


這一次可以說是真的活久見了,強如阿里也會全線崩潰。
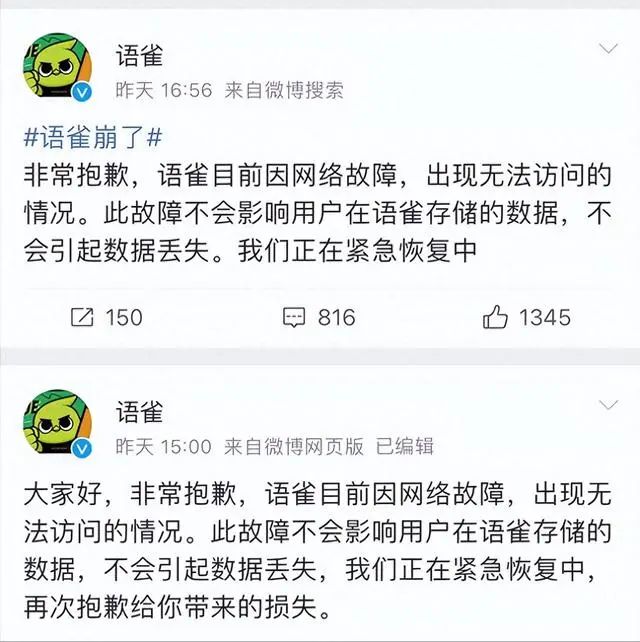
早在10月23號這天,阿里旗下的語雀便遭遇了一場前所未有的P0級事故。
客戶端,網站,移動端都無法正常訪問和使用,持續了近8個小時。
由于當天又是周一,所以受影響的用戶非常多,致使很多打工人在微博上怨聲載道。
正當大家以為這起事故已經稱得上是“年度大事件”的時候,11月12日——這個電商公布雙十一戰績的關鍵節點,阿里再度被打臉。
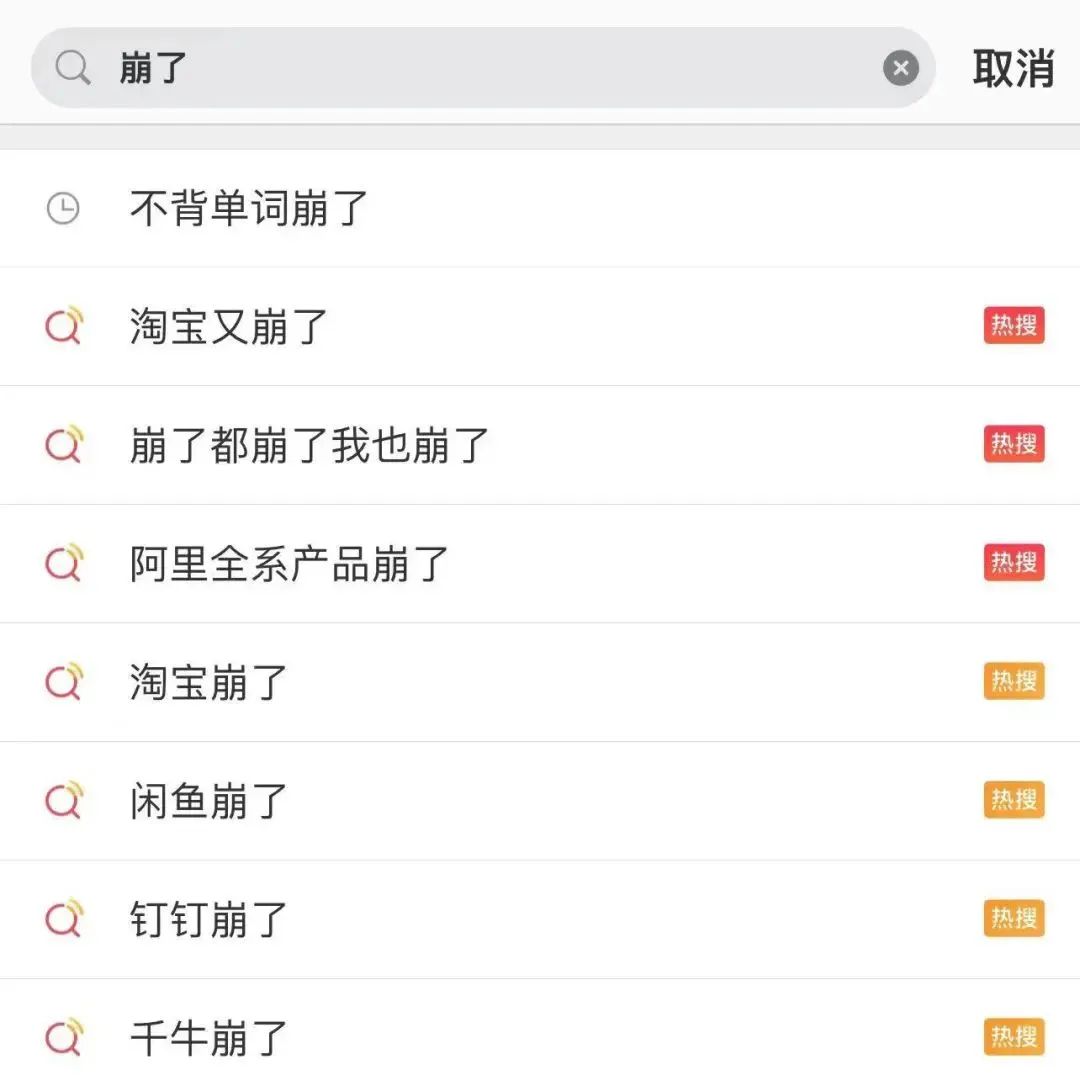
當天下午五點多起,阿里旗下產品的大量用戶開始反饋無法使用等問題。
很快,淘寶崩了、閑魚崩了、釘釘崩了......一系列鋪天蓋地的信息沖上了熱搜。
由于問題出在了阿里云上,所有阿里系的應用基本上都部署在自家的阿里云上。
而阿里云這個類似于高速公路一樣的基礎設施塌了后,公路上的車輛自然都無法通行。
據網友實測,本次故障范圍覆蓋了一系列阿里系應用,包括餓了么、高德地圖,甚至支付寶的多活機房都滿載了。
其中釘釘等應用直接無法打開,淘寶、天貓、閑魚等則是交易系統故障。
不僅阿里自家產品受影響,據天眼查數據,阿里云的企業用戶超過300萬家。
這些客戶因為云服務不可用,業務運營也可能全面癱瘓。
很多用了阿里云或者阿里云服務的產品也沒能逃過一劫,比如CSDN和博客園。
這一次的故障,也讓不少網友感慨稱,原來阿里系的產品已經與我們的生活息息相關。
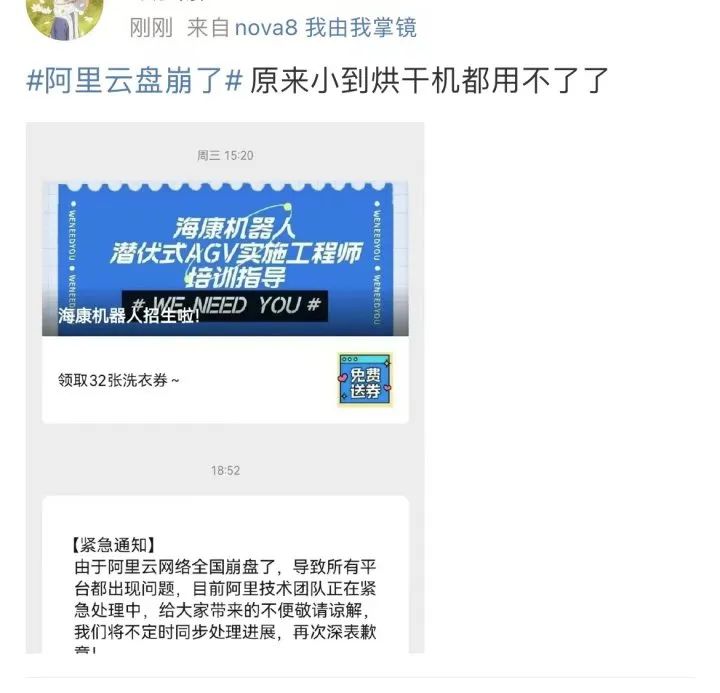
據反饋,在故障的影響下,甚至有一些停車場都無法順利抬桿,還有一些超市無法結賬。
大到公司業務停擺,小到烘干機和智能音箱都用不了。
因為前一天正是雙十一,有不少人推測,服務器故障或是受到其影響。
也有網友調侃稱,這是“雙十一期間開屏跳轉廣告”和“降本增效”帶來的后遺癥。

受影響地域也涵蓋甚廣,包括阿里云位于中國內地、港澳臺、亞洲其他、歐洲、北美、中東、政務云以及金融云等數據中心均受影響。
