


信息化蓬勃發展,帶來數據的爆發式增長。在云計算和大數據時代,基于數據開展生產、運營、決策成為常態,數據的存儲及應用體系是企業生態運轉的中樞神經。
近日,全球最具權威的第三方IT研究與顧問咨詢公司Gartner聯袂廣州市品高軟件股份有限公司最新合作的報告:《基于數據湖架構的大數據平臺》(Big data platform based on Data Lake Architecture)正式發布,雙方就數據湖(Data Lake)的現實挑戰、技術實踐與發展趨勢展開了探討。了解更多,請添加品高云家的小表妹(VX:pingaoyunzzm)。

本次報告中,Gartner引用了其資深分析師Nick Heudecker發表的一篇名為《數據湖設計的最佳實踐》(Best Practices for Designing Your Data Lake)的文章。報告指出,一個成功的數據湖系架構需要數據的管理者合理地區分出數據的來源、挖掘、優化、監管和使用體系等,并逐一分析了如何更好地設計這些模塊,從而最大化地使用數據。
這與品高軟件最新發布的品高云數據湖管理平臺(BingoInsight)設計理念不謀而合。據悉,基于數據湖架構的大數據平臺BingoInsight是國內首個企業級的私有云數據湖,是新一代的數據匯聚、共享、交換、開放平臺。

品高云數據湖能夠實現全數據形態的共享存儲,提供數據資源發布、存儲、編目、使用及評價等全生命周期的數據開放支撐,并可通過聯邦數據湖解決跨組織邊界的數據主權和數據信任問題,為用戶快速交付數據價值。了解更多,請添加品高云家的小表妹(VX:pingaoyunzzm)。
查看更多Gartner與品高云關于數據湖的聯合報告,請前往:
https://www.gartner.com/technology/media-products/newsletters/Bingosoft/1-48SPAN2/index.html。
下附報告英文原文及翻譯:
基于數據湖架構的大數據平臺
A Big Data Platform Based on Data Lake Architecture
引言
Introduction
進入大數據時代,數據碰撞比傳統的數據分析激發更大價值,而數據碰撞的前提是先實現企業內各業務線條之間、跨企業組織之間以及跨行業的數據匯聚、共享和開放,這是大數據技術應用面臨的一項現實挑戰。品高數據湖通過深度融合云計算和大數據技術,提供分布式的面向多組織用戶的大數據應用平臺,幫助用戶構建可持續交付的數據生態鏈,用戶相互之間可以基于平臺進行數據交換和數據碰撞,從而深入挖掘數據價值,促進各用戶組織的數據應用創新,有效提升組織數據應用能力。
In the era of big data, data collision, compared with traditional data analysis, inspires greater value. The premises for data collision are the convergence, sharing and opening of data among different business lines in enterprises, various organizations and industries, which stand as challenges for the applications of big data technologies. Bingo Data Lake, by means of a deep integration of cloud computing and big data technology, provides distributed big data application platforms facing multiple organizational users and helps the users to build a sustainable data ecological chain. Data exchange and collision based on platforms among users can be achieved, which further excavates data values, promotes data application innovation, and improves the data application capability of the organizations.
挑戰
Challenges
當前大數據技術曲線已發展至進入實際應用階段的拐點,云計算技術的成熟和穩定保證了大數據技術的落地。大數據技術涵蓋了從軟硬件基礎架構到具體應用的多層次,技術生態更為豐富,應用層面更是能帶來全新的甚至是顛覆性的認知,因此大數據技術及應用具有巨大的價值探索空間,不確定性和更大的可能性并存,這是令人振奮的挑戰與機遇。
With the big data technology curve currently reaching an inflection point into the stage of practical application, the maturation and stability of cloud computing technologies guarantee to keep big data technologies on track. Big data technologies have a wide coverage from basic structures of software and hardware to layers of specific applications, which contributes to a richer technical ecology and might bring about brand-new or even disruptive cognition. Therefore, there is huge space for value exploration of the big data technologies and their applications, with uncertainty and greater possibility coexisting, bringing exciting both challenges and opportunities.
