


1.無服務器的承諾和爭議
“無服務器”術語最早出現在 2012 年左右的一篇文章里,作者 Ken Fromm 對它的解釋是:
“無服務器”一詞并不意味著不再涉及服務器,它只是意味著開發人員不再需要考慮那么多的物理容量或其他基礎設施資源管理責任。通過消除后端基礎設施的復雜性,無服務器讓開發人員將注意力從服務器級別轉移到任務級別。
雖然不少技術先知認為無服務器架構是“一項重大創新并將很快流行起來”,但這個概念在提出當時并沒有得到很好的反響。
真正讓無服務器得到廣泛關注的事件是亞馬遜云科技于 2014 年推出 Amazon Lambda 服務。之后, 隨著谷歌和微軟等企業的服務進入市場,“無服務器”才逐漸成為行業“熱詞”。
相較于“傳統服務”,無服務器計算的優勢主要有幾點:
-
在無服務器平臺上,無需用戶自身去維護操作系統。開發人員只需要編寫云函數,選擇觸發云函數運行的事件就可以完成工作。例如加載一個鏡像到云存儲中,或者向數據庫添加一個很小的圖片,讓無服務器系統本身來處理其他所有系統管理的操作,如選擇實例、部署、容錯、監控、日志、安全補丁等等。
-
更好的自動擴縮容方式,理論上能應對突發的從“零”到“無窮大”的需求峰值。有關擴展的決定由云提供商按需提供,開發人員不再需要編寫自動擴展策略或定義機器級別資源(CPU、內存等)的使用規則。
-
傳統云計算按照預留的資源收費,而無服務器按照函數執行時間收費。這也意味著更加細粒度的管理方式。在無服務器框架上使用資源只需為實際運行時間付費。這與傳統云計算收費方式形成了鮮明對比,后者用戶需要為有閑置時間的計算機付費。
作為云計算的下一個迭代,無服務器計算讓開發者可以更關注于構建產品中的應用,而不需要管理和維護底層堆棧,且比傳統云計算更為便宜,因此無服務器被譽為“開發新應用最快速的方式,同時也是總成本最低的方式”。
“伯克利觀點”甚至認為,無服務器計算提供了一個接口,極大地簡化了云編程,這種轉變類似于“從匯編語言遷移到高級編程語言”。
從誕生開始,“無服務器”就被寄予了厚望,但在發展過程中也免不了會存在爭議,之前涉及到的一些問題有:
-
編程語言受限。大多數無服務器平臺僅支持運行特定語言編寫的應用。
-
供應商鎖定風險。在“函數”的編寫、部署和管理方式上,幾乎不存在跨平臺的標準。這意味著將“函數”從一個特定于供應商的平臺遷移到另一個平臺非常耗時費勁。
-
性能問題如冷啟動。如果某個“函數”之前未在特定平臺上運行過,或是在一段時間內未運行,那么就需要耗費一些時間做初始化。
2019 年被認為是無服務器有重大發展的一年。在這一年的年底,亞馬遜云科技發布了 Amazon Lambda 的“預置并發(Provisioned Concurrency)”功能,它允許亞馬遜云科技無服務器計算用戶使其函數保持“已初始化并準備好在兩位數毫秒內響應”的狀態,這意味著“冷啟動”問題成為過去,行業達到一個成熟點。
雖然這項技術仍然有較長的路要走,但隨著越來越多的公司,包括亞馬遜云科技、谷歌、微軟在這項技術上的投資,我們看到了無服務器采用率在持續增長。據 Datadog 2021 年發布的無服務器狀態報告,開發人員正加速采用無服務器架構:2019 年之后 Amazon Lambda 的使用率顯著增加,2021 年初,Amazon Lambda 函數的平均每天調用頻率是兩年前的 3.5 倍,且半數 Amazon Web Services 新用戶已采用 Amazon Lambda。雖然微軟和谷歌的份額有所上升,但作為無服務器技術的先驅,Amazon Lambda 在采用率方面一直保持領先地位,有一半的函數即服務(FaaS)用戶在使用亞馬遜云科技的服務。據 Amazon Web Services 公布的數據顯示,已有數十萬家客戶在用 Amazon Lambda 來構建他們的服務。
2.通過 Amazon Lambda 看無服務器技術的演進