從阿里云官網得知,這次受到影響的產品包括:企業級分布式應用服務、消息隊列 MQ、微服務引擎、鏈路追蹤、應用高可用服務、應用實時監控服務、Prometheus監控服務、消息服務、消息隊列Kafka版、機器學習、圖像搜索、智能推薦 AIRec、智能開放搜索 OpenSearch、云行情、數據總線 DataHub、檢索分析服務 Elasticsearch版、圖計算服務 Graph Compute、實時計算 Flink版、智能數據建設與治理 Dataphin、開源大數據平臺 E-MapReduce、云原生大數據計算服務 MaxCompute、實時數倉 Hologres、大數據開發治理平臺 DataWorks、智能媒體服務、媒體處理、視頻點播、對象存儲、文件存儲NAS、表格存儲、日志服務、云存儲網關、文件存儲 HDFS 版、塊存儲、混合云備份服務、密鑰管理服務、云防火墻、數據庫審計、加密服務、運維安全中心(堡壘機)、容器鏡像服務、容器服務Kubernetes版、API 網關、資源編排、云原生數據倉庫 AnalyticDB PostgreSQL版、圖數據庫、云原生內存數據庫Tair、云數據庫 Redis 版、云原生關系型數據庫 PolarDB、云數據庫專屬集群、云數據庫 MySQL 版、云原生數據倉庫AnalyticDB MySQL版、云原生分布式數據庫 PolarDB-X、云數據庫 ClickHouse、云原生多模數據庫Lindorm、云數據庫 PostgreSQL 版、云數據庫 SQL Server 版、云數據庫 MongoDB 版、云數據庫HBase版、數據傳輸、數據庫自治服務、數據庫備份、物聯網平臺、NAT網關、負載均衡、云解析 PrivateZone、彈性公網IP、共享帶寬、轉發路由器、私網連接、高速通道、IPv6 網關、專有網絡VPC、云企業網、VPN網關、FPGA 云服務器、超級計算集群、批量計算、無影云桌面、彈性伸縮、彈性容器實例、彈性裸金屬服務器、云服務器 ECS、輕量應用服務器、函數計算、Serverless 