


2018年下半年,UCloud首爾數據中心因外部原因無法繼續提供服務,需要在很短時間內將機房全部遷走。為了不影響用戶現網業務,我們放棄了離線遷移方案,選擇了非常有挑戰的機房整體熱遷移。經過5個月的多部門協作,終于完成了既定目標,在用戶無感知下,將所有業務完整遷移到同樣位于首爾的新機房內。
本文將詳述這個大項目中最有難度的工作之一:公共組件與核心管理模塊遷移的方案設計和實踐歷程。
計劃
整個項目劃分為四個大階段:準備階段、新機房建設、新舊遷移和舊機房裁撤下線。正如一位同事的比喻,機房的熱遷移,相當于把一輛高速行駛高鐵上的用戶遷移到另一輛高速行駛的高鐵上,高鐵是我們的機房,高鐵上的用戶是我們的業務。要讓遷移可行需要兩輛高鐵相對靜止,一個方法是把兩輛高鐵變成一輛,如此兩者速度就一致了。UCloud機房熱遷移采用類似方案,把兩個機房在邏輯上變成一個機房。為此,上層的業務邏輯要在新老機房間無縫遷移,下面的管理系統也要統一成一套。

其中,我們SRE和應用運維團隊主要負責以下幾個工作:1)機房核心ZooKeeper服務的擴縮容服務;2)核心數據庫中間層udatabase服務的部署和擴容;3)大部分管理服務的部署和遷移;4)核心數據庫的部署和遷移。以上涉及到前期規劃、方案設計、項目實施、穩定性保證、變更校驗等所有方面。
挑戰
我們剛接到機房整體熱遷移需求時,著實有些頭疼,首爾機房屬于較早期部署的機房之一,相關的技術架構比較老舊。而核心數據庫、核心配置服務(ZooKeeper)、核心數據庫中間層(udatabase)等幾個服務都是比較重要的基礎組件,老舊架構可能會因為基礎層面的變動發生復雜的大范圍異常,從而影響到存量用戶的日常使用。