從技術方面,大數據技術生態繁榮,發展日新月異, Hadoop、Spark,MPP、NoSQL、kafka、機器學習、深度學習不斷發展,不同技術解決不同問題,企業的大數據平臺必定是混合式的架構,如何有效融合異構的技術成為企業構建大數據平臺必須面臨的問題。
In technical aspects, the big data technology ecology is booming. Technologies like Hadoop, Spark, MPP, NoSQL, Kafka, Machine Learning, and Deep Learning, each of which copes with distinct issues, are ever-developing. The big data platform of an enterprise has to be based on a hybrid architecture. How to achieve an effective heterogeneous technology convergence has become a prompt issue facing enterprises establishing their big data platforms.
從數據方面,跨部門、跨企業、跨行業的數據融合需求日趨明顯,數據關聯碰撞也是激發數據創新的基礎,如何有效打破數據孤島,解決數據主權,實現統一的數據匯聚和共享是企業面臨的另外一個關鍵性問題。
In terms of data, demands on data fusion across departments, enterprises and industries have been gradually evident, while the association and collision of data are the basis on which data innovation is ignited. Thus another critical issue facing enterprises has been how to effectively break the data silos, solve the issues of data sovereignty, and achieve a unified data convergence and sharing.
正因如此,亞馬遜、微軟等大廠商憑借靈敏的市場嗅覺,順應市場趨勢,在2016年紛紛推基于公有云的的數據湖解決方案,以解決技術融合和數據融合的問題。另一方面,很多企業和組織因為存在內部數據融合以及有保護的對外數據交換等現實要求,開始對比借鑒公有云數據湖解決方案來規劃組織內私有的數據湖平臺建設。
Consequently, to address the above technical and data integration problems, fast-moving enterprises like Amazon and Microsoft, following the market trends, introduced their data lake solutions based on public clouds in 2016. On the other hand, due to realistic requirements of internal data integration and external data exchange, many enterprises and organizations have begun comparing and learning from public cloud data lake solutions in their planning of the construction of private data lake platforms.
品高公司一直致力于耕耘企業級市場,在大數據概念興起階段逐步洞察到大數據技術在企業落地的挑戰,經過兩年研發在2017年初推出了基于私有云的數據湖整體解決方案,以幫助企業和組織構建私有的大數據平臺,使組織級的大數據應用及價值創新成為可能。
Bingo has been dedicated to the markets of enterprises, and perceived the challenges facing the big data technologies during their landing in enterprises. After two years’ development, Bingo introduced its data lake overall solutions based on private clouds in early 2017, aiming to help enterprises and organizations to build their private big data platforms and make possible the big data application and value innovation in the organizational level.
品高數據湖方案
Bingo Data Lake Solutions
品高數據湖依托BingoCloudOS(品高基礎云產品),基于對象存儲S3幫助企業構建數據湖,為廣泛的政企客戶組織內部門或分支機構之間、跨組織之間以及跨行業對接數據資源和進行數據應用創新提供了普適性的基礎數據支撐環境。具體而言,品高數據湖提供涵蓋數據存儲、數據集成、數據處理、數據管理、數據消費等一站的數據服務,是可服務于數據全生命周期的解決方案。
Relying on BingoCloudOS, Bingo Data Lake helps enterprises establish their data lakes on the basis of S3 Object-based Storage, providing universal data supporting environments for the exchange of data resources and the innovation of data applications among different departments, branches, organizations, and industries. Specifically, Bingo Data Lake offers one-stop services covering the storage, integration, processing, management, and consumption of data, and can serve the whole life cycle of the data.
品高數據湖解決方案包括5部分,分別為數據湖存儲、數據集成、數據處理、數據管理和數據消費。同時,Gartner數據湖最佳設計實踐報告指出,保障數據湖成功落地需要重點考慮數據集成、數據探索和開發、數據治理、數據消費等四個方面,可以說,品高數據湖解決方案與Gartner觀點不謀而合。
Bingo Data Lake solutions are comprised of 5 parts: data lake storage, data integration, data processing, data management, and data consumption. Meanwhile, to keep data lake efforts on track, four clauses need to be stressed, which are data acquisition, insight discovery and development, data governance and analytics consumption.