應用引擎、云托付、專有宿主機、GPU云服務器、彈性高性能計算、操作審計、服務器遷移中心、運維編排、智能計算靈駿、云呼叫中心、交通云控平臺、客服工作臺、視覺智能開放平臺、智能外呼機器人、智能語音交互、智能對話機器人、智能用戶增長、運維事件中心、新零售智能助理、智能雙錄質檢、地址標準化、機器翻譯、自然語言處理、短信服務、云解析DNS、域名、號碼認證服務、郵件推送、版權與專利服務、語音服務、智能聯絡中心、工商財稅、Salesforce on Alibaba Cloud、智能營銷引擎、云采銷、能耗寶、阿里郵箱、商標服務、移動研發平臺、機器人流程自動化、號碼隱私保護、DataV數據可視化、音視頻通信、視頻直播、閃電立方、網盤與相冊服務、安全、內容安全、安全管家、應用身份服務 (IDaaS)、實人認證、數字證書管理服務(原SSL證書)、風險識別、Web應用防火墻、云安全中心(態勢感知)、數據管理、云價簽、云投屏、物聯網智能視頻服務、物聯網無線連接服務、CDN、云數據傳輸、數據語音、智能接入網關、全站加速、ChatAPP 消息、全球加速、安全加速 SCDN、邊緣節點服務 ENS、訪問控制、資源管理、云監控、配置審計。
受到影響的地區包括:華北2(北京)、華北6(烏蘭察布)、華北1(青島)、華東2(上海)、華南2(河源)、華北3(張家口)、中國香港、印度(孟買)、美國(硅谷)、華南1(深圳)、英國(倫敦)、韓國(首爾)、日本(東京)、阿聯酋(迪拜)、西南1(成都)、華南3(廣州)、新加坡、澳大利亞(悉尼)、馬來西亞(吉隆坡)、華北5(呼和浩特)、印度尼西亞(雅加達)、美國(弗吉尼亞)、菲律賓(馬尼拉)、泰國(曼谷)、華東1(杭州)、華南1 金融云、華東5(南京-本地地域)、華東6(福州-本地地域)、華北2 金融云(邀測)、華東2 金融云、華東1 金融云、華北2 阿里政務云1、非區域性、德國(法蘭克福)、沙特(利雅得-合作伙伴運營)。
總之,本次阿里云出事波及之大,已屬于全球性大故障,在阿里系歷史上實屬罕見。
當天18 點 14 分,阿里云官方終于回應了:
尊敬的客戶:您好!