Amazon Lambda 是一種事件驅動的計算引擎,亞馬遜云科技在 2014 年 11 月的亞馬遜云科技 re:Invent 大會上發布了該功能的預覽版本。這馬上引起了競爭對手的跟進,不少企業紛紛開始在云上提供類似服務,谷歌于次年 2 月發布了 Cloud Functions, IBM 也于同月發布了 Bluemix OpenWhisk,微軟于次年 3 月份發布預覽版 Azure Functions,等等。
在 Amazon Web Services 的產品頁面上,亞馬遜云科技給 Amazon Lambda 下的定義是:“用戶無需預置或管理基礎設施即可運行代碼。只需編寫代碼并將其作為 .zip 文件或容器鏡像上傳即可。”
一個簡單的用例是,西雅圖時報使用無服務器技術自動調整移動、平板電腦和桌面設備顯示所需的圖像大小,每當圖像被上傳到 Amazon Simple Storage Service (S3) ,就會觸發 Amazon Lambda 函數調用執行調整圖像大小的功能。西雅圖時報僅在調整圖像大小后才向 Amazon Web Services 付費。
Amazon Lambda 的關鍵進展
對于要探索無服務器技術的團隊來說,了解 Amazon Lambda 至關重要。無服務器雖然不等于 Amazon Lambda,但自 2014 年發布以來,Amazon Lambda 幾乎已成為 Amazon Serverless 服務的代名詞。實際上,Amazon Lambda 需要和其它工具一起才能形成一套完整的無服務器架構,比如通過 Amazon API Gateway 發送 HTTP 請求,或調用 Amazon S3 存儲桶、Amazon DynamoDB 表或 Amazon Kinesis 流中的資源。
在發布早期,還只有 Amazon S3、Amazon DynamoDB 和 Amazon Kinesis 可用于 Amazon Lambda 函數。但自那之后,亞馬遜云科技又逐步為 Amazon Lambda 函數集成了許多其它服務,例如 Amazon Cognito 認證、Amazon API Gateway、Amazon SNS 、Amazon SQS、Amazon CloudFormation 和 Amazon CloudWatch 等等。
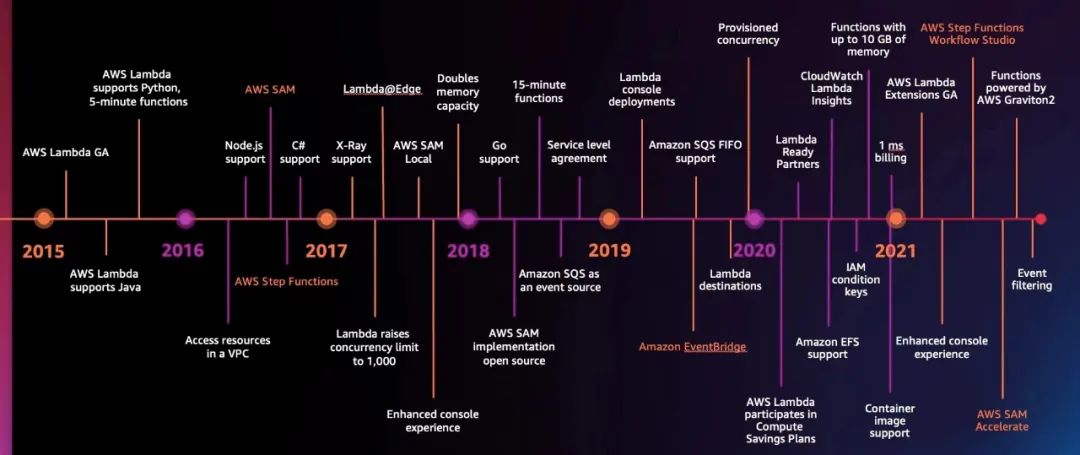
在 2014 年推出時,Amazon Lambda 只支持 Node.js,2015 年底,Amazon Lambda 中添加了 Java 支持,2016 年的時候又添加了 Python 支持。到現在,Amazon Lambda 原生支持 Java、Go、PowerShell、Node.js、C#、Python 和 Ruby 代碼,并提供 Runtime API,允許用戶使用任何其它編程語言來編寫函數。
使用 Amazon Lambda ,用戶除上傳代碼(或在 Amazon Lambda 控制臺中構建代碼)外,還需要選擇內存、超時時間來創建函數。
最開始 Amazon Lambda 函數超時時長為 30 秒,后來被延長為 5 分鐘。2018 年 10 月,Amazon Web Services 將超時時長設置為了 15 分鐘,從此用戶可以運行時間更長的函數,更加輕松地執行大數據分析、批量數據轉換、批量事件處理和統計計算等任務。
Amazon Lambda 函數會根據配置的內存量線性分配 CPU 和其他資源。2020 年底,Amazon Lambda 函數的內存上限調整為了 10 GB ,與之前相比增加了 3 倍多,這也意味著用戶可以在每個執行環境中訪問多達 6 個 vCPU,可以讓用戶的多線程和多進程程序運行得更快。
在發布至今這七年里,Amazon Serverless 服務各方面都在不斷改進:
2016 年,亞馬遜云科技發布了 Amazon Step Functions,可以組合調用多個 Amazon Lambda 函數和其它 Amazon 服務,將復雜的業務邏輯可視化地表達為低代碼、事件驅動的工作流。
2017 年,Amazon Lambda 的默認并發數提升到了 1000,并提供了分布式跟蹤工具 X-Ray。
