









01 簡介
在快速發展的數據處理與分析領域中,大型語言模型(LLM)正引領潮流,展現出超越傳統文本應用的突破性功能。其中一個值得關注且潛力巨大的應用領域是利用 LLMs 解讀和推理表格數據。本文將深入探討如何利用 LLMs對表格數據進行查詢,這不僅是一項專業任務,更蘊含著巨大的潛力,它有望革新我們與結構化數據集交互的方式。
在我們的探索中,兩項創新技術發揮著關鍵作用:LlamaIndex 和 LocalAI 。LlamaIndex 在我們的研究過程中扮演著核心角色,它遵循了前沿論文“Rethinking Tabular Data Understanding with Large Language Models” 及“Chain-of-Table: Evolving Tables in the Reasoning Chain for Table Understanding”的指導原則。LlamaIndex 巧妙地實現了這些論文中的策略,將理論轉化為實踐。與此相輔相成的是 LocalAI ,它提供了一個無縫銜接的本地環境,使得用戶可以便捷地在本地啟動 LLM 并與之互動。這種協同效應不僅讓高級數據查詢方法更加普及易用,也將 LLMs的可用性推向了新的高度。
本文將深入淺出地介紹 LLM如何用于查詢表格數據。我們將展示如何使用 LocalAI 提供的 Docker 鏡像來啟動本地 LLM,并展示如何將其與 OpenAI 兼容的 API 服務進行對接。這不僅僅是理論探討,我們將提供實戰演練,全程指導您在 Docker 容器中搭建整套系統,確保其既適用于僅配備 CPU 的機器,也能適應擁有 GPU 設備的環境。
02 理論背景
表格數據領域,其結構化且復雜的特性,為 LLM 帶來了獨特的挑戰和機遇。在本節中,我們將基于兩篇論文的理論基礎進行深入探討,這為我們的實踐探索奠定了基礎。
《Rethinking Tabular Data Understanding with Large Language Models》
這篇論文是理解 LLM在解釋表格數據領域的能力和局限的基礎。它從以下三個核心角度開展論述:
1. 對結構擾動的魯棒性:研究表明,當表格結構發生變化時,LLM 的性能顯著下降。這一發現至關重要,它強調了需要一個即使面對表格格式變化,仍能保持準確性的魯棒模型。
2. 文本推理與符號推理:將文本和符號推理進行比較分析,結果表明在處理表格數據時,文本推理略勝一籌。然而,兩種方法的優勢會根據具體任務的不同而有所變化,在應用這些推理方法時需要根據實際任務進行考量。
3. 通過推理路徑提升性能:最重要的貢獻可能是提出了融合多個推理路徑的方法。通過融合文本和符號推理,并采用混合自洽機制,模型實現了最先進的性能。這種方法不僅提高了準確性,還為大型語言模型中更復雜的表格處理范式鋪平了道路。
備注:結構擾動的魯棒性是評價一個結構設計是否優良的重要指標。即一個結構在受到一些外部或內部的擾動時,能否保持其原有的功能或性能的能力。擾動可以是一些不確定的因素,如參數變化、環境變化、噪聲干擾等。
《Chain-of-Table: Evolving Tables in the Reasoning Chain for Table Understanding》
這篇論文介紹了創新概念:鏈式表格( Chain-of-Table ),徹底改變了 LLM 與表格數據交互的方式:
1. 推理鏈中的表格數據:文中明確提出將表格數據納入推理鏈中。這種方法與傳統依賴上下文的方法截然不同,它提供了一種利用表格結構化特性的全新方式。
2. 迭代式表格演化:該框架引導 LLM 迭代地生成操作并更新表格,從而有效地創建了 "表格推理鏈"。這種動態演化使模型能夠根據先前的結果規劃后續操作,反映出更類似人類的推理過程。
3. 結構化中間結果的動態傳遞:這種方法的一個有趣方面是,通過不斷演進的表格來承載和傳遞中間結果的結構化信息。這一特性不僅使得推理流程更為透明,同時也有助于提升預測的可靠性和準確性。
理論與實踐結合
