


芯片是當前科技、產(chǎn)業(yè)和社會關(guān)注的熱點,也是 AI 技術(shù)發(fā)展過程中不可逾越的關(guān)鍵階段。無論哪種 AI 算法,最終的應(yīng)用必然通過芯片來實現(xiàn)。
在剛剛結(jié)束的計算機體系結(jié)構(gòu)頂會ISCA 2018上,2017年的圖靈獎得主、體系結(jié)構(gòu)領(lǐng)域的兩位宗師級人物John L. Hennessy和David A. Patterson在演講中指出,隨著摩爾定律和登納德縮放比例定律(Dennard Scaling)的放緩甚至停滯,單處理器核心的性能每年的提升已降為3%左右——相比上世紀60年代的黃金時期,那時候由于體系結(jié)構(gòu)的創(chuàng)新,計算機性能每年提升在60%左右。
通用處理器性能提升的形勢看上去已經(jīng)十分嚴峻,但接下來我們要帶來一些好消息。從IBM、英特爾到微軟,從學術(shù)界到產(chǎn)業(yè)界,芯片研究者的探索從未停止,進展也切切實實在發(fā)生。
IBM Nature論文:全新AI芯片,能效超GPU的100倍
在最近發(fā)表在Nature上的一篇論文中,IBM Research AI團隊用大規(guī)模的模擬存儲器陣列訓練深度神經(jīng)網(wǎng)絡(luò)(DNN),達到了與GPU相當?shù)木取Q芯咳藛T相信,這是在下一次AI突破所需要的硬件加速器發(fā)展道路上邁出的重要一步。
未來人工智能將需要大規(guī)模可擴展的計算單元,無論是在云端還是在邊緣,DNN都會變得更大、更快,這意味著能效必須顯著提高。雖然更好的GPU或其他數(shù)字加速器能在某種程度上起到幫助,但這些系統(tǒng)都不可避免地在數(shù)據(jù)的傳輸,也就是將數(shù)據(jù)從內(nèi)存?zhèn)鞯接嬎闾幚韱卧缓蠡貍魃匣ㄙM大量的時間和能量。
模擬技術(shù)涉及連續(xù)可變的信號,而不是二進制的0和1,對精度具有內(nèi)在的限制,這也是為什么現(xiàn)代計算機一般是數(shù)字型的。但是,AI研究人員已經(jīng)開始意識到,即使大幅降低運算的精度,DNN模型也能運行良好。因此,對于DNN來說,模擬計算有可能是可行的。
但是,此前還沒有人給出確鑿的證據(jù),證明使用模擬的方法可以得到與在傳統(tǒng)的數(shù)字硬件上運行的軟件相同的結(jié)果。也就是說,人們還不清楚DNN是不是真的能夠通過模擬技術(shù)進行高精度訓練。如果精度很低,訓練速度再快、再節(jié)能,也沒有意義。
在IBM最新發(fā)表的那篇Nature論文中,研究人員通過實驗,展示了模擬非易失性存儲器(NVM)能夠有效地加速反向傳播(BP)算法,后者是許多最新AI進展的核心。這些NVM存儲器能讓BP算法中的“乘-加”運算在模擬域中并行。
研究人員將一個小電流通過一個電阻器傳遞到一根導線中,然后將許多這樣的導線連接在一起,使電流聚集起來,就實現(xiàn)了大量計算的并行。而且,所有這些都在模擬存儲芯片內(nèi)完成,不需要數(shù)字芯片里數(shù)據(jù)在存儲單元和和處理單元之間傳輸?shù)倪^程。

IBM的大規(guī)模模擬存儲器陣列,訓練深度神經(jīng)網(wǎng)絡(luò)達到了GPU的精度。來源:IBM Research