幸好SRE團隊在過去一年里,針對各種服務的資源數據進行了全面的梳理,我們開發了一套集群資源管理系統(Mafia-RMS) ,該系統通過動態服務發現、靜態注冊等多種手段,對存量和增量的服務資源進行了整理,每一個機房有哪些服務和集群,某個集群有哪些服務器、每一個實例的端口/狀態/配置等信息,都記錄到了我們的資源管理系統中,如下圖所示:
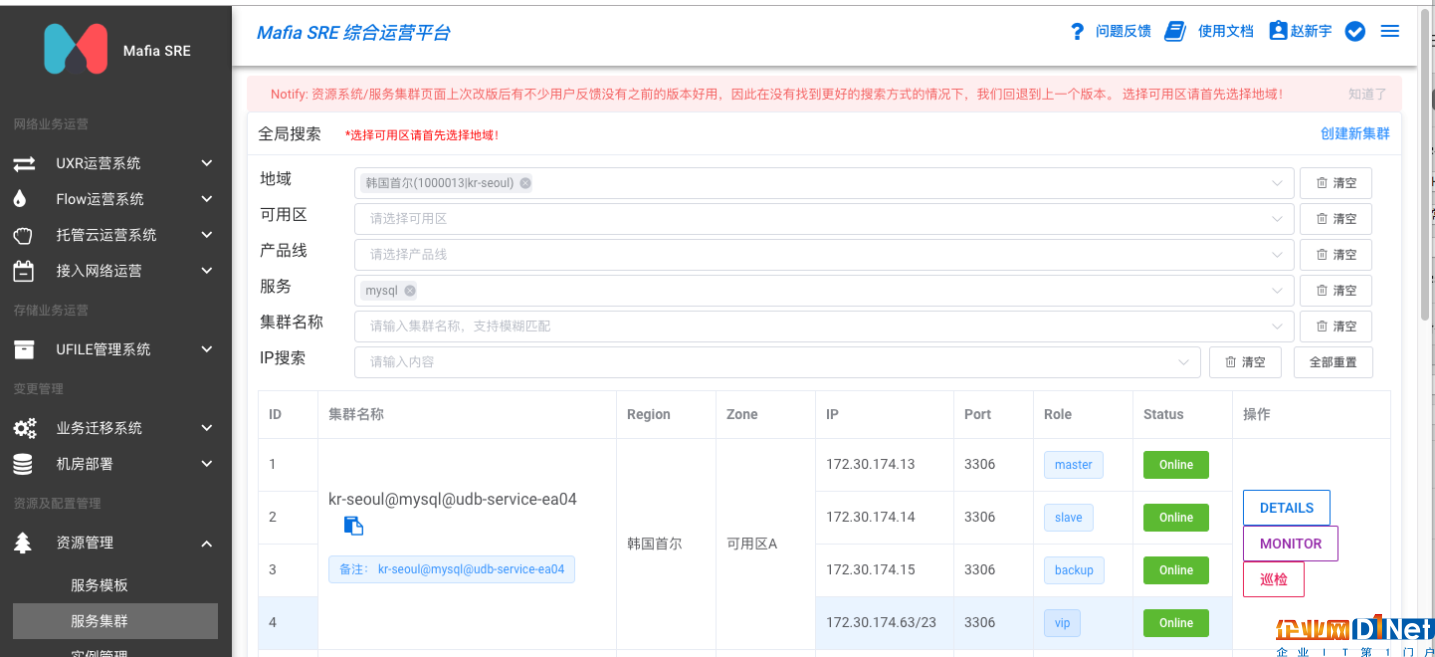
圖1: UCloud SRE資源管理系統-集群管理功能
通過SRE資源管理系統,可以清楚地知道首爾機房存量內部服務的集群信息、每個實例的狀態。我們基于SRE資源系統還構建了基于Prometheus的SRE監控體系,通過上圖右側Monitor按鈕就可以跳轉到監控頁面,獲取整個業務的實時運行狀況。
有了這些資源數據之后,剩下的就是考慮怎么進行這些服務的擴容和遷移工作。
ZooKeeper服務的擴縮容
首先是內部服務注冊中心ZooKeeper的擴縮容。
UCloud內部大規模使用ZooKeeper作為內部服務注冊和服務發現中心,大部分服務的互訪都是通過使用ZooKeeper獲取服務注冊地址,UCloud內部使用較多的wiwo框架(C++) 和 uframework (Golang) 都是基于主動狀態機定時將自己的Endpoint信息注冊到ZooKeeper中,相同Endpoint前綴的服務屬于同一個集群,因此對于某些服務的擴容,新節點使用相同的Endpoint前綴即可。wiwo和uframework兩個框架的客戶端具備了解析ZooKeeper配置的能力,可以通過對Endpoint的解析獲取到真實的IP和端口信息。然后通過客戶端負載均衡的方式,將請求發送到真實的業務服務實例上去,從而完成服務間的相互調用。如下圖所示:
