


公有云的存儲服務具有易擴展的特性,用戶可以非常方便的根據其存儲容量需求,對其已有的存儲服務的容量進行擴展,因此從用戶角度來說,公有云的存儲服務具有無限容量的特點。
Unlimited Capacity:公有云的存儲服務具有易擴展的特性,用戶可以非常方便的根據其存儲容量需求,對其已有的存儲服務的容量進行擴展,因此從用戶角度來說,公有云的存儲服務具有無限容量的特點。
Low Cost:公有云的存儲服務采用的是即用即付的模式,而且支持按照實際使用容量進行計費;同時也沒有對存儲基礎設施的要求,所以具有低成本的優勢。
Performance not Well:通過公網對存儲服務進行訪問的網絡開銷,云服務商所采用的通用共享的硬件資源,以及通過虛擬化技術提供的服務,使得對于公有云存儲服務來說,其訪問性能并不是很高。

Security and Controllability not Well:如前面說的,在公有云中,所有的硬件、軟件和其他支持性基礎架構都是云服務商所擁有和管理的,并且所有組織和租戶都是共享相同的硬件、存儲設備和網絡設備,因此,從數據的安全性和可控制性角度來說,公有云的存儲服務并不是一個理想的選擇。
私有云存儲
High Performance:私有網絡甚至是專線網絡所帶來的較小的網絡開銷,以及軟、硬件資源選擇上極大的靈活性,使得對于私有云存儲服務來說,可以提供一個優于公有云的訪問性能。
High Security and Controllability:對于私有云存儲服務來說,因為其軟、硬件資源不與其他組織和租戶共享,而且可以完全將服務架設在私有網絡中,所以可實現更高的控制性和安全性級別。
Limited Capacity:對于私有云存儲服務來說,因為其所有資源都是自擁有的,也都需要自維護,包括對存儲集群進行擴容,所以從容量角度來說,為存儲集群進行擴容,顯性和隱性成本都很高,因此,從用戶角度出發,私有云存儲服務并不是無限容量的。
High Cost:如前面說的,在私有云存儲服務中,所有的軟、硬件資源成本,存儲集群的運維成本,包括數據中心的搭建、運營,私有網絡甚至是專線網絡的搭建,集群的維護等等,這些都是需要被納入到私有云存儲服務的成本中的。除此之外,不像公有云存儲可以按需分配容量,需要多少用多少,在私有云存儲中,為了滿足以后的一個可預期的最大容量需求,以及避免頻繁擴容所帶來的高昂的運維成本,在集群搭建時,往往都會以一個規劃容量進行搭建,這實際上就導致了整個存儲集群的使用容量會長期處于一個不飽和狀態,即部分存儲資源會長期出于一個空閑狀態。以上兩方面,就導致了私有云存儲相較于公有云存儲成本較高的問題。
混合云存儲
混合云存儲,即是將私有云存儲與公有云存儲打通,使得兩者相結合,共同對外提供存儲服務,可以說是私有云存儲和公有云存儲所有優點的集大成者。
High Performance :活動數據存儲在私有云存儲中,歸檔數據存儲到公有云存儲中。首先從性能角度來說,通過將活動數據、會被頻繁訪問到的數據存儲在私有云存儲中,可以保證混合云存儲可以提供一個較高的訪問性能;
High Security and Controllability:因為混合云存儲中的私有云部分的軟、硬件資源都是自擁有和獨享的,所以將重要、敏感的數據信息保存在私有云存儲中,可以實現更高的可控制性和安全性;
Unlimited Capacity:因為與公有云存儲的互通,借由公有云存儲無限容量的特性,混合云存儲也具備了無限容量的特性;
Relatively Low Cost:可以選擇將一些歸檔數據、不常訪問的數據以及訪問性能要求不高的數據存儲到公有云存儲中,在節省了私有云存儲部分的成本的同時,還能擁有公有云存儲按需分配的成本優勢,因此混合云存儲相較于私有云存儲,也具有低成本的優勢。
現有解決方案的局限性