由于當前NVM存儲器的固有缺陷,以前的相關(guān)實驗都沒有在DNN圖像分類任務(wù)上得到很好的精度。但這一次,IBM的研究人員使用創(chuàng)新的技術(shù),改善了很多不完善的地方,將性能大幅提升,在各種不同的網(wǎng)絡(luò)上,都實現(xiàn)了與軟件級的DNN精度。
單獨看這個大規(guī)模模擬存儲器陣列里的一個單元,由相變存儲器(PCM)和CMOS電容組成,PCM放長期記憶(權(quán)重),短期的更新放在CMOS電容器里,之后再通過特殊的技術(shù),消除器件與器件之間的不同。研究人員表示,這種方法是受了神經(jīng)科學的啟發(fā),使用了兩種類型的“突觸”:短期計算和長期記憶。
這些基于NVM的芯片在訓練全連接層方面展現(xiàn)出了極強的潛力,在計算能效 (28,065 GOP/sec/W) 和通量(3.6 TOP/sec/mm^2)上,超過了當前GPU的兩個數(shù)量級。
這項研究表明了,基于模擬存儲器的方法,能夠?qū)崿F(xiàn)與軟件等效的訓練精度,并且在加速和能效上有數(shù)量級的提高,為未來設(shè)計全新的AI芯片奠定了基礎(chǔ)。研究人員表示,他們接下來將繼續(xù)優(yōu)化,處理全連接層和其他類型的計算。
英特爾首款獨立GPU最早2020年問世,曝光14nm獨立GPU原型
另一芯片大廠英特爾自然也不會回避這場游戲。
昨天,英特爾發(fā)推正式確認,其首款獨立GPU最早將于2020年問世,并附上了一張英特爾首席架構(gòu)師Raja Koduri的照片。
Raja Koduri在去年11月加入英特爾,此前曾在AMD擔任高級副總裁、RTG負責人。Raja Koduri有超過25年的視覺和加速計算技術(shù),將推進英特爾的“計算和圖形領(lǐng)先”戰(zhàn)略。

Raja Koduri
不過,英特爾的推特并沒有說明這些GPU的發(fā)展方向,也沒有透露哪一款產(chǎn)品將率先上市,但預計數(shù)據(jù)中心和游戲PC都是目標。
英特爾此前在2018年ISSCC會議(國際固態(tài)電路會議)上展示了首個14nm 獨立GPU原型,它是一個雙芯片解決方案。第一個芯片包含兩個關(guān)鍵部件:GPU本身和一個系統(tǒng)代理;第二個芯片是一個與系統(tǒng)總線連接的FPGA。目前,GPU組件基于英特爾的Gen 9架構(gòu),并具有三個執(zhí)行單元(EU)集群。這三個集群連接到一個復雜電源/時鐘(power/clock)管理機制,該機制有效地管理每個EU的電源和時鐘速度。
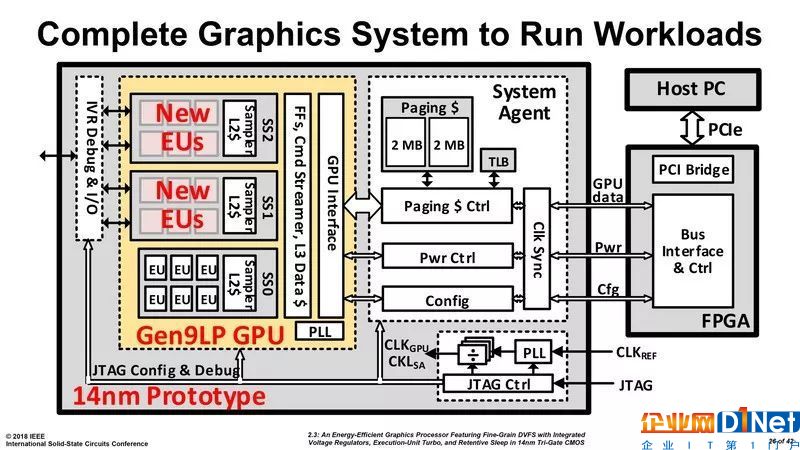

還有一個雙時鐘機制,可以使時鐘速度(即升壓狀態(tài))增加一倍,超過現(xiàn)在的Gen 9 EU可以在英特爾iGPU上處理的時鐘速度。一旦達到合適的能效水平,英特爾將使用新一代的EU,并利用新工藝流程擴大EU數(shù)量,開發(fā)更大型的獨立GPU。
Raja Koduri長期以來一直是圖形行業(yè)受人尊敬的領(lǐng)導者,他的加盟表明英特爾有意再次認真對待圖形產(chǎn)品。盡管很少有人質(zhì)疑英特爾芯片設(shè)計的能力,但從頭開始構(gòu)建新的GPU架構(gòu)不是一件小事,英特爾在三年內(nèi)會推出圖形產(chǎn)品的難度非常大。
