









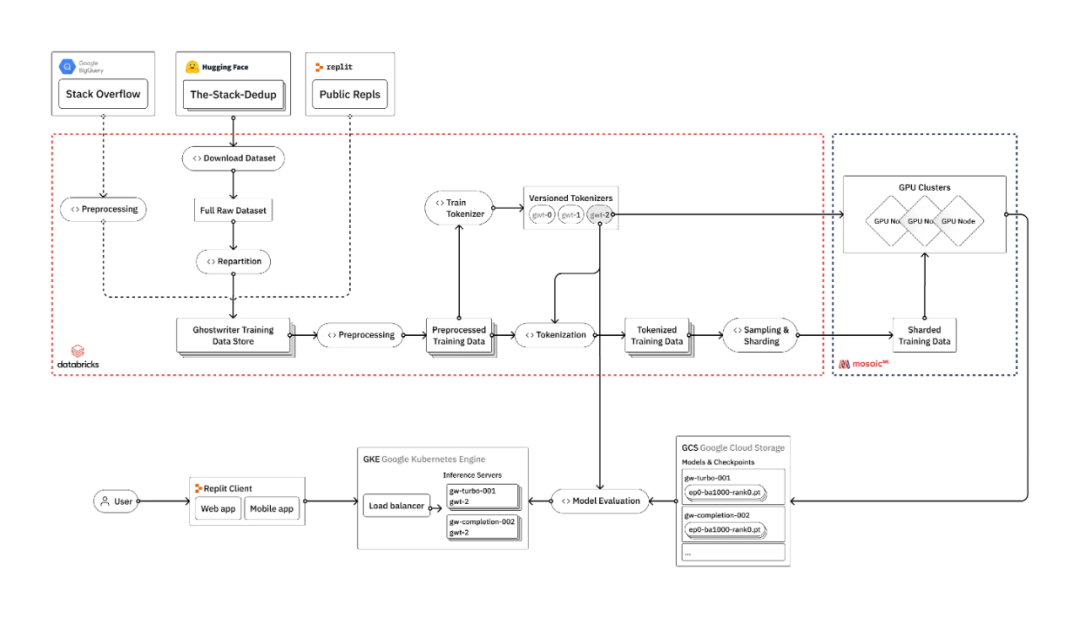
Replit 的一篇博客(https://blog.replit.com/llm-training)里列出了一個非常典型的使用私有數據來訓練和伺服私有大模型的流水線:
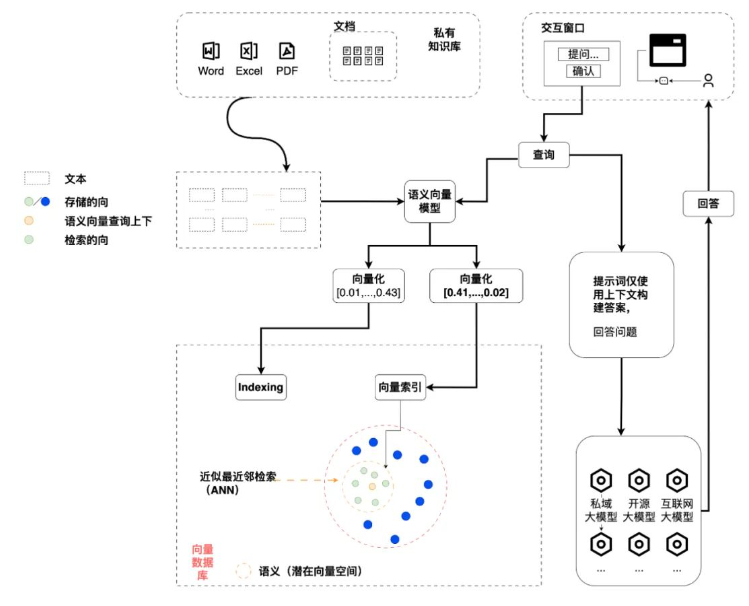
當然,絕大部分企業或者機構都不會太需要自己去訓練一個私有化的大模型,但是即使是做一個簡單的 RAG(Retrieval-Augmented Generation)系統,我們也需要一個完整的文檔處理流水線來持續轉換文檔,劃分文檔為合適的文本塊,選擇合適的 embedding model 和向量數據庫,然后使用 prompt engineering 來構建合理的問題提交給大模型。在目前來說,類似于 LlamaIndex 或者 LangChain 的工具在使用集成的第三方 API 或者內嵌的數據庫來實現快速原型是很方便的,但是如果我們想嘗試獨立的 embedding 模型,高速的分布式向量數據庫,定制化的文檔劃分策略,或者是細分的權限管理,還是有很多額外的工作要處理。
除了基礎大模型之外,大模型生態系統中用來建設一個模型流水線的工具組件可以分為兩大類,第一類是作為第三方庫被其它應用調用,從最底層的 CUDA,PyTorch,Pandas, 到中間的各種 tokenizer, quantization, 到上層的 Transformers, Adapters 等等。第二類一般是作為建設一個完整模型流水線時的一個應用組件,可以獨立運行并完成特定的任務。當然,有些開源系統兩種使用形式都存在,例如向量數據庫,很多既可以獨立運行,又可以作為一個內嵌的組件供應用使用。作為最終模型流水線的搭建者來講,我們直接打交道的大部分是第二類應用組件類型的工具,它們又會去調用很多第一類的第三方庫來完成自己的工作。下面列出了一些常用的應用組件類別以及其代表性開源組件。
1. Model Serving
模型服務工具,將訓練好的模型部署為可供應用程序使用的服務。這些工具通常提供 API 接口,允許開發者輕松地將模型集成到現有的系統中,支持高并發請求,確保模型的響應速度和穩定性。
vLLM: 一個高吞吐量且內存效率高的推斷和服務引擎,主要使用了 PagedAttention 和定制的 CUDA kernel 來提高性能。
GPT4All: 支持在日常硬件上(主要是 CPU 上)訓練和部署 quantized LLM。
Ollama: 方便的在私有化環境下一鍵發布和運行各種開源大模型,提供通用命令行推理工具以及兼容 OpenAI API 的 API 接口。
LocalAI: 主要目標是 OpenAI API 生態體系的本地替代品,允許在本地運行大模型服務,與 OpenAI backend 無縫切換。
2. Training Framework
訓練框架,提供了工具和 API 來簡化大規模模型的訓練過程。這些框架優化了數據處理、模型構建、訓練循環和資源管理等過程,使得開發者可以更專注于模型的設計和實驗。
Megatron: NVIDIA 提出的一種用于分布式訓練大規模語言模型的架構,針對 Transformer 進行了專門的優化(也就是大矩陣乘法)。
Lightning: 支持在大規模分布式環境下使用 PyTorch 進行 AI 模型的預訓練、微調和部署,而無需修改代碼。
3. Scheduling and Orchestration