混合云存儲相較于公有云存儲和私有云存儲會更加全面,更加完善。Ceph 的對象存儲針對混合云的場景,也相應的提供了解決方案,即云同步Cloud Sync 功能。Ceph RGW 的Cloud Sync 功能是基于RGW Multisite 機制實現的,先看下RGW Multisite 機制。
RGW Multisite
Ceph RGW 的 Multisite 機制用于實現多個Ceph 對象存儲集群間數據同步,其涉及到的核心概念包括:
zone:對應于一個獨立的集群,由一組 RGW 對外提供服務。
zonegroup:顧名思義,每個 zonegroup 可以對應多個zone,zone 之間同步數據和元數據。
realm:每個realm都是獨立的命名空間,可以包含多個 zonegroup,zonegroup 之間同步元數據。
Multisite 的工作機制如下:
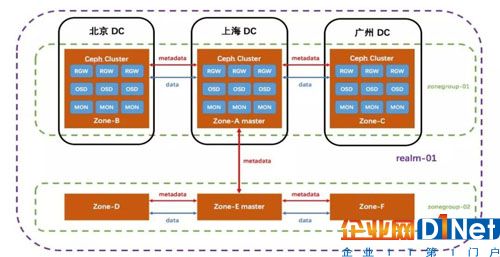
因為Multisite 是一個zone 層面的功能處理機制,所以默認情況下,是zone 級的數據同步,即配置了Multisite 之后,整個zone 當中的數據都會被進行同步處理。
整個zone 層面的數據同步,操作粒度過于粗糙,在很多場景下都是非常不適用的。當前,Ceph RGW 還支持通過 bucket syncenable/disable 來啟用/禁用存儲桶級的數據同步,操作粒度更細,靈活度也更高。
RGW Cloud Sync
基于RGW multisite 實現了 Cloud Sync,支持將Ceph 中的對象數據同步到支持 S3 接口的公有云存儲中,默認為zone 級的數據同步。由上面的介紹可知,RGW的 Multisite 機制是用于實現多個Ceph 對象存儲集群之間、多數據中心之間數據同步的。而 zone 本身是一個抽象的概念,那么從一個抽象程度更高的角度來看,它不單單可以代表一個 Ceph 對象存儲集群。
RGW Cloud Sync 功能正是基于這樣的思想所實現的。在 Cloud Sync 框架中,slave zone 不再僅僅對應一個 Ceph 對象存儲集群,而是一個抽象程度更高的概念,即可以代表任何一個集群,而這個集群可以是 Ceph 對象存儲集群,當然,也可以是AWS的S3。Cloud Sync 功能正是將支持 S3 接口的存儲集群,抽象為 slave zone 的概念,然后通過Multisite 機制,實現將 Ceph 中的對象數據同步到外部對象存儲中。
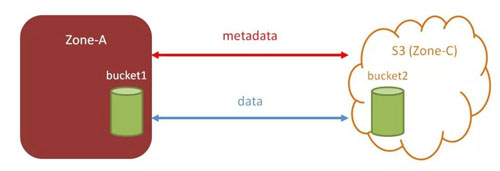
可以通過 bucket sync enable/disable啟用/禁用存儲桶級的數據同步 。
Cloud Sync的局限性
在使用 Ceph 對象存儲時, RGW 的 Cloud Sync 功能實際上是基本可以滿足混合云存儲的應用場景的,但就當前 RGW Cloud Sync 功能的實現來說,還存在如下的局限性:
支持的同步粒度最細為存儲桶級,在某些應用場景下,存儲桶級的同步粒度是不夠靈活的;時間控制,RGW Multisite 的數據同步處理是通過 RGW 自身的協程庫實現的,整個處理過程是異步完成的,且數據同步處理的起始時間無法人為控制,所以這個數據同步處理的時間控制不夠靈活,一些時間敏感的場景并不適用。
基于Ceph的分級混合云存儲方案UMStor
有了上面這諸多局限性,我們開始考慮能否實現一種管理粒度更細、時間可控性更好的機制,來提供一種更為靈活的數據管理和遷移方案。通過對象數據存儲分級、對象生命周期管理、自動生成遷移等系列實踐,我們開發了一款基于Ceph的分級混合云存儲解決方案UMStor。
解決方案一:對象數據存儲升級