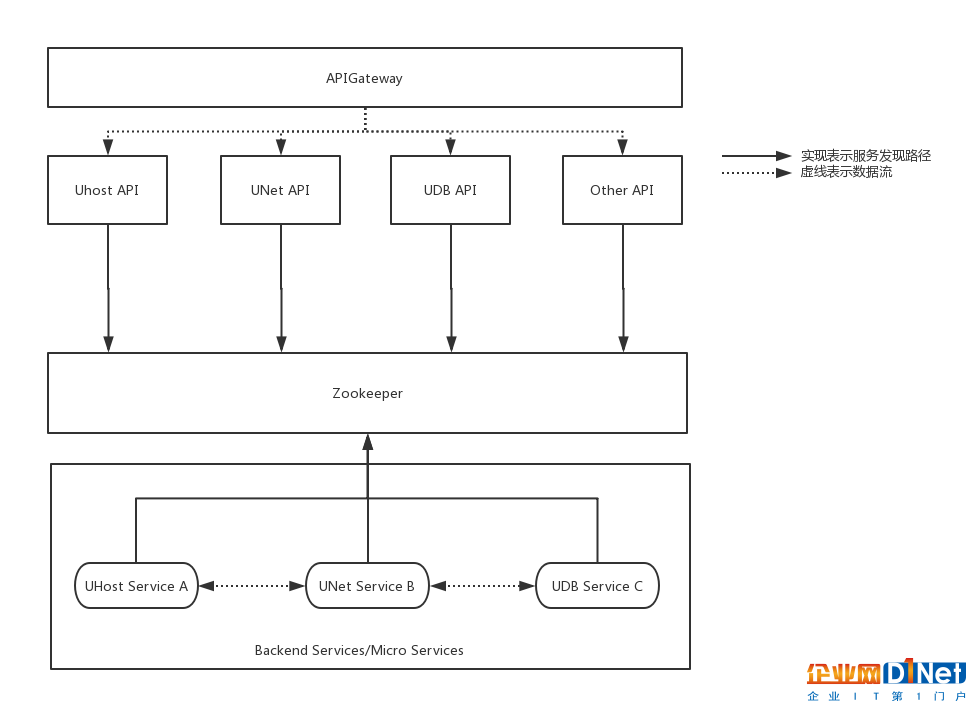
圖2:UCloud 首爾機房部署調用及服務注冊/發現路徑圖
首爾老機房的ZooKeeper集群是一個具有3個節點的普通集群(當時規模相對較小,3個節點足夠)。 然而首爾新機房的規模要大很多,因此新機房ZooKeeper的集群規模也要擴充,經過我們的評估,將新機房的ZooKeeper集群擴充到5個節點,基本上可以滿足所需。
其實,一個理想的遷移架構應該是如圖3所示,整個新機房使用和老機房相同的技術架構(架構和版本統一),新架構完全獨立部署,與老機房并沒有數據交互工作,而用戶的業務服務(如UHost/UDB/EIP/VPC等)通過某種方式平滑的實現控制和管理面的遷移,以及物理位置的遷移工作。
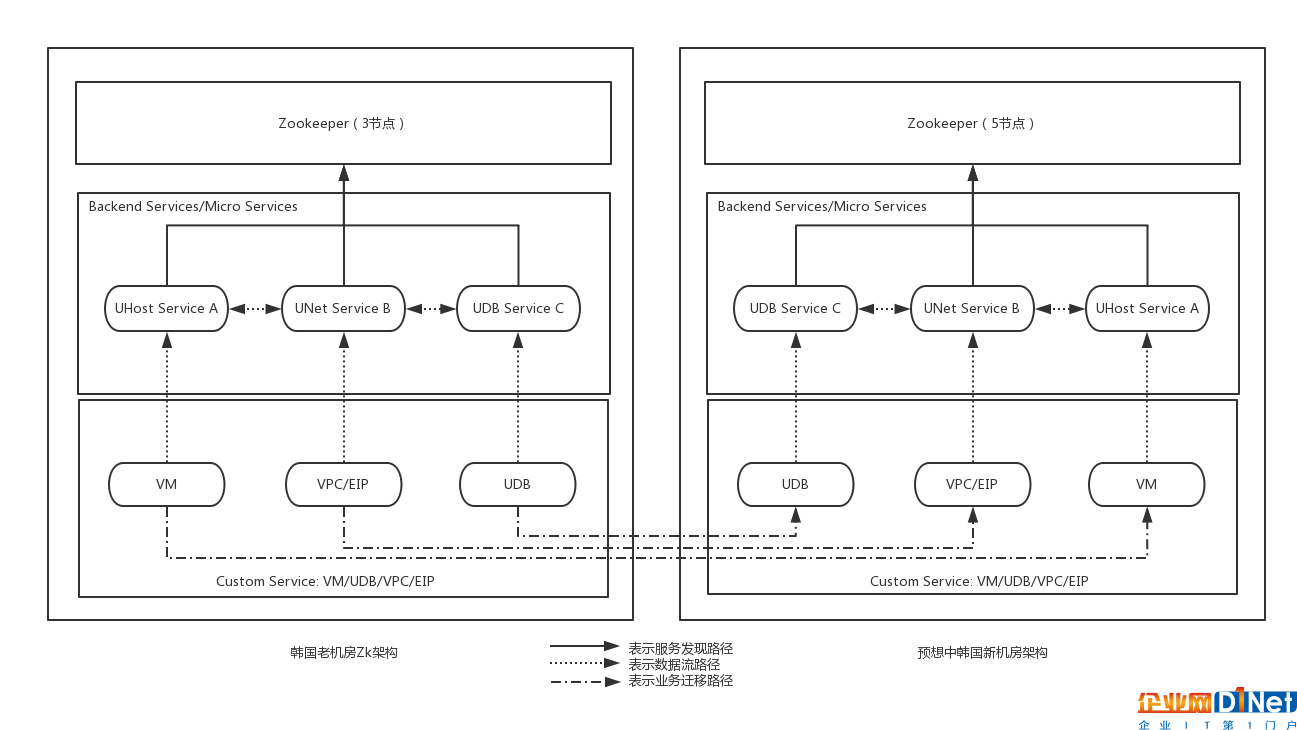
圖3:理想狀態下的老舊機房服務遷移示意圖
但是理想狀態在現實中無法達到,內部架構和代碼邏輯的限制,導致業務實例無法平滑實現邏輯和控制層面的遷移,更何況物理層面的遷移。新部署的管理服務需要和老機房的管理服務進行通信,因此,我們調整了新機房服務的部署架構,并適配實際情況分別使用兩種部署模式,如圖4和圖5所示:
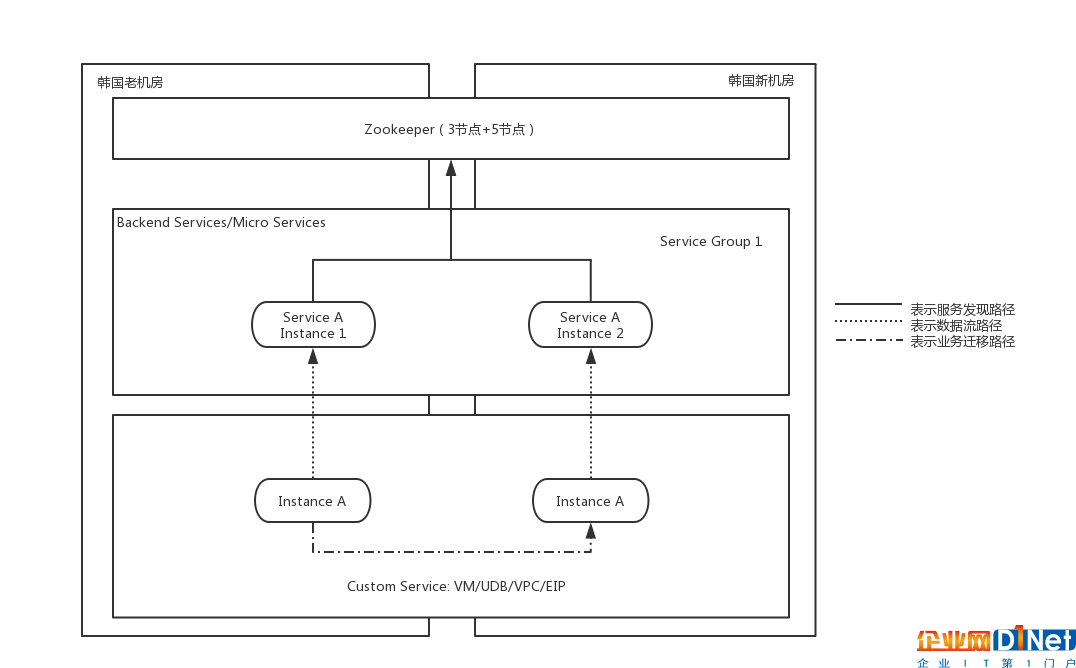
圖4: 同集群擴容模式的跨機房服務部署
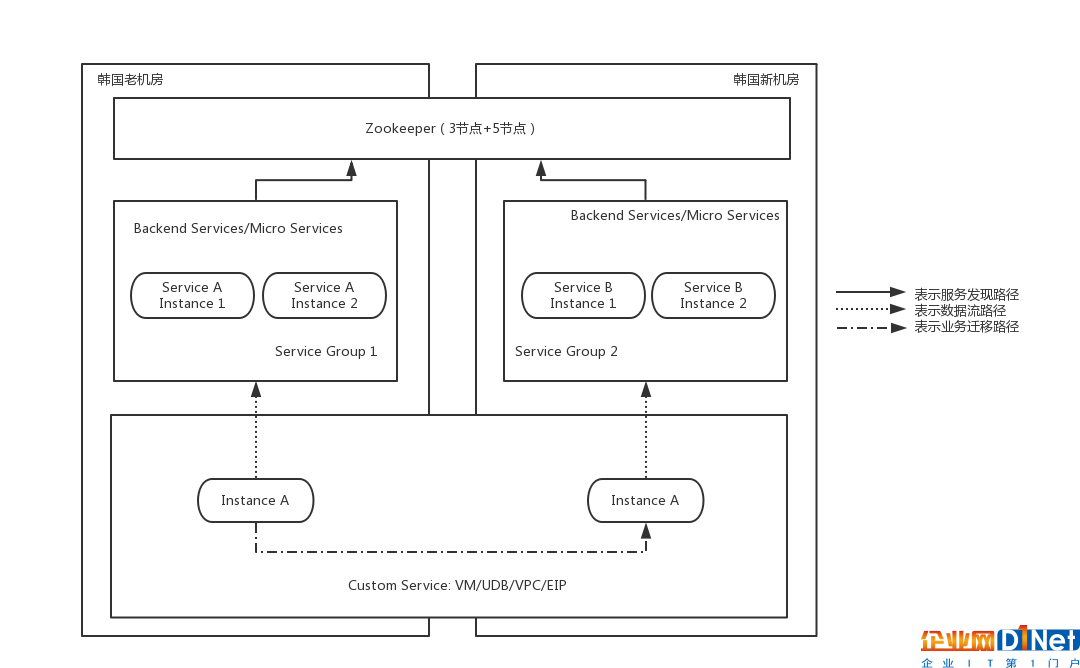
圖5: 新建集群灰度遷移模式的跨機房服務部署