這些相關論文共同構建了一個堅實的理論框架,指導我們在查詢表格數據中實際應用 大型語言模型(LLMs) 。它們揭示了處理表格數據的細微差別,強調了對模型良好的適應性、復雜的推理能力以及對表格結構化格式敏感的需求。隨著我們探究的不斷深入,這些理論洞見在后續部分將成為我們使用 LlamaIndex 和 LocalAI 進行實踐演示的根基。
03 技術背景
LlamaIndex 及其 Llama Packs
LlamaIndex 是構建大型語言模型應用程序必不可少的多功能“數據框架”。它簡化了從各種來源和格式獲取數據的過程,包括 API、PDF、文檔和 SQL。該框架擅長使用索引和圖表結構化數據,確保與 LLM 無縫兼容。它的一項主要特征是擁有先進的檢索和查詢界面,允許用戶向 LLM 輸入提示詞,并接收到富含上下文的響應。
Llama Packs 補充了 LlamaIndex,它作為社區驅動的中心,提供了一系列預打包模塊,以加速 LLM 應用程序的開發。這些模塊設計廣泛適用于多種應用場景,從創建 Streamlit 應用程序到在簡歷中實現高級檢索和結構化數據提取。Llama Packs 的一項關鍵特性是其賦予用戶的靈活性,用戶不僅可以即插即用地導入現成的模塊,還可以根據具體需求和偏好定制自己的模塊。
LocalAI 框架
LocalAI 的目標是在本地運行開源基礎大模型服務,然后提供與 OpenAI 完全兼容的API,為那些尋求本地推理能力但是又想保持使用OpenAI靈活性的用戶提供了一種獨特的解決方案。LocalAI 功能包括運行LLMs、生成圖像、制作音頻,其應用范圍十分廣泛。此外,LocalAI 還支持多系列模型和架構,無需 GPU 也能高效運行。
04 實際演示
本篇文章可以使用本機環境和阿里云/AWS 為主要演示環境進行呈現。
在Mac電腦(無GPU配置)運行
1.將此存儲庫克隆到您的本機:
1.git clone https://github.com/LinkTime-Corp/llm-in-containers.git
2.cd llm-in-containers/tabular-data-analysis
2.若需要使用 OpenAI 的模型進行推理,將您的OpenAI API密鑰設置到conf/config.json的“OPENAI_API_KEY”中:
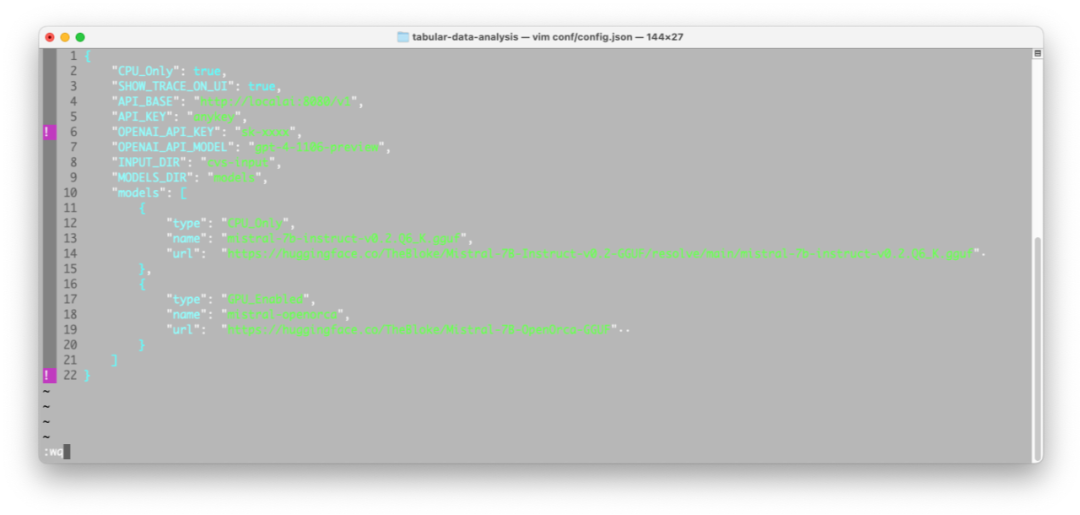
如果用戶的OpenAI 未進行訂閱,這里則需要修改model為:"OPENAI_API_MODEL": "gpt-3.5-turbo"
3.下載本地模型。如果您遇到wget命令的問題,您可以手動從此鏈接(https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.2-GGUF/resolve/main/mistral-7b-instruct-v0.2.Q6_K.gguf)下載模型并保存在'models'目錄中。
bash download-models.sh
4.啟動演示:
注:需要啟動 Docker Desktop`
bash run.sh
5.訪問 http://localhost:8501/ 上的用戶界面
在阿里云/AWS服務器運行
我們在阿里云和AWS上都測試過這個流程,在公有云上的過程中,1-4步和上面設置一樣,請確認服務器上已安裝Docker引擎。
如果服務器上配置有GPU,在第四步的命令中我們可以指定使用GPU來運行LLM:
bash run.sh -gpu
和本地運行不一樣的是,在云上運行的時候我們需要設置防火墻規則之后才能訪問界面。
5.配置防火墻規則
例如,對于阿里云,可參考https://help.aliyun.com/zh/simple-application-server/user-guide/manage-the-firewall-of-a-server
6.訪問 http://{云CPU實例的IP地址}:8501 上的用戶界面
可以在云服務商工作臺處查看服務器的IP地址,或者在連接服務器后使用如下命令查看IP地址:
curl ip.sb
隨后在瀏覽器中訪問 http://{云CPU實例的IP地址}:8501 訪問web ui.
