


你看看人家阿強,
差點就把后半輩子規劃想好了
▼
阿強:鑒于對未來一片迷茫,我已經想好了后半輩子的人生規劃...
李小男:哇,受什么刺激了?
阿強:公司在規劃5G戰略,可我一想到Lambda應對流數據的能力就開始發愁。佛了,X煙、喝酒、植發,這大概就是我今后的人生三件大事......
李小男:聽過那個“藍鳥”沒有?
阿強:姐,就別拿我開玩笑了...還藍鳥?下輩子的房貸都在愁呢
李小男:Pravega去了解一下,你會回來感謝我的~
30分鐘后...
阿強:姐,我復活了,未來,充滿信心!
李小男:先別急著激動,還沒謝謝我吶
然鵝
僅僅拯救這個阿強還不夠
因為,還有無數個阿強在等待
看完這篇文章
救救你身邊的阿強!
▼
上一期內容我們講到:5G時代到來,無處不在的物聯網、自動駕駛汽車等在邊緣產生的數據源源不斷,就像開著的水管,數據源一直流出,由此誕生了新的數據類型即“流數據”。然而,無論Hadoop還是Lambda,都無法勝任新數據環境下的要求,因為計算是原生的流計算,而存儲卻不是原生的流存儲。(上一期文章)
針對流數據的應用場景,流數據存儲需要滿足低延時、僅處理一次、順序保證、檢查點這四點要求。
因此戴爾科技集團IoT部門的團隊重新思考了流式數據處理和存儲規則,為流數據場景設計了新的存儲類型,即原生的流存儲,并由此誕生了“Pravega”。
于是今天我們把目光聚焦Pravega,來一次Deep Dive,潛入深海,重點介紹Pravega的特點與優勢,看它是如何解決新數據環境下的流數據問題。
▼▼▼
作者簡介

滕昱
滕昱:就職于Dell EMC中國研發集團,非結構化數據存儲部門團隊并擔任軟件開發總監。2007年加入Dell EMC以后一直專注于分布式存儲領域。參加并領導了中國研發團隊參與兩代Dell EMC對象存儲產品的研發工作并取得商業上成功。從2017年開始,兼任Streaming存儲和實時計算系統的設計開發與領導工作。

周煜敏
周煜敏:復旦大學計算機專業研究生,從本科起就參與Dell EMC分布式對象存儲的實習工作。現參與Flink相關領域研發工作。

吳長平
吳長平:現就職于Dell EMC,10年+存儲、分布式、云計算開發以及架構設計經驗,現從事流存儲和實時計算系統的設計與開發工作。
Pravega,取梵語中“Good Speed”之意,其設計宗旨是成為流的實時存儲解決方案。它屬于戴爾科技集團IoT戰略下的一個子項目。該項目是從0開始構建,用于存儲和分析來自各種物聯網終端的大量數據,旨在實現實時決策。其結合了戴爾易安信PowerEdge服務器,并無縫集成到非結構化數據產品組合Isilon和Elastic Cloud Storage(ECS)中,同時擁抱Flink生態,以此為用戶提供IoT所需的關鍵平臺。
針對上面說到的四點要求,從訪問模式角度來說,Pravega統一了傳統批數據和流數據,因此不僅可以實時到達數據的低延時 (low latency) 讀和寫,還可以滿足對于歷史數據的高吞吐 (high throughput) 的讀。