北京時間 2023 年 11 月 12 日 17:44 起,阿里云監控發現云產品控制臺訪問及 API 調用出現異常,阿里云工程師正在緊急介入排查。非常抱歉給您的使用帶來不便,若有任何問題,請隨時聯系我們。
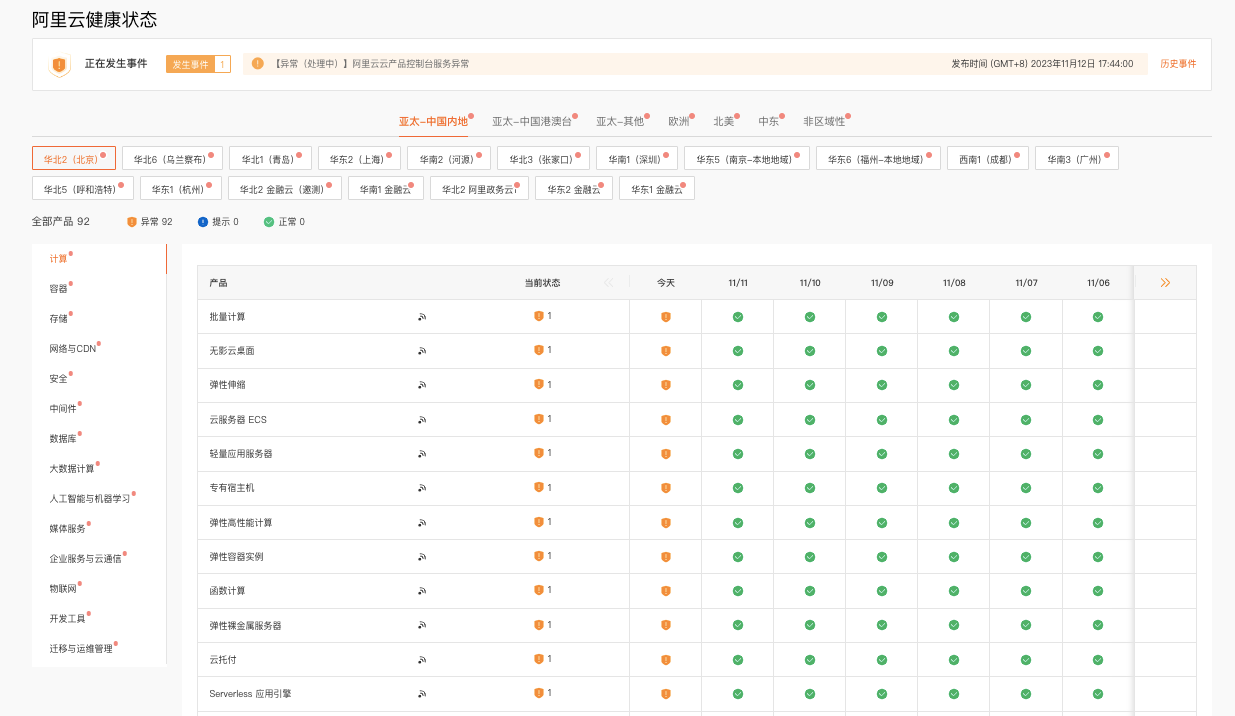
根據阿里云團隊公布的整個修復過程,從17:44發現問題,一直到21:11,歷時將近3個半小時才基本恢復。
阿里云此次核彈級別的重大事故,也再次暴露了云計算服務的脆弱性。
云計算服務的確是一種高可靠、高可用、彈性伸縮的服務,但也存在故障的風險。
這次還只是部分地域控制臺服務受影響,那下一次呢?
在日益復雜的互聯網環境下,阿里的技術保障能否真正應對挑戰?
阿里作為互聯網巨頭,其崩潰影響之大,背后暴露出的問題同樣驚人。
還希望包括阿里在內的各大互聯網公司能吸取各種教訓,加強技術和服務的改進,以免再度發生類似的事情帶來巨大損失。
當然,最苦逼的還是阿里打工的程序員,估計今年年終獎金也難了......








 京公網安備 11010502049343號
京公網安備 11010502049343號