瀏覽器訪問Web UI
現在讓我們通過上傳一些示例數據來使用Web UI:
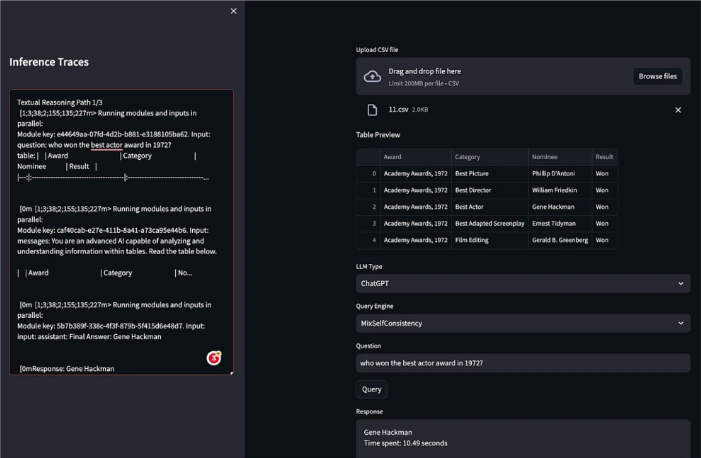
1.訪問提供的鏈接(https://github.com/ppasupat/WikiTableQuestions/releases/download/v1.0.2/WikiTableQuestions-1.0.2-compact.zip)下載一組示例CSV文件。解壓下載的文件。在演示中,我們將使用位于“WikiTableQuestions/csv/200-csv/11.csv”的文件。
2. 進入UI后,首先上傳一個CSV文件,比如剛剛解壓的文件。選擇“LLM類型”來處理您的查詢。您可以在“ChatGPT”和“Local_LLM”之間進行選擇。
3.選擇引擎來查詢您的表格數據文件。有兩個選項:“MixSelfConsistency[1]”和“ChainOfTable[2]”。
4. 選擇完這些選項后,您現在可以根據CSV文件中的數據提問了。例如,“誰贏得了1972年的最佳男演員獎?”點擊“查詢”按鈕提交您的問題,并從選擇的LLM獲得答案。
5. 在UI的側邊欄上,有一個查看LLM推理跟蹤的選項。這個功能可以讓您看到LLM逐步處理您的問題的過程,從而提供了如何得出答案的見解。
05 代碼結構說明該演示的代碼[3]主要包括以下幾個文件:
main.py[4]:該文件包含用戶界面(UI)的代碼。
backend.py[5]:負責處理選擇LLM和查詢引擎的邏輯,并與LLMs進行交互。
constants.py[6]:定義了代碼庫中使用的所有常量。
06 查詢引擎的運作機制
在演示中,我們使用了一個名為“11.csv”的CSV文件,該文件來自“WikiTableQuestions/csv/200-csv”示例數據集。該CSV文件包含在下表中顯示的結構化表格數據。讓我們來探索一下查詢引擎對于問題“哪位提名者在1972年獲得了奧斯卡最佳男演員獎?”是如何回答的。
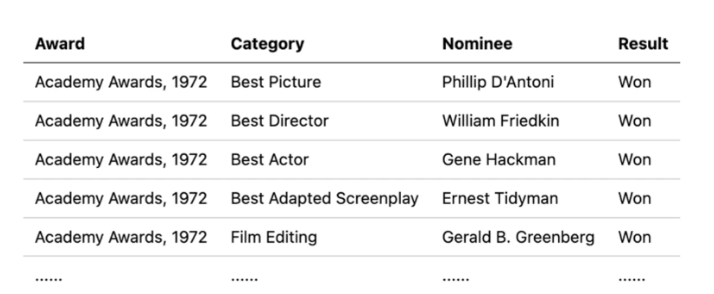
“MixSelfConsistency” 查詢引擎
“MixSelfConsistency” 引擎通過循環遍歷兩種不同的可配置迭代次數的查詢路徑來運行。這兩個路徑分別被稱為“文本推理”和“符號推理”。
“文本推理”路徑
這個路徑很直接。它將 CSV 文件的內容直接整合到提示詞中,從而形成一個綜合查詢,然后輸入給LLM。我們執行了三次這個流程,得到了結果列表:
['Gene Hackman', 'Gene Hackman', 'Gene Hackman'].