首先,我會介紹我們如何在 Ceph 對象存儲中實現 Storage Class,對對象數據進行存儲分級。
對存儲系統分級
為什么要對存儲系統進行分級?我覺得可以從如下三方面進行考慮。
1.存儲介質
首先,在存儲集群當中,出于對訪問性能、成本等因素的考慮,我們可能會同時引入 SSD 和 HDD。在這種情況下,如果不進行存儲分級,就可能會導致某些對訪問性能要求不高的數據,或是歸檔數據,被存儲在 SSD 中,而某些對訪問性能要求較高的數據則被存儲在了 HDD 中,這無疑會影響數據的訪問性能,同時也提高了數據的存儲成本。
2.存儲策略
副本
副本
Erasure Code
那有的數據對可靠性要求很高,我們才會將其以三副本的形式進行存儲。可能有的數據,我們對它的可靠性要求沒那么高,那我們可以考慮將其以兩副本的形式進行存儲,節省存儲空間。
3.存儲提供商
UCloud
AWS S3
所以說,對存儲系統進行存儲分級,實際上是非常必要的。
RGW 數據存放規則
本身在 RGW 中,是存在placement rule概念的,即數據的存放規則。可以在placement rule 中定義存儲桶索引數據存放的存儲池index pool,對象數據存放的存儲池data pool,以及通過Multipart 上傳大文件時臨時數據存放的存儲池data extra pool。

因為placement rule 是針對所使用的存儲池進行定義,而存儲池是位于zone 之下的概念,所以在RGW 中將placement rule 作為一個zone 級別的配置,其作用影響的粒度為存儲桶級,即可以指定存儲桶所使用的placement rule ,那所有上傳到該存儲桶中的對象數據都會按照該存儲桶的placement rule 定義的存放規則進行存放。用戶可以通過為不同的存儲桶配置不同的placement rule 來實現將不同存儲桶中的對象數據存放在不同的存儲介質中或是使用不同的存儲策略。
然而,存儲桶級的數據存放規則,顯然不夠靈活,無法滿足某些應用場景的需求。
對象數據存儲策略
Storage Class 這一概念,本身是AWS S3 中的一個重要的特性。在S3 中,每個對象都具有 “storage-class” 這一屬性,用于定義該對象數據的存儲策略。在 S3 中Storage Class 特性支持如下幾個預定義的存儲策略:
STANDARD針對頻繁訪問數據;
STANDARD_IA用于不頻繁訪問但在需要時也要求快速訪問的數據;
ONEZONE_IA用于不頻繁訪問但在需要時也要求快速訪問的數據。其他 Amazon 對象存儲類將數據存儲在至少三個可用區(AZ) 中,而S3 One Zone-IA 將數據存儲在單個可用區中;
REDUCED_REDUNDANCY主要是針對一些對存儲可靠性要求不高的數據,通過減少數據存儲的副本數,來降低存儲成本;
GLACIER。
結合上面介紹的分布式存儲系統對存儲分級的需求,以及當前 RGW 中所支持的data placement rule 的機制,我們在Ceph 對象存儲中引入了object storage class 的概念。
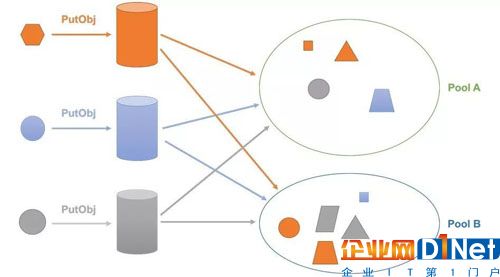
首先,我們對存儲池的概念進行了更高程度的抽象,不僅可以按照當前 Ceph 對象存儲支持,同時:可以按照不同的存儲介質來劃分存儲池 (HDD/SSD);可以按照不同的存儲策略(數據冗余策略)來劃分存儲池 (2x Replication/ 3x Replication/ Erasure Code);可以把外部存儲 (包括外部公有云存儲、私有云存儲) 抽象為存儲池;
將 RGW zone 的 placement rule 的作用范圍進行了細粒度化的處理,使其作用到對象級別,實現了對象級別的存儲分級, 即使是同一個存儲桶中,不同的對象數據也可以保存在不同的存儲池中。