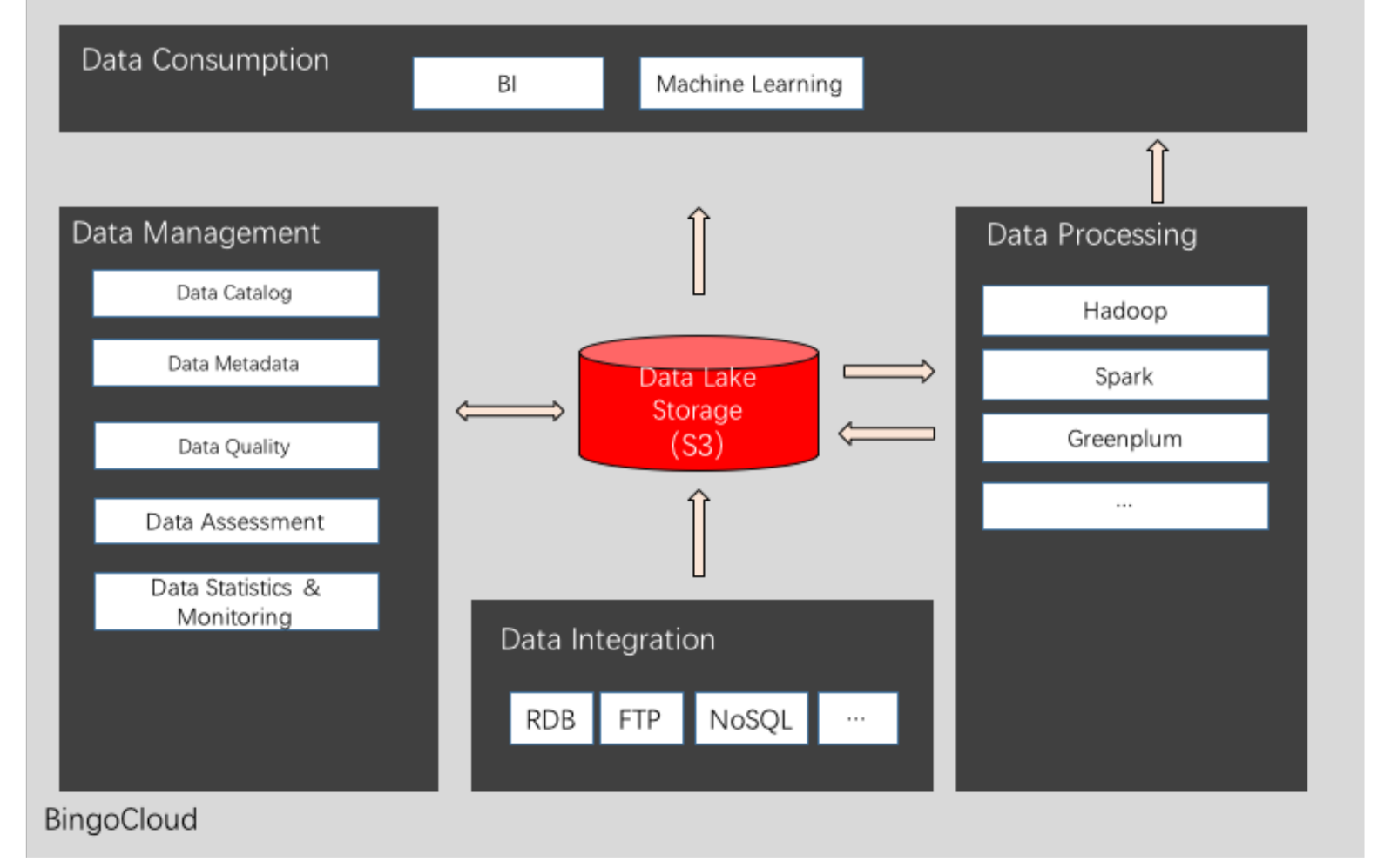
數據湖存儲
Data Lake Storage
數據湖存儲基于品高云對象存儲技術實現,能夠存儲全數據類型(結構化數據、文本、圖片、音視頻等)的存儲,數據湖存儲提供以下特性保障數據湖的存儲管理,
Data lake storage is based on BingoCloudOS object-based storage technology, and is able to realize the storage of all data types (structured data, texts, images, audio and video files, etc.). It has characteristics including:
• 高可用:可以實現99.999999999%的高可用性,支持大規模節點部署,單集群可以支持1024臺服務器,單云16000臺服務器,可以支撐海量數據存儲、匯聚、共享
• High availability: Availability as high as 99.999999999%; supporting large-scale node deployment with a single cluster supporting 1024 servers and a single cloud supporting 16000 servers, thus achieving massive data storage, convergence and sharing
• 良好的兼容性:兼容AWS S3協議,可與Hadoop、Spark、Greenplum等主流大數據計算技術無縫集成,快速支撐數據的開發、處理,高安全性
• Good compatibility: Compatible with AWS S3, being able to achieve seamless integration with mainstream big data computing technologies like Hadoop, Spark, and Greenplum, supporting data development and processing, and highly secure
• 安全性:可以實現多個租戶的數據隔離和共享,基于存儲桶隔離多個租戶的數據,并通過權限策略授權實現數據共享,支持服務端加密,實現敏感性數據的自動加密
• Security: Capable of data isolation and sharing among multiple tenants. Data of tenants are isolated with buckets, and further realize data sharing via access policy authorization. Server side encryption is supported with automatic encryption for sensitive data
• 高能性:支持大文件切片、多節點并發傳輸,提升數據傳輸效率
• High efficiency: Large file slicing and multi-node concurrent transmission supported, improving data transmission efficiency
Automatic duplication and synchronization across data centers supported without limitations from the data centers; global name space management across data centers supported; federated data lake buildable.