Shrout Research的分析師Ryan Shrout表示,英特爾把目標定在2020年,目的是與AMD的Radeon和Nvidia的GeForce產(chǎn)品競爭。但英特爾需要與AMD和英偉達保持同樣的性能和效率,或者至少在20%的差距內(nèi)。
微軟:云計算招聘AI芯片工程師
微軟在芯片領(lǐng)域最近也有動作。
3月下旬,微軟在其Azure公共云部門發(fā)布了至少三個職位空缺,尋找適合AI芯片功能的應(yīng)聘者。后來,該部門又掛出一個硅谷項目經(jīng)理的職位空缺,以及“一個軟件/硬件協(xié)同設(shè)計和人工智能加速優(yōu)化工程師”職位。
在與亞馬遜AWS和谷歌云競爭之際,微軟愿意不惜一切代價打造一個功能齊全的云服務(wù)。專門的處理器是微軟證明其在云計算領(lǐng)域為企業(yè)提供人工智能服務(wù)的一種方式。
半導體領(lǐng)域?qū)ξ④泚碚f并不是全新的領(lǐng)域。微軟已經(jīng)通過FPGA芯片增強云計算的AI計算能力,并推出Project Brainwave項目。現(xiàn)在,這些芯片可用于使用Azure的即用型機器學習軟件進行AI模型的訓練和運行。
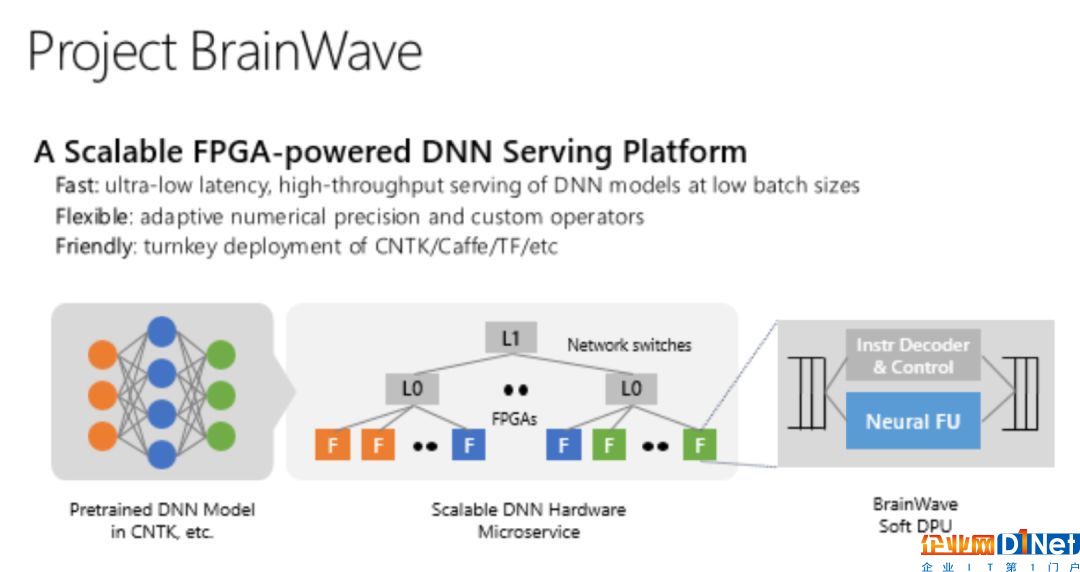
去年微軟表示,它正在為HoloLens的下一個版本構(gòu)建定制AI芯片,但這不在其云計算部門之內(nèi)。
微軟的一位發(fā)言人告訴CNBC,新的職位空缺不屬于FPGA計劃的一部分,但與公司在設(shè)計自己的云硬件方面所做的工作有關(guān),該計劃名為Project Olympus。
谷歌由于在云計算市場上落后于AWS和微軟,首次提出了在云計算中為人工智能開發(fā)定制芯片的想法,并且推出的TPU已經(jīng)進行了第三次迭代,成為了GPU的一種替代方案。然而,這是一個代價非常高昂的努力。
Moor Insights & Strategy的分析師Patrick Moorhead估計,谷歌在其TPU項目上已經(jīng)花費了2億至3億美元。跟英特爾、谷歌一樣,微軟做AI芯片的過程也將非常艱辛。
不過,現(xiàn)在微軟已經(jīng)表明了它的支出意愿,上個季度的資本支出達到了創(chuàng)紀錄的35億美元。
宋繼強、魏少軍:AI芯片尚在發(fā)展初期,擁有巨大創(chuàng)新空間
通過芯片技術(shù)來大幅增強人工智能研發(fā)的條件已經(jīng)成熟,未來十年將是AI芯片發(fā)展的重要時期,不論是架構(gòu)上還是設(shè)計理念上都將有巨大的突破。
賽靈思在今年3月宣布將推出新一代AI芯片架構(gòu) ACAP(Adaptive Compute Acceleration Platform),這是一款高度集成的多核異構(gòu)計算平臺,能根據(jù)各種應(yīng)用于工作負載的需求對硬件層進行靈活變化;英偉達在終端側(cè)和服務(wù)中心分別提供不同性能和能效比的GPU芯片。
英特爾中國研究院院長宋繼強博士,清華大學教授、微納電子學系主任魏少軍博士在今年的《人工智能》雜志第二期《AI 芯片:從歷史看未來》中寫道,架構(gòu)創(chuàng)新是AI芯片面臨的一個不可回避的課題。