“符號推理”路徑
這條路徑使用LlamaIndex的PandasQueryEngine。該查詢引擎將CSV文件加載到pandas數據幀中,然后根據給定的問題生成pandas指令以獲取結果。在演示中,我們得到了三條 pandas 指令,每條指令對應一次迭代運行。
第一次運行:
df[(df['Award'] == 'Academy Awards, 1972') & (df['Category'] == 'Best Actor') & (df['Result'] == 'Won')]['Nominee']
第二次運行
df[(df['Award'] == 'Academy Awards, 1972') & (df['Category'] == 'Best Actor') & (df['Result'] == 'Won')]['Nominee'].iloc[0]
第三次運行
df[(df['Award'] == 'Academy Awards, 1972') & (df['Category'] == 'Best Actor') & (df['Result'] == 'Won')]['Nominee']
因此,結果列表為:
[ '2 Gene Hackman\nName: Nominee, dtype: object', 'Gene Hackman', '2 Gene Hackman\nName: Nominee, dtype: object']
自洽性聚合
最后一步是將從"文本推理"和"符號推理"生成的合并表中統計每個推理結果出現的次數,然后返回出現次數最多的那個推理結果,即為答案。在我們的演示中,出現計數最高并因此被判定為最有可能的答案的推理結果是"Gene Hackman"。
優點和缺點
"MixSelfConsistency"查詢引擎通過融合文本推理和符號推理,并利用混合自洽性機制,提高了準確性。但是,對這些查詢路徑進行多次迭代運算可能會導致整體響應時間變長。
“ChainOfTable” 查詢引擎
"ChainOfTable"引擎最初采用一系列操作將原始表格修改成可以直接處理查詢的格式。隨后,它將經過修改的表格和問題結合起來創建一個提示詞,以便 LLMs 能夠推導出最終答案。這個最后階段類似于“MixSelfConsistency”引擎中的"文本推理"路徑。
表格操作鏈
讓我們深入了解一下它構建操作鏈的方法。在每次迭代中,引擎都會提示 LLM 下一步的操作,同時考慮當前的表格狀態和之前的操作歷史。可能的操作包括:
1. f_add_column():當表格需要額外的推斷數據來準確響應查詢時,使用這個操作添加新列。
2. f_select_row():當只有特定行與問題相關時,使用這個操作來隔離并專注于特定行。
3. f_select_column():與f_select_row()類似,使用這個操作將關注點縮小到回答查詢所需的特定列上。
4. f_group_by():對于涉及具有相同值及其計數項的查詢,使用這個操作可根據這些項進行分組,從而提高數據表述的清晰度。
5. f_sort_by():如果查詢涉及某列中數據的順序或排名,使用這個操作會根據問題的上下文對該項進行排序。
演示案例
回到我們的演示,讓我們重新審視一下查詢:“哪位提名者在1972年獲得了奧斯卡最佳男主角獎?”。作為回應,"ChainOfTable"引擎在第一次迭代時執行了操作f_select_row(['row 3'])。此操作導致創建了一個新的表,結構如下:

最終的查詢變得直接了當,直接得出了最終答案:“Gene Hackman。”
優點和缺點
“ChainOfTable”引擎創建了一系列操作,將原始表格轉化為與最終問題更加吻合的版本。這種方法顯著提高了對那些無法從原始表格中立即得出答案的查詢的準確性,需要一系列表格操作來澄清問題。然而,這個過程要求每次與 LLM的交互都要在提示中包含當前表格的內容。這種方法可能會影響 LLMs 的性能,特別是在處理大型表格時,因為數據的大小直接影響處理負載。
性能比較
在我們的查詢引擎演示中,每次執行查詢都會提供兩個關鍵信息:查詢引擎的響應和生成該響應所需的時間。通過使用演示中的 CSV 文件進行實驗,我們發現當使用 ChatGPT 推理時,"MixSelfConsistency "引擎往往比 "ChainOfTable "引擎更快、更準確。
需要注意的是,這些結果并不是通過系統的基準測試或對兩種查詢引擎的全面比較得出的。我們提到的結果完全基于我們有限的實驗。因此,這些結果應被視為初步觀察結果,而非最終結論。
我們鼓勵對這一領域感興趣的個人以我們的演示為起點,進行更廣泛的比較或基準測試。
07 使用體會與LLMs的交互
在本次演示的實現過程中,一個關鍵部分是與用于查詢的 LLMs 的 API 建立連接。這包括設置與 ChatGPT 的 OpenAI API 的建立連接以及與本地 LLMs 的類似 API 建立連接。以下是代碼的第一部分:
self.openai_llm = OpenAI(model=OPENAI_API_MODEL)self.local_llm = OpenAILike( api_base=API_BASE, api_key=API_KEY, model=MODEL_NAME, is_chat_model=True, is_function_calling_model=True, context_window=3900, timeout=MAC_M1_LUNADEMO_CONSERVATIVE_TIMEOUT,)
此外,設置 ServiceContext 對于 LLMs 也非常重要,特別是對于本地 LLMs 。本地 LLMs 使用的是 Huggingface 的本地 embed_model(來自此文檔https://docs.llamaindex.ai/en/stable/module_guides/models/embeddings.html,本地 embed_model 指的是 “BAAI/bge-large-en” ):
if llm_type == GPT_LLM: chosen_llm = self.openai_llm embed_model = OpenAIEmbedding(embed_batch_size=10) service_context = ServiceContext.from_defaults( chunk_size=1024, llm=chosen_llm, embed_model=embed_model)else: chosen_llm = self.local_llm service_context = ServiceContext.from_defaults( chunk_size=1024, llm=chosen_llm, embed_model="local") set_global_service_context(service_context)
上述實現在功能上是可行的,但在靈活性和切換不同 LLM(如 OpenAI 和本地 LLM )的易用性方面并不理想。在理想的設置中,類似 OpenAI 或 OpenAILike 的類應能夠與 OpenAI 模型和本地 LLMs 建立連接。這可以通過簡單地指定這些兼容 API 的 api_base 和 api_key 來實現。
正如 LlamaIndex 所解釋的那樣,OpenAILike類是對 OpenAI 模型的輕量級封裝。其目的是確保與提供 OpenAI 兼容 API 的第三方工具兼容。然而,目前 LlamaIndex 限制了使用自定義模型的 OpenAI 類的使用,主要是因為需要從模型名稱中推斷出某些元數據。
這個限制說明未來需要優化實現過程,讓用戶更容易集成和切換不同 LLMs,無論是 OpenAI 還是本地 LLMs。
OpenAI兼容的API服務
選擇使用與 OpenAI 兼容的 API 服務作為應用程序和 LLMs 之間的中介是一個戰略性的決定,旨在提高模塊化和增強靈活性。這種方法允許在不更改應用程序代碼的情況下無縫更換 LLMs,從而減輕了直接集成可能出現的兼容性問題。這樣的設置確保應用程序對它們交互的具體 LLMs 保持中立,從而便于更容易地進行更新和維護。
在選擇合適的 API 服務的過程中,我們最初的選擇是 GPT4All Rest API。眾所周知,GPT4All是一個很好的工具,通過在標準硬件上啟用對 LLMs 的使用,使其更加大眾化。然而,現在 GPT4All Rest API 與當前的 OpenAI API 規范不兼容,因此我們無法切換后端的 LLM 服務。隨后,我們評估了 LocalAI ,它被證明與 LlamaIndex OpenAILike 類兼容并且能夠有效地運行。這種兼容性對我們來說十分重要,LocalAI 符合當前的規范,并能夠與我們的框架平滑集成。
管理Docker鏡像的大小
選擇在Docker容器中運行我們的演示是由Docker為LLM應用提供的諸多優勢驅動的,包括增強的可移植性、可重現性、可擴展性、安全性、資源效率和簡化的部署流程。然而,在構建我們的演示的Docker鏡像過程中,我們注意到安裝PyTorch后鏡像大小顯著增加。為了解決這個問題并減小CPU實例的Docker鏡像大小,我們選擇直接從官方的wheel安裝PyTorch,下載地址為 http://download.pytorch.org/whl/cpu:
pip install --no-cache-dir -r requirements.txt \ --extra-index-url https://download.pytorch.org/whl/cpu
此方法顯著減少了壓縮后的鏡像大小,僅為 435.06 MB,而GPU實例的壓縮后大小則變得更大了,為 5.38 GB。對于那些希望用 CPU 實例構建鏡像的人來說,采用這種策略尤為有效,這一策略在功能和效率之間取得了平衡。
















 京公網安備 11010502049343號
京公網安備 11010502049343號