數據集成
Data Integration
數據集成是將數據提取、轉換和加載的過程,以自動化的形式從源系統中提取數據,轉換成一致的格式,并加載到數據湖中。品高數據湖提供數據湖集成工具,保障異構數據源能夠快速、鮮活的流入數據湖。
Data integration refers to the process of the extraction, conversion and loading of data, in which data are automatically extracted from source systems, converted into consistent formats, and loaded to the data lake. Bingo Data Lake provides data lake integration tools and can ensure that heterogeneous data sources could pour into the data lake fast and alive.
• 易用:無需編碼,通過可視化配置即可將數據發布至數據湖;
• Ease of use: No need for coding, data being able to be transmitted to the data lake with visual configurations
• 異構數據源支持:支持與各種關系型數據庫、Hadoop、NoSQL數據庫、MPP等主流大數據技術無逢對接,自動獲取數據至數據湖。
• Heterogeneous data sources supported: Seamless integration with mainstream big data computing technologies like Hadoop, NoSQL, and MPP supported, with data automatically acquired into the data lake
• 任務調度:采用分布式的集成任務調度,并支持分鐘、小時、日、周、月燈多種時間調度周期,提升數據湖的數據集成效率
• Task scheduling: Distributed task schedule adopted, supporting time scheduling cycles of minutes, hours, days, weeks, and months, thus improving the data integration efficiency of the data lake
• 多種控制策略:支持集成作業重試、作業依賴、人工重跑等多種作業控制策略,保障數據集成作業的SLA
• Multiple control policies: Job control policies such as job retry, job dependence, and manual re-run supported, ensuring SLA of data integration jobs
數據探索和開發
Data Discovery and Development
通過數據集成完成數據湖的數據集中后,品高提供內置的Hadoop套件,幫助用戶快速探索、分析和處理數據湖的數據。
When data of a data lake are collected after the data integration, Bingo offers a built-in Hadoop package that can help users rapidly explore, analyze and process the data in the data lake.