我們要回答一個重要問題:是否會出現(xiàn)像通用 CPU 那樣獨立存在的 AI 處理器?如果存在的話,它的架構(gòu)是怎樣的? 如果不存在,那么目前以滿足特定應(yīng)用為主要目標的 AI 芯片就一定只能以 IP 核的方式存在,最終被各種各樣的 SoC 所集成。這樣是一種快速滿足具體應(yīng)用要求的方式。
從芯片發(fā)展的大趨勢來看,現(xiàn)在還是 AI 芯片的初級階段,無論是科研還是產(chǎn)業(yè)應(yīng) 用都有巨大的創(chuàng)新空間。從確定算法、領(lǐng)域的 AI 加速芯片向具備更高靈活性、適應(yīng)性的智能芯片發(fā)展是科研發(fā)展的必然方向。神經(jīng)擬態(tài)芯片技術(shù)和可重構(gòu)計算芯片技術(shù)允許硬件架構(gòu)和功能隨軟件變化而變化,實現(xiàn)以高能效比支持多種智能任務(wù),在實現(xiàn) AI 功能時具有獨到的優(yōu)勢,具備廣闊的前景。
下文選自《AI芯片:從歷史看未來》文章第四節(jié)和第五節(jié)。
四、AI 芯片的發(fā)展趨勢
AI 應(yīng)用落地還有很長的路要走,而對于芯片從業(yè)者來講,當務(wù)之急是研究芯片架 構(gòu)問題。從感知、傳輸?shù)教幚恚俚絺鬏敗?zhí)行,這是 AI 芯片的一個基本邏輯。但是智慧處理的基本架構(gòu)是什么?還沒有人能夠說得清,研究者只能利用軟件系統(tǒng)、處理器等去模仿。軟件是實現(xiàn)智能的核心,芯片是支撐智能的基礎(chǔ)。我們認為,短期內(nèi)以異構(gòu)計算(多種組合方式)為主來加速各類應(yīng)用算法的落地(看重能效比、性價比、可靠性);中期要發(fā)展自重構(gòu)、自學習、自適應(yīng)的芯片來支持算法的演進和類人的自然智能;長期則朝著通用 AI 芯片的方面發(fā)展。
通用 AI 計算
AI 的通用性實際上有兩個層級:第一個層級是可以處理任意問題;第二個層級是同時處理任意問題。第一層的目標是讓一種 AI 的算法可以通過不同的設(shè)計、數(shù)據(jù)和訓 練方法來處理不同的問題。例如現(xiàn)在流行的深度增強學習方法,大家用它訓練下棋、打撲克、視覺識別、語音識別、行為識別、運動導航等等。但是,不同的任務(wù)使用不同的數(shù)據(jù)集來獨立訓練,模型一旦訓練完成,只適用于這種任務(wù),而不能用于處理其它任務(wù)。 所以,我們可以說這種 AI 的算法和訓練方法是通用的,而它訓練出來用于執(zhí)行某個任 務(wù)的模型(是對具體解決這個任務(wù)的算法的表示,可以理解為程序中的一個模塊)是不通用的。第二層的目標是讓訓練出來的模型可以同時處理多種任務(wù),就像人一樣可以既會下棋,又會翻譯,還會駕駛汽車和做飯。這個目標更加困難,首先是還沒有發(fā)現(xiàn)哪一個算法可以如此全能,其次是如何保證新加入的能力不會影響原有能力的穩(wěn)定性,反而 可以彌補原來能力的不足,從而更好的完成任務(wù)。例如,我們知道多模態(tài)數(shù)據(jù)融合可以比只使用單模態(tài)數(shù)據(jù)有更好的準確性和魯棒性。
通用 AI 芯片