2018 年,亞馬遜云科技發布了 Amazon Aurora Serverless v1 版本,正式宣告更復雜的關系型數據庫(RDBMS)也能具備 Serverless 的特性,實現了云數據庫基于負載的自動啟停與彈性擴展。隨著云服務的演化,亞馬遜云科技相繼發布了五項 Serverless 數據庫服務,包括 Amazon Aurora Serverless、Amazon DynamoDB、Amazon Timestream(一種時間序列數據庫服務)、Amazon Keyspaces(兼容 Apache Cassandra 的托管數據庫服務)和 Amazon QLDB(一種全托管的分類賬數據庫)。目前,Amazon Aurora Serverless 已從 v1 版進化到 v2 版,Aurora Serverless v2 可以在一秒內將數據庫工作負載從數百個事務擴展到數十萬個事務,與為峰值負載配置容量的成本相比,最多可節省 90% 的數據庫成本。
2019 年,亞馬遜云科技發布了 Amazon EventBridge,它是一種無服務器事件總線服務,作為集中式樞紐連接到 Amazon Web Services 服務、自定義應用程序和 SaaS 應用程序,提供從事件源到目標對象(例如 Amazon Lambda 和其他 SaaS 應用程序)的實時數據流。現在 Amazon Lambda 可與 200 多種 Amazon Web Services 服務和 SaaS 應用程序相集成。
同年,亞馬遜云科技還推出了 Amazon S3 Glacier Deep Archive,進一步按讀寫冷熱程度完善了 S3 存儲服務的智能收費檔次。
2021 年 Amazon Lambda 計費功能調整為了 1ms 級別,并且還提供了容器鏡像支持,以及 Amazon Graviton2 處理器支持,與基于 x86 的同類產品相比,Amazon Graviton2 性價比最高可提升 34%。
冷啟動和廠商鎖定
“冷啟動”的性能改善算得上是一次標志性事件。FaaS 平臺初始化函數實例需要一些時間。即使對于同一個特定的功能,不同的平臺之間這種啟動延遲可能會有很大差異,從幾毫秒到幾秒不等,取決于使用的庫、函數配置的算力等大量因素。以 Amazon Lambda 為例,Amazon Lambda 函數的初始化要么是“熱啟動”,要么是“冷啟動”。“熱啟動”是從前一個事件中重用 Amazon Lambda 函數的實例及其宿主容器,“冷啟動”需要創建一個新的容器實例,啟動函數宿主進程。在考慮啟動延遲時,“冷啟動”更受關注。
亞馬遜云科技在 2019 年提供了一項名為“預置并發(Provisioned Concurrency)” 的重要新功能,通過讓函數保持初始化狀態,從而更精確地控制啟動延遲。用戶需要做的就是設置一個值,指定平臺需要為特定功能配置多少個實例,Amazon Lambda 服務本身將確保始終有該數量的預熱實例等待工作。“冷啟動”無疑是無服務器技術批評者指出的最大問題,而亞馬遜云科技這項功能的出現,代表著關于“冷啟動”的爭議已經結束。
除此之外,“廠商鎖定”也是一個極具爭議的地方。幾年前,作為無服務器技術的反對方,CoreOS 首席執行官 Alex Polvi 稱 Amazon Lambda 無服務器產品“是我們在人類歷史上見過的最糟糕的專有鎖定形式之一”。而為 MongoDB 工作的 Matt Asay 撰文反駁他說,“完全避免鎖定的方法是自己編寫所有底層軟件(事件模型、部署模型等)”。
總之,作為支持方,很多人認為“鎖定”并不是一件非黑即白的事情,而是本身需要反復權衡的一種架構選擇。還有技術專家表示,可以采用將應用程序和平臺分離的設計方式,以及標準化技術的方法最小化遷移成本:如果使用標準化的 HTTP,那么可以使用 Amazon API Gateway 將 HTTP 請求轉換為 Amazon Lambda 事件格式;如果使用標準化的 SQL,那么使用與 MySQL 兼容 Amazon Aurora Serverless,可以自然地簡化數據庫的遷移路徑......
