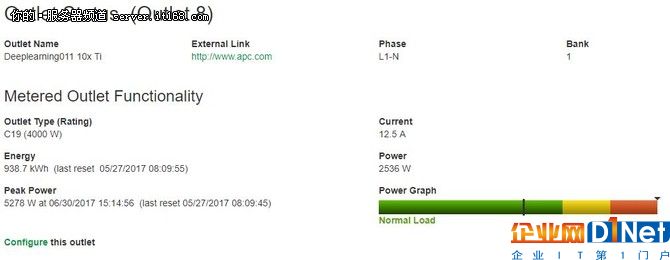
從上圖可以看到,大約2600W確實是不錯。根據模型在訓練中的位置,這臺機器在3.0 - 3.2kw范圍內,持續功率消耗更高,卻沒有觸及到gpu的功率限制。
這個峰值在深度學習領域上,幾個星期內使用不同的問題和框架,它的高峰值仍不足4kW。使用4kW作為基礎,就可以很容易地計算出這種機器的托管成本。
正如你所看到的,12個月以來,托管成本方面開始縮小硬件成本。但其實,使用的是實際的數據中心實驗室的托管費用。將上述與DeepLearning10的8個gpu進行比較,你可以看到添加500W額外計算的影響:
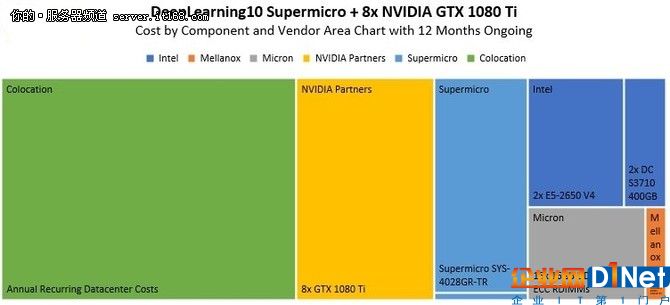
添加額外的gpu與系統成本相比,會增加運營成本,這是與DeepLearning10相比的狀況。隨后幾年,托管成本將會遠遠超過硬件成本。
DeepLearning11:性能影響
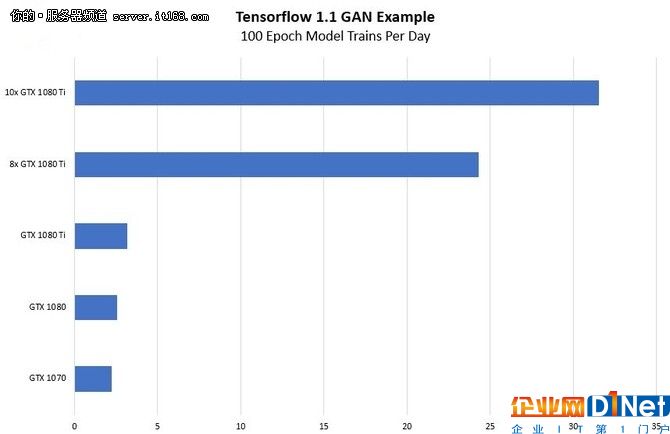
本文最重要的是想要展示從這個新系統中獲得了多少性能。1600美元的系統和1.6萬美元的系統之間存在很大的差異,因此我們預計其影響也會類似。采集了我們的樣本Tensorflow,生成Adversarial Network(GAN)圖像訓練測試用例,并在單卡上運行,然后進入10個GPU系統,用每天的訓練周期來表達結果。這是一個很好的說明如何在系統的購買價格中增加1400美元或更多的例子。
寫在最后
正如人們所想象的那樣,DeepLearning10和DeepLearning11消耗了大量的功耗。僅僅這兩個服務器的平均功率就超過5kW,峰值更高。這對主機有很大的影響,因為在許多機架中增加0.5RU并不重要。大多數的機架其實不能提供25kW +的電源力和冷卻能力以滿足GPU服務器的需求。
最終,我們希望在實驗室中擁有一個重要的Single Root系統,而DeepLearning11及其10個NVIDIA GTX 1080 Ti 11GB GPU則具備這一點。由于我們提倡首先擴大GPU的大小,從每臺機器的GPU數量到多臺機器,DeepLearning11既是一個偉大的頂級單機,同時也是基于設計可以擴展到多臺機器的平臺。








 京公網安備 11010502049343號
京公網安備 11010502049343號