


為什么深度學習會是計算機的“殺手級應用”? IBM是怎么找到分布式計算來加快大數據人工智能工作負載處理速度的?
總的來說,這聽起來足夠簡單:你有一臺大型快速服務器在處理人工智能相關的大數據工作負載。然后需求變了,更多數據需要添加進來才能在一定時限內完成任務。邏輯上講,你需要做的,就是添加更多的處理能力而已。
然而,就像流行表情包里說的一樣:“臣妾做不到啊!”
沒錯,直到今天,添加更多的服務器是解決不了這個問題的。迄今為止的深度學習分析系統,都只能運行在單臺服務器上;用例僅僅是不能通過添加更多服務器來擴展而已,這背后有些深層次的原因。
但是,現在,這一切都成為了歷史。8月8日,IBM宣稱,已找到新的分布式深度學習軟件開發路線,不久之后深度學習負載分布式處理不再是夢。這很有可能是至少最近10年來,人工智能計算領域里跨越最大的一步。
聯網服務器搞定AI任務聽起來簡單,但事實并非如此
僅僅能夠聯網一組服務器使之協調工作解決單個問題,IBM Research 就已然發現了讓大規模深度學習更為實際的里程碑:如IBM最初的結果中證明的,用數百萬張照片、圖片甚至醫學影像,以及通過增加速度和大幅提升圖像識別準確率,來訓練AI模型。
同樣是在8月8號,IBM發布了其 Power AI 軟件貝塔版,供認知和AI開發者打造更準確的AI模型,發展更好的預測。該軟件將有助于縮短AI模型訓練時間,可從數天乃至數周,縮短至數小時。
到底是什么讓深度學習處理如此耗時?首先,數據量非常龐大,往往涉及很多GB或TB數據。其次,能夠梳理這些信息的軟件現在才針對這類工作負載進行了優化。
很多人現在都沒搞清楚的一件事是,深度學習與機器學習、人工智能和認知智能到底哪里不一樣?
深度學習是機器學習的一個子集
IBM高性能計算與數據分析認知系統副總裁薩米特·古普塔稱:“深度學習被認為是機器學習的一個子集,或者說一種特別的方法。”
我常舉的一個深度學習的例子是:我們在教小孩認貓貓狗狗時,會給他們展示很多狗狗的圖片,然后有一天小孩子就會說“狗”了。但是小孩子并沒有認清狗狗有4條腿和一條尾巴的事實,其他一些細節也沒認識到;小孩子就是在實際整體感知一條狗狗。這與傳統計算機模型那種“如果……否則……”的條件邏輯迥然不同。深度學習試圖模仿這種整體認知,所用方法就是所謂的神經網絡。
深度學習的問題在于,計算量太過龐大,高通信開銷一直是其最大的挑戰。
這就是計算機終結者,實實在在的“殺手App”。我們已經在用GPU(圖形處理單元)加速器來加快深度學習訓練了。我們所做的,就是向這些計算機模型饋送數百萬的圖片,但之后我們需要在帶強力GPU的計算機上訓練它們,為記錄和理解這些圖像涉及的東西。
大多數深度學習框架可擴展到一臺服務器上的多個GPU,但不能延伸至多臺帶GPU的服務器。于是,我們的團隊編寫了軟件和算法,自動化并優化了該超大復雜計算任務的并行計算,使之能跨數十臺服務器上的數百個GPU加速器并行執行。這很難!
IBM發現“理想擴展”
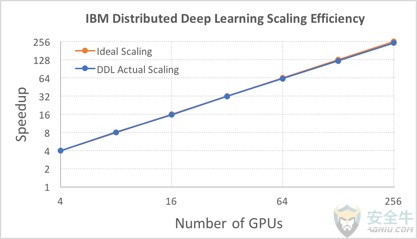
IBM Research 提交了近乎理想的擴展方式。在64臺 IBM Power 系統的256個GPU上部署的開源Caffe深度學習框架中,其新分布式深度學習軟件,達到了歷史新低的通信量,以及95%的擴展效率。

IBM研究員Hillery Hunter開發的可驅動多個GPU的新軟件
上一個最佳擴展,是 Facebook AI Research 在Caffe2上執行的訓練中展現出來的89%,且其通信量更高。采用該軟件,IBM Research 在超大數據集(750萬張圖像)上訓練的神經網絡,達到了33.8%的圖像識別準確率新高。之前的記錄是微軟的29.8%。
IBM Research 分布式深度學習代碼的技術預覽,可從 IBM PowerAI 4.0 的TensorFlow版和Caffe版獲取。
在ResNet-101深度學習模型上,IBM用來自ImageNet-22K數據集的750萬圖片,以批處理大小5120的規模,證明了其分布式深度學習軟件的擴展能力。該團隊采用64臺 IBM Power 服務器集群,以總共256塊 NVIDIA P100 GPU 加速器,達到了88%的擴展效率,且只有非常低的通信開銷。
分布式深度學習前景廣大,可在很多領域形成突破,從消費者移動App體驗到醫療影像診斷。但大規模部署深度學習的準確性和實用性上的進展,卻受阻于大規模深度學習AI模型運行上的技術難題——訓練時間以天計,甚至以周計。
分析師怎么說
Moor Insights & Strategy 總裁兼首席分析師派翠克·摩爾海德稱:“這是過去6個月里我所見過的深度學習行業較大突破之一。有趣的部分在于,這一突破來自IBM,而不是谷歌之類的Web巨頭,意味著企業可以通過OpenPOWER硬件和PowerAI軟件在內部應用,甚或通過云提供商Nimbix來采用該技術。
最令人震驚的,是添加擴展節點時的近線性擴展率,性能在90%到95%之間。最簡化的看待方式,就是橫向擴展的AI vs. 我們今天大多數人用的傳統向上擴展。性能的提高是數量級的。
技術咨詢公司 Enderle Group 總裁羅博·恩德勒稱,IBM此次發布的重要性在于,你可以用硬件擴展深度學習操作的性能。深度學習操作上一直都有可用GPU數量上的限制,IBM有效去除了這一限制,讓公司企業可以通過購買硬件,來換取完成操作所需的時間。
這是巨大的一步,尤其是在安全和欺詐防護之類的領域,因為這些領域的系統訓練所需時長,往往是以天計,但破壞卻可在數分鐘內就達到百萬級。因此,你部署的解決方案,應能以更即時的方式,更合理地解決這一巨大的風險暴露面。
IT行業分析公司Pund-IT首席分析師查爾斯·金稱,IBM的速度提升十分驚人。之前的紀錄保持者微軟的系統在10天內完成了訓練,達到了29.8%的準確率。IBM的集群配合上該新的DDL庫,在7小時內就訓練完畢,準確率高達33.8%。
另外,IBM的DDL庫及API,任何使用該公司 Power Systems 和 PowerAI V4.0 以上版本的用戶均可采用。結合對Caffe和 TensorFlow AI 框架的支持,IBM計劃讓該DDL庫和API對Torch和Chainer開放。
“總之,通過大體上清除深度學習訓練瓶頸,斬落當前性能領跑者,IBM的新DDL庫和API應能使AI項目更具競爭力,更吸引公司企業和其他機構組織。”








 京公網安備 11010502049343號
京公網安備 11010502049343號