• 內置Hadoop套件運行在品高云LXC(Linux container)上,性能損耗接近物理機,實現Hadoop集群的云托管,一方面,使得大數據處理集群的運維能夠交給云平臺管理,另外一方面,使得大數據技術能夠與云計算技術進行深度的融合
• The built-in Hadoop package runs on BingoCloudOS LXC (Linux container) with a performance cost close to a physical machine. It can perform cloud hosting of Hadoop clusters. The operation and maintenance of big data processing clusters can be managed on the cloud platform, and, at the same time, big data technologies can have a deep integration with cloud computing technologies
• 支持多租戶使用統一Hadoop集群,多個部門、多個應用通過資源分配、資源隔離共享計算資源有效提升資源利用率
• Multiple tenants using unified Hadoop clusters supported. Departments and applications can share the computing resources through resource allocation and isolation, thus effectively raising the level of resources utilization
• 支持Hadoop外部表直連數據湖的數據,可實現與本地數據碰撞關聯計算,計算完后的數據可存儲回數據湖
• Direct connections between Hadoop external tables and the data in the data lake supported. It can calculate the collision and association with local data with the result data stored back into the data lake
• 多種計算方法支持,除品高內置Hadoop外,其它Hadoop、CDH、Greenplum均可連接和使用數據湖的數據
• Multiple computing methods supported. In addition to Bingo’s built-in Hadoop, other Hadoop, CDH and Greenplum can also access and use the data in the data lake.
數據管理
Data Management
數據湖的數據如果無有效的數據治理手段和優化措施,必將成為數據沼澤,為此,數據管理是數據湖建設非常重要的一環,品高通過元數據管理、數據目錄、數據監控統計、數據質量等手段,實現數據湖數據的可讀、可檢索、可管理和可用性。
Without effective governance and optimization, a data lake is bound to be turned into a data swamp. Data management, therefore, is a critical part of the construction of a data lake. By means of metadata management, data catalog, data statistics & monitoring, and data quality, Bingo guarantees the data in its data lake readable, retrievable, manageable and available.
• 支持通過元數據描述、注冊數據湖數據樣的元數據,包括數據資源名稱、數據資源業務描述、數據資源字段信息、關聯數據資源等信息,保障數據的可讀性,并且能夠自動從數據所屬的數據源捕獲相關元數據,減少元數據的維護工作
• Metadata of the data samples in the data lake can be described and registered through metadata, including the names, business descriptions, field information, and association of the data resources, thus ensuring data’s readability. Also, metadata can automatically be captured from relevant data resources, resulting in less maintenance work
• 數據湖的數據資源支持按主題、組織、專題等維度編目數據,保障數據的可檢索性
• Data resources of the data lake can be catalogued according to subjects, organizations and features, ensuring data’s findability
• 可通過數據及時性、數據完整性、數據一致性、數據準確性等多個維度監控和分析數據湖的數據質量,并能夠實現數據質量監控、分析、檢查、報告的閉環管理,此外,還支持數據消費者對數據資源的質量進行評價評論,持續提升數據湖的數據質量
• Data quality can be monitored and analyzed in terms of data’s timeliness, integrity, consistency, and accuracy, and it’s possible to perform a closed-loop management of the monitoring, analysis, inspection and report of the data quality. Moreover, data consumers can also evaluate and comment on the quality of the data resources, which will continuously improve the data quality of the data lake
• 能夠實現從數據集成、數據存儲、數據處理、數據消費的全過程性能指標的監控分析,實時監控分析各個環節的處理情況,幫助管理人員第一時間掌握數據湖的整體運行狀況,對于數據湖的運營、可持續發展具有指導意義
• Monitoring and analysis of the performance indexes can be achieved throughout the process of the integration, storage, processing and consumption of data. It will monitor and analyze in real time the handling of each link, which can help the managers to grasp the overall running conditions of the data lake in the first place and has guiding significance for the operation and sustainable development of a data lake
數據分析與消費
Data Analysis and Consumption
當大量數據被采集到數據湖中,經過開發處理,再將處理后的可用數據存入回數據湖,為各類大數據分析應用提供數據支撐。
Massive data can be collected into the data lake and then developed and processed. Processed available data can then be stored back into the data lake, providing data support for various big data analysis applications.