技術在某種程度上一定是來自此前已有技術的新的組合。
——《技術的本質》,布萊恩•阿瑟
當然,Pravega 也不是憑空發明出來的,它也是以前的成熟技術與新技術的組合。Pravega團隊擁有基于日志存儲的設計經驗,也擁有Apache ZooKeeper/BookKeeper的項目歷史,加之大量實時系統同樣也采用日志存儲的方式來完成實時應用的消息隊列,想要滿足尾讀、尾讀和追趕讀這三種據訪問模式,自然想到了使用僅附加 (Append Only) 的日志作為存儲原語。
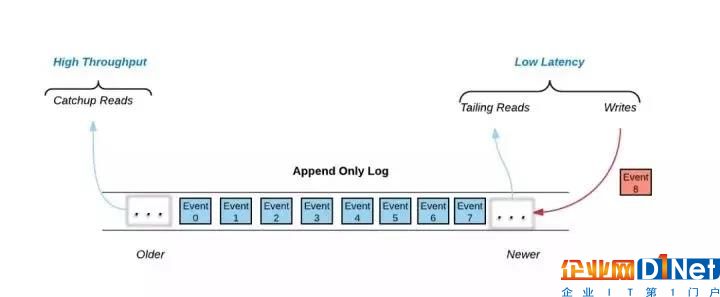
圖 1. 日志結構的三種數據訪問機制
如圖1所示:在Pravega里,日志是作為共享存儲原語而存在的,數據以事件 (event) 的形式以僅附加的方式寫入日志當中。
所有寫入操作以及大部分讀取操作都發生在日志的尾部 (tail read/write)。寫操作將事件附加到日志中,而大量讀客戶端希望以到達日志的速度讀取數據。這兩種數據訪問機制主要是需要低延遲。
對于歷史數據的處理,讀客戶端不從日志的尾部讀取,而是從日志中的任意位置開始讀。這些讀取稱為追趕讀 (catch-up read)。我們可以采用和尾部數據一樣的高性能存儲(例如SSD)來存儲歷史數據,但這會非常昂貴并迫使用戶通過刪除歷史數據來節省成本。這就需要Pravega架構提供一種機制,允許客戶在日志的歷史部分使用經濟高效,高度可擴展的高吞吐量存儲,這樣他們就能夠保留所有的歷史數據,來完成對一個完整數據集的讀取。
Pravega支持僅一次處理 (exactly-once),可在Kappa架構上實現鏈接應用需求,以便將計算拆分為多個獨立的應用程序,這就是流式系統的微服務架構。我們所設想的架構是由事件驅動、連續和有狀態的數據處理的流式存儲 - 計算的模式(如圖 2)。