最佳實踐案例
發展到現在,用戶在哪些場景下會使用無服務器計算?實際上,每年的亞馬遜云科技 re:Invent 大會都會有一些團隊給大家分享實踐經驗,其中不乏具有代表性的案例。
在 2017 年的亞馬遜云科技 re:Invent 會議上,美國電信 Verizon 的 Revvel 團隊介紹了他們如何使用 Amazon Lambda 和 Amazon S3 進行視頻不同格式的轉碼。早先團隊使用的是 EC2 實例,如果視頻長達 2 小時或大到幾百 G,問題就變得很棘手,高清轉換可能需要 4-6 個小時,而轉換工作中途一旦停止或中斷就意味著前功盡棄。所以,Revvel 團隊采用的新方法是將視頻分為 5M 的小塊分別存儲在 Amazon S3 存儲桶中,然后用 Amazon Lambda 啟用上千實例并行計算,完成轉碼后再合并成一個完整的視頻,整個過程縮短到不足 10 分鐘,費用也降低到了原來的十分之一。
在 2020 年的亞馬遜云科技 re:Invent 會議上,Coca-Cola 的 Freestyle 設備創新團隊分享了他們的非接觸式售賣機解決方案:使用 Amazon Lambda 和 Amazon API Gateway 構建后端托管服務,前端使用 Amazon CloudFront ,從而可以在一周內推出原型,并在三個月內將 Web 應用程序從原型擴展到 10000 臺機器,進而在疫情期間快速占領市場。
在今年的亞馬遜云科技 re:Invent 會議主題演講里,Werner Vogels 博士講述了 New World Game 多人游戲中的無服務器解決方案。這是一款非常復雜的大規模分布式實時游戲,可處理 30 次 /s 的動作或狀態,重繪和計算需要大量的 CPU 資源。它通過每 30 秒 80 萬次寫入將用戶的狀態存儲在 Amazon DynamoDB 中,這樣用戶即使意外中斷游戲也能及時恢復到之前的游戲狀態。同時通過日志記錄用戶操作,然后使用 Amazon Kinesis 傳輸日志事件,速度可達 2300 萬事件 / 分鐘,隨后將事件流推送到 Amazon S3 中,再用 Amazon Athena 進行分析處理。利用該數據流,團隊可即時預測游戲用戶行為和更改游戲中的策略。游戲環境中的運營,比如登錄、交易、通知等操作事件,都是通過 Amazon Lambda 無服務器計算來實現的。
無服務器在這款多人游戲中發揮了非常重要的作用,但這種大型架構也對無服務器的性能提出了非常大的挑戰。Amazon Lambda 達到了每分鐘 1.5 億次的調用頻率,這比行業里的平均水準高出數倍。

3.無服務器的未來
在今年年底,亞馬遜云科技一口氣推出了五款無服務器產品:
Amazon Redshift Serverless,可自動配置計算資源,使用 SQL 跨數據倉庫、運營數據庫和數據湖分析結構化和非結構化數據。
Amazon EMR Serverless(預覽版),是 Amazon EMR 中的一個新選項,讓數據工程師和分析師能夠借助開源分析框架,例如 Apache Spark、Hive 和 Presto,在云中運行 PB 級數據分析。
Amazon MSK Serverless(公開預覽版),全新類型的 Amazon MSK 集群,完全兼容 Apache Kafka,且無需管理 Kafka 的容量,服務會自動預置和擴展計算及存儲資源。
Amazon Kinesis On-demand,用于大規模實時流數據處理,服務會自動按需擴展和縮減。
Amazon SageMaker Serverless Inference(預覽版),讓開發者無需配置或管理底層基礎設施即可部署機器學習模型進行推理,按執行時間和處理的數據量付費。
由此,我們可以看到云上的 Serverless 服務越來越多,無服務器計算的能力已經從計算、存儲、數據庫服務擴展到數據分析,以及機器學習的推理。以前機器學習的推理需要啟動大量的資源來支撐峰值請求。如果使用 EC2 推理節點,空閑資源會推高成本,而使用 Amazon Lambda 服務,就不需要再考慮集群節點管理這些事情,服務會根據 Workload 自動預置、擴展和關閉計算容量,只為執行時間和處理的數據量付費,相比之下能節省很多。
Amazon Serverless 服務在不斷進化的同時,計算架構也在不斷改進,比如用戶可以將原來的 Intel x86 處理器,通過平臺提供的選項配置為 Amazon Graviton2 ARM 處理器,性能更快且能便宜 20%。有技術專家認為,平臺也會朝著更智能的方向發展,“現在需要用戶改配置選擇更便宜的 ARM 處理器,未來服務完全可以做到自動選擇計算平臺。”
作為云計算的一種演進方式,無服務器的愿景必定會改變我們對編寫軟件的看法。以前從來沒有一種方法可以像云計算這樣考慮如何使用數百萬個處理器內核和 PB 級內存進行設計,而現在無服務器已經進入到通用和可用的階段,用戶無需考慮如何管理這些資源。
就像 Werner Vogels 博士在主題演講里講的那樣:“如果不用云計算,這些大型架構根本無法實現。所以現在,用屬于 21 世紀的架構去隨心構建你夢想的系統吧(Build systems the way you always wanted to,but never could)。”








 京公網安備 11010502049343號
京公網安備 11010502049343號