品高數據湖方案中提供大數據分析平臺,通過自助分析、數據可視化等多種方式讓用戶進行數據消費,自由發掘數據的潛能和價值。平臺中內置儀表盤、數據源管理、數據報表、數據報告以及與地理位置信息結合的數據運算和展示等多種分析組件,同時還可以支持第三方的數據分析工具、以及用戶自己開發的分析工具等。
Bingo Data Lake solutions provide platforms for big data analytics, and enable users to conduct data consumption and explore the potential and value of data by means of self-analysis and data visualization. Built-in analysis components in the platforms include dashboards, data source management, data reports, and data processing and demonstration combined with geographic positions. Meanwhile, third-party data analysis tools and tools developed by users are also supported.
• 提供內置的自助查詢工具,可直接通過圖形化界面建立數據分析,用戶可通過配置數據模型、過濾條件、結果字段等查詢條件,即可獲得相應的數據分析結果報表
• Built-in query tools can help to perform data analysis with graphic interfaces. Users can set query conditions such as data model, filter condition and result field, and acquire relevant result reports of the data analysis
• 提供多樣化的數據分析呈現圖表,如地圖工具、數據報表、 數據腦圖、數據報告等,依據數據可視化的科學方法以合理的方式為用戶呈現分析結果,極大提升分析結論的可讀性
• Diverse data analysis charts are provided, such as maps, data reports, data mind maps, etc. Analysis results are presented in the scientific and reasonable way of data visualization, contributing to much greater readability
• 支持數據分析過程的協作共享,從源數據到得出分析結果的過程中,可分別由不同的用戶分工協作,其中可能包含數據管理員、分析人員、一線業務人員等等,讓各類用戶均能夠參與到數據分析的過程中來,并以社交化的方式分享數據分析報告
• Collaboration and sharing is allowed during data analysis. In the process of getting a result from source data, users can coordinate and distribute responsibilities. Persons involved might include data managers, analysts, first-line business personnel, etc., which allows participation of various users in the process of data analysis and enables the sharing of data analysis reports in a socialized manner
應用場景
Application Scenarios
基于上文中介紹的品高數據方案的功能特性和創新點,以下列舉三個適合于應用數據湖方案的應用場景。
In accordance with the characteristics and innovations of Bingo data solutions, 3 scenarios suitable for data lake solutions are listed as follows.
場景1:跨組織邊界的數據共享
Scenario 1: Data Sharing Across Organizational Boundaries
隨著大數據的深入發展,各企業、政府紛紛建設了大數據平臺,對于提升企業生產效率、銷售模式以及政府治理水平等起到了有效的推動,數據應用不再局限于自身擁有的數據,要求通過多方數據共享后的匯聚分析實現更大力度的數據創新,進而促進企業或政府組織的治理質量提升。
As big data further develops, enterprises and governments have successively established their big data platforms, which contributes to the improvement of the enterprises’ production efficiency and sales patterns and the governments’ governance. The applications of data are no more confined to one’s own data, and the convergence analysis following data sharing among multiple parties can realize greater data innovation and improve the governance of enterprises or government organizations.
傳統解決方案存在的問題
Problems with the Traditional Solutions
難實現異構技術融合
Difficulties in Achieving Heterogeneous Technology Convergence
組織機構產生的數據復雜多樣,數據匯聚難度大。Hadoop 技術僅能夠解決單個部門的數據存儲和處理,但無法解決跨組織邊界的技術融合和共享權限問題。跨組織邊界的大數據技術路線不一,技術融合難度大。
Complicated and diverse data generated from organizations result in huge difficulty of data convergence. Hadoop technology is able to settle the data storage and processing of a single department, while unable to address issues over data integration and sharing rights across organizations. Big data technical routes across organizational boundaries are varied, which causes huge difficulty in technology integration.
數據共享模式存在不足
Defects of Data Sharing Modes
跨組織邊界的數據共享開放常見模式有數據查詢接口、FTP 文件交換、大數據交易所等。
Common modes of data sharing across organization boundaries include data query interface, FTP file exchange, big data exchange, etc.
• FTP 文件交換存在安全性弱、交換性能差、數據主權難界定、需拷貝數據等問題。
• FTP file exchange is weak in terms of security and exchange performance. Here, data sovereignty is hard to define, and data has to be replicated.