無論是圖4的同集群擴容模式,還是圖5的新建集群灰度遷移模式,在ZooKeeper層面必須讓新舊機房的ZooKeeper集群處于一體的狀態,需要兩個集群的數據一致、實時同步。因此在ZooKeeper的技術層面,必須將這兩個集群變成一個集群,將原有的3節點的ZooKeeper集群,經過異地機房擴容的方式擴充到8個節點(1個leader,7個follower),只有這種模式下數據才能夠保持一致性和實時性。
而對于新機房新部署的需要注冊的服務來說,他們的配置文件中對于ZooKeeper地址的配置,卻不是新建的8個IP的列表,而是只配置新機房5個IP的列表。這樣新老機房的后端服務使用同一套ZooKeeper,但是配置的卻是不同的IP,這樣做的目的,是為了后續老機房下線裁撤時,所有新機房的服務不需要因為ZooKeeper集群的縮容而重啟更新配置,只要將集群中老機房所在的3個節點下線,剩余5個節點的配置更新重新選主即可。
因此在ZooKeeper的機房擴容方案上,我們采用了先同集群擴容后拆分的模式。ZooKeeper的擴容是整個機房擴建的第一步,后續所有的服務都會依托于該操作新建的5個節點的ZooKeeper配置;而ZooKeeper集群的縮容是最后的操作,待所有的服務都擴容完成,所有業務實例遷移完成之后,將ZooKeeper集群進行縮容重新選主,這樣即可完成整個機房的裁撤。
數據庫中間層udatabase的遷移
接下來是數據庫中間層udatabase的遷移工作。
圖4和圖5兩種模式對于ZooKeeper的處理方式是相同的,不同點在于后端對于內部管理和控制面服務的擴容遷移方式。udatabase遷移使用圖4模式,這種模式下相當于在原有的集群進行異地機房擴容,擴容的新實例使用和原有集群相同的Endpoint前綴,也就是說它們是屬于同一個集群,當服務啟動后,新擴容的實例的狀態會與原有集群的實例相同,框架(wiwo或uframework)層會通過客戶端方式從ZooKeeper中發現到該集群節點的變化(新增),同時使用某種負載均衡算法將請求流量路由到新的節點上。