“通用 AI 芯片”就是能夠支持和加速通用 AI 計算的芯片。關(guān)于通用 AI(有時也 成為強 AI)的研究希望通過一個通用的數(shù)學模型,能夠最大限度概括智能的本質(zhì)。那么,什么是智能的本質(zhì)?目前比較主流的看法,是系統(tǒng)能夠具有通用效用最大化能力:即系統(tǒng)擁有通用歸納能力,能夠逼近任意可逼近的模式,并能利用所識別到的模式取得一個效用函數(shù)的最大化效益。這是很學術(shù)化的語言,如果通俗地說,就是讓系統(tǒng)通過學習和訓練,能夠準確高效地處理任意智能主體(例如人)能夠處理的任務(wù)。通用 AI 的難點 主要有兩個,一個是通用性(算法和架構(gòu)),第二個是實現(xiàn)復雜度。
通用 AI 芯片的復雜度來自于任務(wù)的多樣性和對自學習、自適應(yīng)能力的支持。所以, 我們認為通用 AI 芯片的發(fā)展方向不會是一蹴而就地采用某一種芯片來解決問題,因為理論模型和算法尚未完善。最有效的方式是先用一個多種芯片設(shè)計思路組合的靈活的異構(gòu)系統(tǒng)(heterogeneous system of AI chips)來支持,各取所長,取長補短。當架構(gòu)成熟,就可以考慮設(shè)計SoC(System on Chip)來在一個芯片上支持通用 AI。
五、面臨的挑戰(zhàn)
AI 芯片是當前科技、產(chǎn)業(yè)和社會關(guān)注的熱點,也是 AI 技術(shù)發(fā)展過程中不可逾越 的關(guān)鍵階段。無論哪種 AI 算法,最終的應(yīng)用必然通過芯片來實現(xiàn),不論是 CPU 還是文 中提及的各種 AI 芯片。由于目前的 AI 算法都有各自的長處和短處,只有給它們設(shè)定一個合適的應(yīng)用邊界才能最好地發(fā)揮它們的作用。因此,確定應(yīng)用領(lǐng)域就成為發(fā)展 AI 芯 片的重要前提。遺憾的是,AI 的“殺手”級應(yīng)用目前尚未出現(xiàn),已經(jīng)存在的一些應(yīng)用 對于老百姓的日常生活來說也還不是剛需,也還不存在適應(yīng)各種應(yīng)用的“通用”算法。其實,也不需要全部通用,能像人一樣可以同時擁有數(shù)十種能力,并且可以持續(xù)學習改進,就已經(jīng)很好了。因此,AI 芯片的外部發(fā)展還有待優(yōu)化。
架構(gòu)創(chuàng)新是 AI 芯片面臨的一個不可回避的課題。我們要回答一個重要問題:是否 會出現(xiàn)像通用 CPU 那樣獨立存在的 AI 處理器?如果存在的話,它的架構(gòu)是怎樣的? 如果不存在,那么目前以滿足特定應(yīng)用為主要目標的 AI 芯片就一定只能以 IP 核的方式存在,最終被各種各樣的 SoC 所集成。這樣是一種快速滿足具體應(yīng)用要求的方式。
從芯片發(fā)展的大趨勢來看,現(xiàn)在還是 AI 芯片的初級階段,無論是科研還是產(chǎn)業(yè)應(yīng)用都有巨大的創(chuàng)新空間。從確定算法、領(lǐng)域的 AI 加速芯片向具備更高靈活性、適應(yīng)性的智能芯片發(fā)展是科研發(fā)展的必然方向。神經(jīng)擬態(tài)芯片技術(shù)和可重構(gòu)計算芯片技術(shù)允許 硬件架構(gòu)和功能隨軟件變化而變化,實現(xiàn)以高能效比支持多種智能任務(wù),在實現(xiàn) AI 功能時具有獨到的優(yōu)勢,具備廣闊的前景。




Nature,英特爾、微軟出大招")

 京公網(wǎng)安備 11010502049343號
京公網(wǎng)安備 11010502049343號