圖 2.流處理的簡單生命周期
通過將Pravega流存儲與Apache Flink有狀態流處理器相結合,上圖中的所有寫、處理、讀和存儲都是獨立的、彈性的,并可以根據到達數據量進行實時動態擴展。這使我們所有人都能構建以前無法構建的流式應用,并將其從測試原型無縫擴展到生產環境。擁有了Pravega,Kappa架構得以湊齊了最后的拼圖,形成了統一存儲、統一計算的閉環。
Pravega 邏輯架構
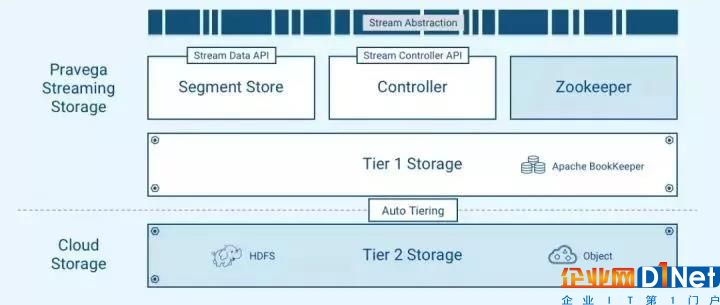
圖 3. Pravega架構
為了實現上述的三種訪問模式的性能需求,Pravega采用了如圖3所示的分層存儲架構。事件可以存儲在低延遲/高 IOPS的存儲(第一層存儲)和更高吞吐量的存儲(第二層存儲)中。通過這種方式,冷熱數據分離有效降低了數據存儲成本。上層使用Apache ZooKeeper作為分布式協調器,并提供統一的Stream抽象。
第一層存儲
第一層存儲用于快速持久地將數據寫入Stream,并確保從Stream的尾讀盡可能快。第一層存儲基于開源Apache BookKeeper項目。BookKeeper是一種底層的日志服務,具有高擴展、強容錯、低延遲等特性。許多Apache開源項目,例如Apache Pulsar,Apache DistributedLog都是基于這一項目實現。BookKeeper對于復制、持久性、一致性、可用性、低延時的承諾也正是Pravega所需要的第一層存儲的需求。為達到高性能的讀寫延遲需求,我們建議第一層存儲通常在更快的 SSD 或甚至非易失性存儲 (non-volatile RAM) 上實現。
第二層存儲
第二層存儲考慮到經濟效益,選用高度可擴展,高吞吐量的云存儲,目前Pravega支持HDFS,NFS和S3協議的二級存儲,用戶可以選用支持這些協議的大規模存儲進行擴展。Pravega提供了兩種數據降層 (retention) 的模式,一種基于數據在Stream中保留的時間,另一種基于數據在Stream中存儲的容量大小。Pravega會異步將事件從第一層遷移到第二層,而讀寫客戶端將不會感知到數據存儲層級的變化,依然使用同樣的Stream抽象操作數據的讀寫。
正是基于這樣的分層模型,大數據處理的降低開發成本、減少存儲成本與減少運維成本這三大問題被Pravega一次性解決了。
? 對開發者而言,只需要關心Stream抽象的讀寫客戶端的操作。實時處理和批處理不再區分對數據訪問方式,由此提升了效率,帶來開發成本的降低。
? 數據僅在第一層存儲有三份拷貝,在第二層存儲則可以通過商業分布式 / 云存儲自身擁有的高可用、分布式數據恢復機制(如 Erasure Coding)進一步降低存儲系數,達到比公有云存儲更便宜的總體擁有成本 (TCO)。
? 所有的存儲組件歸結為統一的Pravega,組件僅包括Apache ZooKeeper,Apache BookKeeper以及可托管的第二層存儲,運維復雜程度大大降低。Pravega還提供了額外的“零運維”自動彈性伸縮特性,進一步減輕了數據高峰期的運維壓力。
Pravega 產Pravega 產品定位和與 kafka 的對比比
讓我們以當今業界應用最廣的分布式消息系統Apache Kafka作為對比,看看Pravega如何實現了今天存儲無法實現的方式。
Pravega是從 存儲的視角 來看待流數據,而Kafka本身的定位是消息系統而不是存儲系統,它是從 消息的視角 來看待流數據。消息系統與存儲系統的定位是不同的,簡單來說,消息系統是消息的傳輸系統,關注的是數據傳輸與生產消費的過程。Pravega的定位是企業級的分布式流存儲產品,除了滿足流的屬性之外,還需要滿足數據存儲的持久化、安全、可靠性、一致性、隔離等屬性,關注數據的生產、傳輸、存放、訪問等整個數據的生命周期。作為企業級的產品,一些額外的特性也有支持,例如:數據安全、多租戶、自動擴縮容、狀態同步器、事務支持等,部分特性將在后續文章詳述。
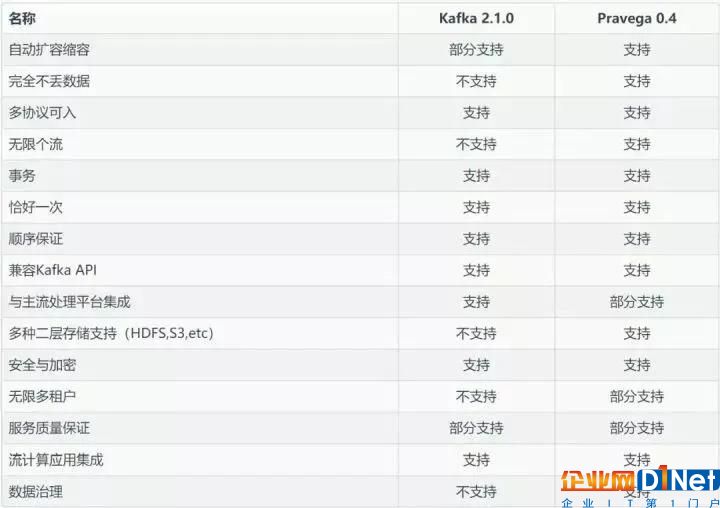
這里我們把Pravega與Kafka做了對比,大體在功能上的差異如下表所示。功能上的差異也只是說明各個產品針對的業務場景不同,看待數據的視角不同,并不是說明這個產品不好,另外每個產品自身也在演進,因此本對比僅供參考。
總結:
本期內容我們主要介紹了重點介紹了Pravega的關鍵架構以及關鍵特性,以及它能給開發人員和公司帶來的優勢,并與Kafka做了簡要對比。下一期的“IoT前沿”中,我們將重點介紹Pravega的伸縮性,并通過相關案例來輔助說明,歡迎大家持續關注,如何你有疑問,可以在下方進行留言或在知乎號上找到我們(見下方二維碼)我們將為你答疑解惑。下一期見~

掃碼關注知乎號
你和戴爾易安信專家只有一條網線的距離~








 京公網安備 11010502049343號
京公網安備 11010502049343號