這樣屬于同一個集群,但卻處于兩個地址位置的實例都有部分流量,而進行縮容的方式就是直接將老機房同集群的服務下線即可,這樣客戶端就會將所有該集群的流量都轉發到新機房擴容的節點上,從而完成平滑的服務擴容。udatabase通過這樣的方式完成了集群的遷移過程。
新建集群灰度遷移模式
其實圖4模式對于大部分服務來說都是可行的,但為什么還出現了圖5所示的新建集群灰度遷移模式呢?因為某些場景下圖4會有一定的不可控性。假如新建的實例(如圖4中Service A Instance 2)存在軟件穩定性和可靠性的問題,比如配置異常、軟件版本異常、網絡異常,可能導致路由到新節點的請求出現問題,會直接影響在線業務,影響的規模由擴容的節點占集群總節點的比例決定,像我們這種1:1的擴容方式,如果服務有問題可能50%的請求就直接異常了。udatabase使用圖4方案,是因為其代碼的穩定性比較高,功能和配置比較簡單,主要依托于其高性能的轉發能力。
而對于某些功能邏輯都比較復雜的業務來說(如ULB/CNAT),就使用了更穩妥的圖5模式,由于業務層面支持跨集群遷移,因此可以新建一個全新的無業務流量的集群,該集群在ZooKeeper中的Endpoint路徑前綴和原有的集群不相同,使用一個全新的路徑,然后在業務層面,通過遷移平臺或工具,將后端服務或實例按需遷移,整個過程可控,出現問題立刻回滾,是最安全的遷移方案。我們通用的灰度遷移平臺SRE-Migrate如圖6所示。
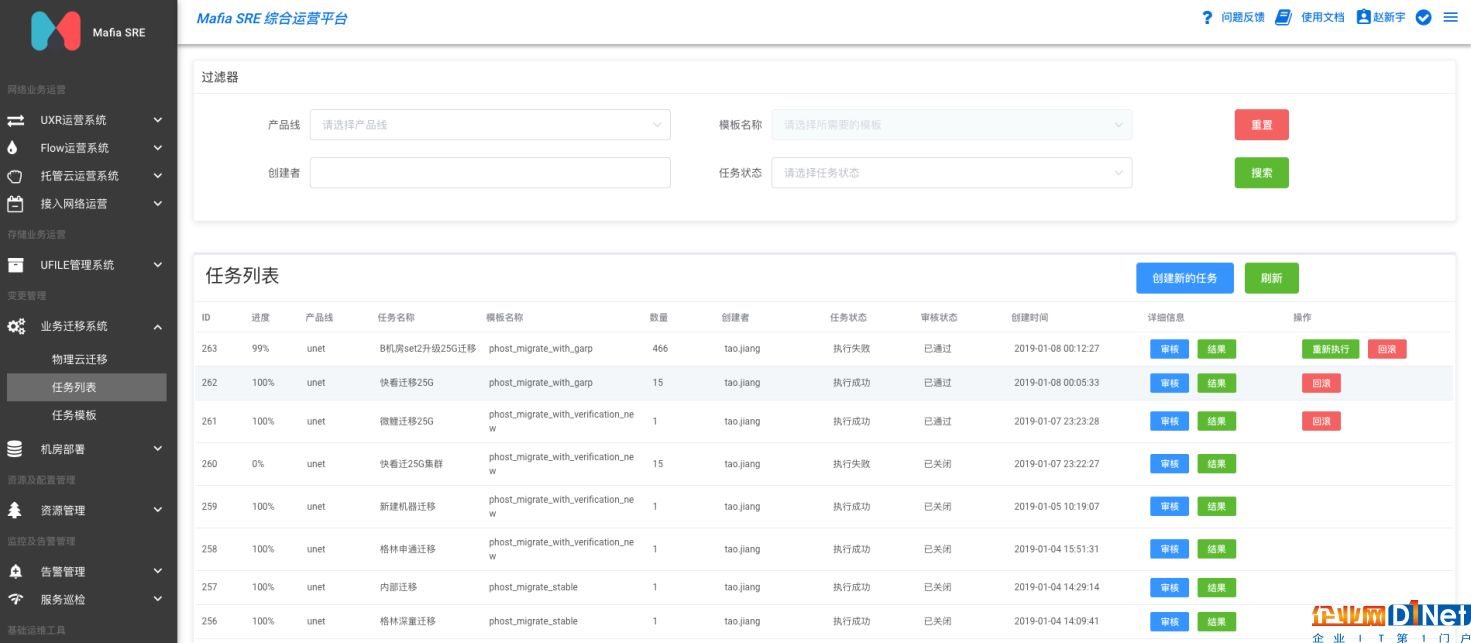
圖6 UCloud內部通用業務遷移系統SRE-Migrate
