









機器學習正快速成為物聯網(IoT)設備不可分割的特征。家用電器開始裝備可以智能地回應自然語音的語音驅動接口。機器人開始通過智能手機相機上的演示視頻學習如何在工廠車間移動材料并為其他機器編程。同時,智能手機變得更加智能。這些應用都充分利用了迄今為止最為成功的復雜多維數據人工智能體系結構——深度神經網絡(DNN)。
智能進入前端設備
到目前為止,嵌入式系統DNN技術應用的一個難題一直是它對計算性能的高要求。在輸入數據被傳遞到經過訓練的DNN進行識別和分析的推理階段,需要的運算量雖然比訓練階段少,但語音、視頻等流數據仍然需要每秒數十億次計算。因此,在很多情況下,處理被轉移到有足夠運算能力的云端。但對于前端設備,這并非理想的解決方案。
自動駕駛車輛和工業機器人等關鍵任務,需要利用DNN實時識別物體的能力來提高態勢感知。但云計算存在延遲、帶寬和網絡可用性等問題。在此情況下,得不到云端實時響應的風險是用戶無力承擔的。
隱私是另一個問題。盡管消費者認為智能揚聲器等設備提供的語音幫助服務很方便,但他們也越來越擔心,如果他們的語音錄音被定期轉移到云端,可能導致個人信息的意外泄漏。隨著配備攝像頭的智能揚聲器和可視機器人助手的出現,這類擔憂將變得更加嚴重。為了安撫客戶,制造商正在研究如何將更多的DNN處理功能遷移到前端設備。他們所面臨的主要問題是DNN處理不適合傳統嵌入式系統的架構。
常規嵌入式處理器不足以應對DNN處理
對于低功耗設備,基于CPU和GPU的傳統嵌入式處理器無法有效地承擔DNN工作負載。物聯網和移動設備對功率和面積有非常嚴格的限制,而高性能對于實時DNN處理是必要的。電源、性能和面積三要素(簡稱PPA)必須實現最優化,才能應對當前的任務。
解決這些問題的一種方法是為可以訪問芯片內置存儲器陣列的DNN處理提供硬件電路引擎。這種方法的問題是開發人員需要高度的靈活性。每個DNN設計的結構都需要根據目標應用進行調整。為語音識別設計和訓練的DNN的卷積、合并和完全連接層的組合將不同于視頻用途的DNN。由于機器學習仍然是一項不斷發展的新興技術,面向未來的解決方案必須具有靈活性。
另一種常用的方法是給標準處理單元添加矢量處理單元(VPU),這可以確保更高效的計算以及處理不同類型網絡的靈活性。但這仍然不夠。對于DNN處理而言,從外部DDR存儲器讀取數據是相當耗電的任務。因此,為了確保整體解決方案,還必須考慮數據效率和內存訪問。為了最大限度地提高效率、可擴展性和靈活性,VPU只是AI處理器所需的關鍵模塊之一。
實現最佳帶寬和吞吐量
為了滿足這些要求,CEVA創造了一種架構,它既可以滿足DNN的性能挑戰,又能保證處理各種嵌入式深度學習應用所需的靈活性。 NeuPro AI處理器包括經過優化的專用深度神經網絡推理硬件引擎,用于處理卷積、完全連接、激活和合并層。此外,它還利用功能強大的可編程VPU來處理未支持層類型和推理軟件執行。該架構與CEVA深度神經網絡(CDNN)軟件框架配套,該框架可以以圖形化界面即時生成執行。
為了確保數據效率,CEVA-NeuPro架構采用特別技術最小化存儲器訪問量并優化數據在不同層之間的流動。它完全支持即時傳播,并將所有中間網絡層保留在本地內存中,從而實現最少的DDR訪問。它使用的另一種技術是通過盡量重復使用已加載數據來減少從本地內存讀取數據。這些組件的結合創造了具有最佳PPA(高性能、低功耗和高面積效率)的完整DNN解決方案。
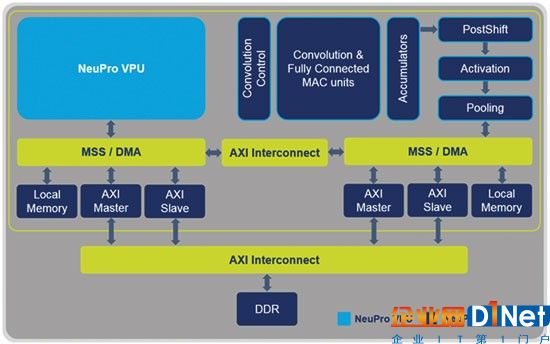
更多的性能優化通過對8位和16位運算的兼容實現。某些計算需要16位運算的準確性。在其他情況下,使用8位計算可以獲得幾乎相同的結果,而且可以大幅減少工作量,從而降低功耗。 NeuPro引擎可以在這些操作之間實現均衡,從而使每個層都得到最佳執行,實現兼具高精度和高性能的兩全其美的結果。

經過優化的硬件模塊、VPU和高效內存系統相結合,共同創造出靈活高效的可擴展解決方案。此外,CDNN通過一鍵式網絡轉換和隨時可用的庫模塊實現簡化的開發。所有一切造就了一款性能全面的AI處理器,它賦予物聯網設備設計人員將本地化機器學習充分應用到下一代產品中的能力。
















 京公網安備 11010502049343號
京公網安備 11010502049343號