解決方案二:對象生命周期管理
在實現了對象級別的 Storage Class 功能之后,我們開始考慮,如何實現數據遷移時間的可控性。這也就是下面我們要介紹的內容。
AWS S3 對象生命周期管理
對象生命周期管理也是AWS S3 中一個非常重要的特性,通過為存儲桶設置生命周期管理規則,可以對存儲桶中特定的對象集進行生命周期管理。當前,AWS S3 的對象生命周期管理支持:
遷移處理,即支持在經過指定的時間間隔后,或是到達某一特定時間點時,將存儲桶中的特定對象集由當前的 storage class 存儲類別遷移到另外一個指定的 storage class 存儲類別中;
過期刪除處理,即支持在經過指定的時間間隔后,或是到達某一特定時間點時,將存儲桶中的特定對象集進行清除。
RGW 對象生命周期管理
當前,Ceph RGW 對象存儲實際上也支持LC 對象生命周期管理。但是,因為 RGW 本身并不支持object storage class / placement rule,因此其對象生命周期管理目前只支持Expiration actions 過期刪除處理。
實現完整的對象生命周期管理
基于上面實現的 Object Storage Class,在RGW 現有 LC 實現的基礎上,我們對RGW LC 的處理邏輯進行了擴展,實現了LC 遷移功能,支持通過對象生命周期管理,將對象數據遷移到其他存儲類別 storage class 中,例如支持從SSD 遷移到 HDD,從3 副本池遷移到 2 副本池,從副本池遷移到糾刪碼池,從 Ceph 集群中遷移到外部Ufile 公有云存儲等等,從而實現了完整的對象生命周期管理。支持標準的 AWS S3 ObjectLifecycle Management 的相關接口。
由上面的介紹,我們實現的Storage Class 功能是支持將外部存儲指定為一個存儲類別的,因此,支持通過配置存儲桶的LC 規則,將該存儲桶中的某一特定對象集遷移到外部存儲中,如UFile、S3 等等。
相較于 RGW 的Cloud Sync 功能,通過配置LC 遷移規則將Ceph 集群中的對象數據遷移到外部云存儲具有如下優點:
1. 操作的粒度更細,可以直接以對象為單位,對數據進行操作;
2. 時間可控,可以通過在 LC 規則當中對操作生效的時間進行配置指定,人為控制數據遷移的時間,時間可控性更強;
至此,我們已經在Ceph 對象存儲的基礎上,實現了一套完整的、全粒度支持的數據遷移處理機制,從zone 級、到bucket 級、再到object 級、基本可以覆蓋所有應用場景的常見需求。
解決方案三:自動生成遷移策略
存儲桶日志
存儲桶日志是用于記錄追蹤對某一特定存儲桶的操作和訪問的功能特性。存儲桶日志的每條日志記錄都記錄了一次對相應存儲桶的操作訪問請求的細節,例如請求的發起者、存儲桶名字、請求時間、請求的操作、返回的狀態碼等等。
自動生成遷移策略
根據存儲桶日志中的操作記錄、以及可配置的標尺參數,對存儲桶中的對象數據的熱度進行分析,并按照分析結果自動生成遷移策略,對對象數據進行管理。一張圖來概要介紹下處理流程:
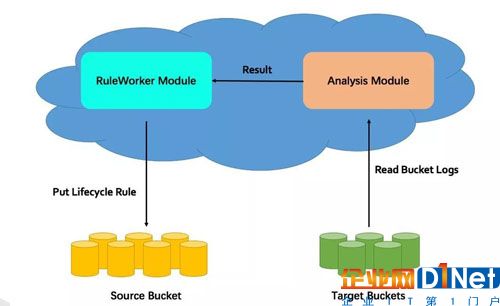
從target bucket 中讀取存儲桶日志;
對日記記錄進行過濾、分析,得到用戶配置的規則中所標定的對象數據的訪問熱度;
生成相應的生命周期管理規則;
將生成的生命周期管理規則配置到相應的存儲桶上。
關于未來
基于Ceph對象存儲的分級混合云存儲方案能夠很好的滿足使用者的需求,但是在支持數據雙向同步、代理讀寫等功能上還要繼續完善。






 京公網安備 11010502049343號
京公網安備 11010502049343號