機房部署平臺SRE-Asteroid
UCloud產品線和產品名下服務數量繁多,無論是圖4還是圖5的方案,都需要大量的服務部署工作。SRE團隊在2018年中推進的機房部署優化項目,意在解決UCloud新機房建設(國內及海外數據中心、專有云、私有云等)交付時間長和人力成本巨大的問題,2018年底該項目成功產品化落地,覆蓋主機、網絡等核心業務近百余服務的部署管理,解決了配置管理、部署規范、軟件版本等一系列問題。首爾機房遷移也正是利用了這一成果,才能夠在很短的時間內完成近百個新集群的部署或擴容工作,圖7所示就是我們的新機房部署平臺 SRE-Asteroid。
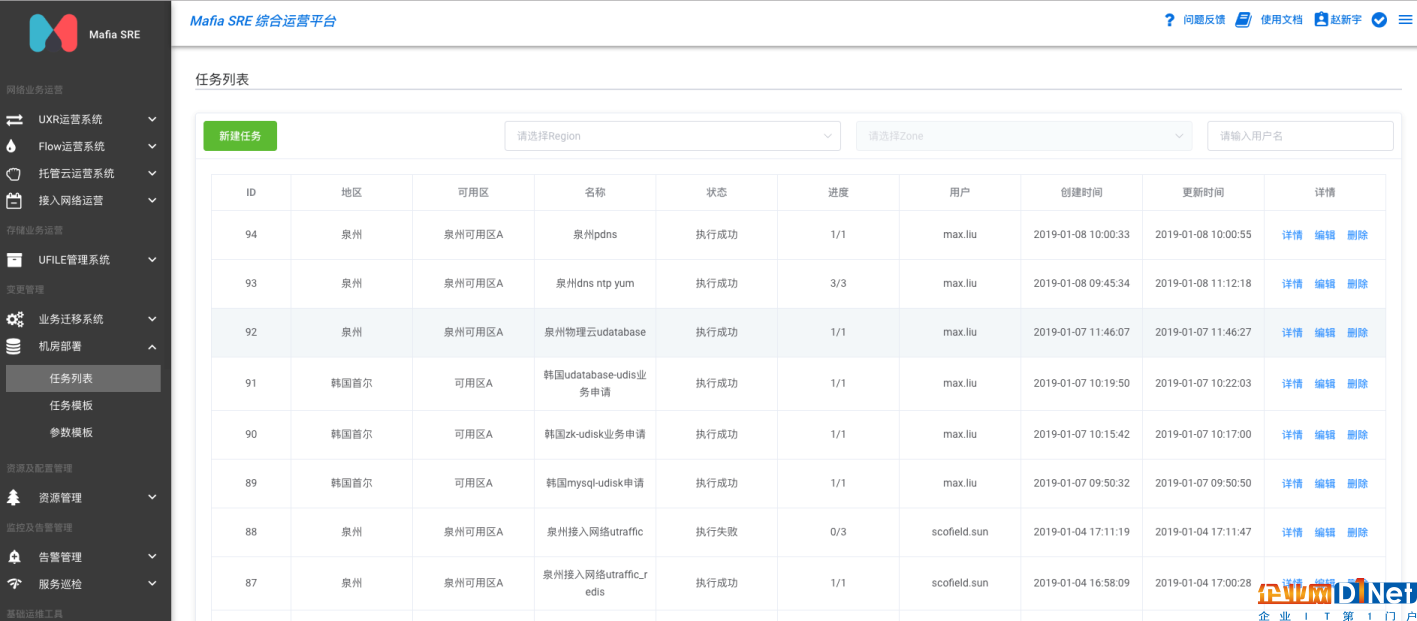
圖7 UCloud內部機房部署平臺SRE-Asteroid
核心數據庫的部署和遷移
最后,是核心數據庫層面的部署和遷移工作如何進行。UCloud內部服務所使用的數據庫服務為MySQL, 內部MySQL集群采用物理機/虛擬機在管理網絡內自行建設,以一個主庫、一個高可用從庫、兩個只讀從庫和一個備份庫的方式部署,使用MHA+VIP的方式解決主庫的高可用問題,使用BGP/ECMP+VIP的方式解決從庫的負載均衡和高可用問題,大體的架構如圖8所示:
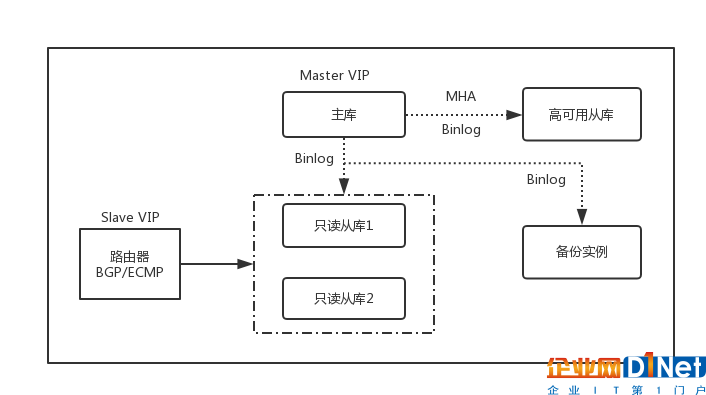
圖8 UCloud內部MySQL服務架構圖
首爾新老機房使用的內部MySQL數據庫集群的架構跟上圖類似,為了進行新老機房的集群切換,我們設計了如下的方案,如圖9所示:
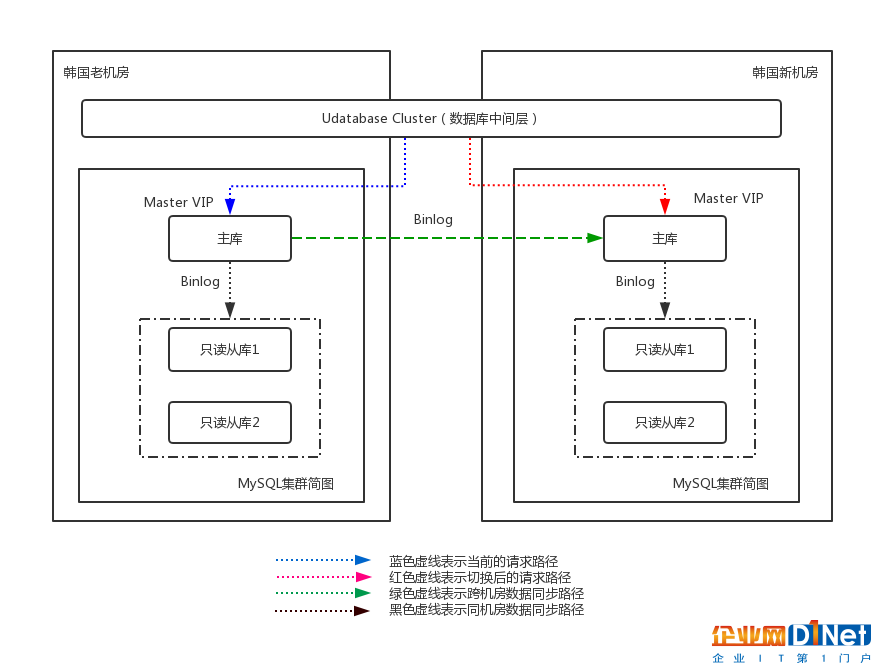
圖9 首爾集群內部數據庫集群遷移示意圖