• 大數據交易所缺乏數據匯聚基礎,難以滿足大量數據的關聯碰撞。
• Big data exchange is in lack of a basis for data convergence, and is hard to fulfill the association and collision of massive data.
缺乏對運營體系的支持
Lack of Support for Operation Systems
大數據平臺往往重技術、輕運營、輕質量,導致大數據平臺無法可持續發展,有必要從數據評價、數據質量和數據開放指數建立全面的數據運營體系,保障數據共享的可持續發展。
Big data platforms often pay more attention to technologies than their operation and quality, which results in its difficulty in sustainable development. It is essential to create a comprehensive data operating system by referring to data’s assessment, quality and index of opening, and protect the sustainable development of data sharing.
應對與解決
Coping Solutions
針對以上問題和需求,品高數據湖方案通過深度融合云計算和大數據技術,以數據存儲為基礎,通過在本文所述的數據集成、數據開發、數據管理、數據消費四個方面的創新能力,解決組織部門之間、跨組織、跨行業的數據共享和開放,幫助組織構建可持續、健康的數據生態鏈,通過數據關聯進一步挖掘數據價值,推動數據創新。
Aiming at problems and demands listed above, on the basis of data storage, by integrating cloud computing and big data technology, and by taking advantages of its innovative capabilities on the integration, development, management and consumption of data, Bingo Data Lake solutions settle the data sharing and opening across departments, organizations and industries, help organizations to create a healthy and sustainable data ecological chain, and further excavate data values through data association so as to promote data innovation.
場景2:促進基于數據的產學研的合作
Scenario 2: Promoting Production-Study-Research Cooperation Based on Data
行業生產數據與科研之間的矛盾
Contradiction Between Production Data and Research
政府機構、大型企業擁有大量生產數據,但技術儲備和算法模型較弱,而高校、科研機構有技術、有算法模型,苦于沒數據。
Government agencies and large scale enterprises possess massive production data but weak technical reserves and algorithm models, while universities and research institutions turn out to be the opposite.
利用數據湖建立生產和科研的橋梁
Building a Bridge Between Production and Research with a Data Lake
基于上述問題,可通過數據湖將行業生產數據脫敏后存儲到數據湖,開放給科研機構、高校進行研究性探索,同時,研究成果可反饋應用于企業,從而有效促進基于數據的產學研合作。
On account of the problems above, production data can be desensitized through the data lake, stored in it, and opened to research institutions and universities for research purposes. Meanwhile, research results can in turn be applied by enterprises, which may effectively promote the Production-Study-Research Cooperation based on data.
場景3:聯邦數據湖
Scenario 3: Federated Data Lake
跨組織的數據集中存在安全和信任問題
Security and Trust Issues in Cross-organizational Data Collection
在數據湖的建設過程中,會常常遇到跨企業間、不同政府部門間的跨組織數據湖建設。如果通過統一的數據湖來集中管理所有數據,數據的采集將會變得比較困難,包括組織間的數據互信、數據主權、數據安全等一些列問題。
During the constructions of data lakes, we will frequently encounter cross-organizational constructions across enterprises or different government departments. If we manage all data with a unified data lake, data collection will become difficult, and issues like mutual trust, sovereignty and security of the data will occur.
利用聯邦數據湖構建開放的數據生態
Data Ecology Based on Federated Data Lakes
應對上述情況,品高數據湖方案提供去中心化的聯邦數據湖,平臺基于聯邦數據湖實現跨部門、跨組織的數據共享,并通過數據開放平臺,將數據相關的目錄、工具、服務、模型開放出來,各組織和數據模型相關軟件開發商均可在上面進行數據協作,幫助企業、政府構建可持續發展的數據生態鏈。
To address the situation, Bingo Data Lake solutions offer federated data lakes that are decentralized. The platform based on federated data lakes can realize data sharing across departments and organizations. Relevant catalogs, tools, services and models can be opened for all organizations and relevant software developers to collaborate, thus helping enterprises and governments to establish a healthy and sustainable data ecological chain.








 京公網安備 11010502049343號
京公網安備 11010502049343號