整體來說,為了保證核心數據庫集群能夠穩定完成遷移工作,我們拋棄了雙主庫、雙寫的切換方案,防止因為網絡或其他因素導致新老集群的數據不一致、同步異常等問題。我們采用了最簡單的解決方案,在業務低峰期停止Console服務,直接修改數據庫中間層配置切換的方案。
在部署階段,我們在首爾新機房部署了相同高可用架構的MySQL集群,老機房的數據庫邏輯備份導入,將新老機房的集群做成級聯模式(圖9中綠色虛線),新機房的主庫作為老機房的從庫,通過MySQL異步同步的方式(binlog)進行數據同步。我們使用pt-table-checksum工具,定期對兩個集群的數據一致性進行校驗,以保證新老機房的數據完全一致。與此同時使用內部開發的拓撲分析工具,將所有調用老集群數據庫主從庫的業務情況確認清楚(主要是哪些udatabase集群)。
部署完成后,數據一致性和實時性通過級聯得到保障,udatabase仍然訪問老機房的MySQL主庫的VIP(圖9藍色虛線),此時并沒有業務通過直連的方式寫入新機房的主庫(為保證數據的一致性,新機房的主庫暫時設置成只讀模式)。
在確定遷移時間和遷移方案之后,在某個業務低峰期的時間點,公告用戶后,首爾機房整個console的操作停止一段時間(期間首爾機房的API請求可能會失敗),在確定流量很低的前提下,通過修改數據庫中間層(udatabase cluster)中數據庫主從庫VIP的配置,將業務從老機房MySQL集群切換到新機房MySQL集群,此時該業務所有的請求都會流入到新集群(圖9紅色虛線)。為了防止老集群仍然有業務寫入或讀取,我們將老集群主庫設置為只讀,然后繼續通過tcpdump抓包分析老集群上可能存在的請求并手動處理,最終保證所有業務都使用新的MySQL集群。
由于需要對主機、網絡、存儲和監控等幾個業務都進行集群切換,為保證不互相影響,使用逐個集群處理的方式,整體切換加檢測的時間耗時近1個小時。
在整個機房切換的過程中,只有數據庫集群是有狀態的業務,因此重要性和危險性也比較高,該服務切換完成后,最重要的一個環節也宣告完成,剩下的業務層面(UHost/UDB/EIP等)的遷移工作由各個業務團隊自行完成即可。
收尾
最終所有業務實例完成遷移后,理論上就可以完成本次機房遷移工作了,不過還是要對老機房仍然運行的實例進行流量監測,確認沒有流量后進行下線,停止服務。最后對老機房的ZooKeeper集群(老機房的3個ZooKeeper節點)進行請求監測和連接監測,確認沒有本機房以及新機房發來的請求(排除ZooKeeper集群自主同步的情況),在完成確認后,進行最后的ZooKeeper集群變更,將整個集群(8個節點)拆分成老機房(3個節點)和新機房(5個節點),老機房的集群直接停止服務,而新機房的新的ZooKeeper集群完成新的選主操作,確認同步正常和服務正常。
寫在最后
經歷了上文所述的一切操作后,整個首爾機房的遷移工作就完成了,整個項目歷經5個月,其中大部分時間用于業務實例的遷移過程,主要是針對不同的用戶要確定不同的遷移策略和遷移時間;內部管理服務的遷移和部署所花費的時間還是比較少的。UCloud內部針對本次遷移的每一個步驟都制定了詳細的方案規劃,包括服務依賴分析、操作步驟、驗證方式、切換風險、回滾方案等,為了完成如此巨大的新機房熱遷移工作,團隊投入了充足的人力和時間。首爾新機房具有更好的建設規劃、硬件配置和軟件架構,能夠為用戶提供更好的服務,我們相信這一切都是很有價值的。








 京公網安備 11010502049343號
京公網安備 11010502049343號