調度工具,將模型運行在云上或者分布式集群中。
SkyPilot: 主要支持在公有云服務上一鍵運行 LLM、AI 和批處理作業,而無需手動去購買資源以及配置服務器,它可以自動尋找最合適的配置,并在運行完成后自動釋放資源,提供成本節約、提高 GPU 使用效率。
Ray: Ray 是一款基于 PyTorch 的框架,專為并行處理 AI 和 Python 應用程序設計。它提供了高級 API,可用于處理數據、模型、超參數和強化學習等任務,以及核心原語,可用于構建分布式應用或自定義平臺。
4. Document Processing
文檔處理工具,專注于從非結構化數據中提取信息和結構,如從 PDF、圖片或文本文件中提取文本內容和元數據。
Unstructured: 提供了用于攝取和預處理圖像和文本文檔的開源組件,例如 PDF,HTML,Word 文檔,和更多其他格式。它的模塊化功能和連接器形成了一個統一的系統,簡化了數據攝取和預處理,使其能適應不同的平臺,并有效地將非結構化數據轉化為結構化輸出。
Apache Tika: Apache Tika 工具套件可以檢測并提取來自一千多種不同文件類型(如 PPT、XLS 和 PDF)的元數據和文本。所有這些文件類型都可以通過單一接口進行解析,使 Tika 對于搜索引擎索引、內容分析、翻譯等都非常有用。
5. VectorDB
向量數據庫,專門用于存儲和檢索向量數據,主要用于實現基于相似性搜索和 RAG 系統中。
Milvus: 主要特點是支持分布式發布以及并行處理,底層使用 etcd, MinIO, Pulsar, RocketMQ 等分布式處理組件,在生產環境上可以快速支持彈性擴展。
Chroma: 主要特點是安裝快速方便,資源開銷小,依賴簡單,適合用在嵌入式場景下,快速構數據搜索應用。
6. Application Framework
應用框架,提供了構建特定應用程序的基礎設施和組件,如語言模型的索引和檢索、聊天機器人的對話管理等。
LlamaIndex: 簡化 LLM 和外部數據源(比如 API、PDF、SQL 等)之間進行交互的工作,可以快速實現基于數據的大模型應用。它提供了對結構化和非結構化數據的索引,有助于簡化處理不同的數據源。它能夠存儲提示工程所需的上下文,處理上下文窗口過大時的限制,并在查詢期間幫助平衡成本和性能的關系。
LangChain: 將各種大模型功能以 chain 的方式集成起來,幫助開發人員低代碼快速開發端到端大模型應用。LangChain 提供了一整套的工具、組件和接口,能夠方便地處理與語言模型的交互,連接多個組件,以及整合額外的資源,如 API 和數據庫。
7. Finetune
微調工具,允許開發者在特定的數據集上調整預訓練模型的參數,以提高模型在特定任務上的表現。
Llama Factory: 基于 PyTorch,用于微調和二次訓練 LLM 的框架。支持多種微調方法和優化技術,如 LoRA、QLoRA、P-Tuning 等,可以在有限的算力和數據下,定制開發專屬的領域大模型。還提供了一個名為 LLaMA Board 的網頁界面,可以方便地調整模型參數和查看訓練結果。
HuggingFace TRL: 一個基于 PyTorch 的框架,用于使用強化學習訓練 Transformer 的模型。它提供了一整套工具,從監督微調(SFT)、獎勵建模(RM)到近端策略優化(PPO)等步驟,可以方便地定制和優化語言模型的性能和品質。它還支持多種預訓練模型、數據集、采樣方法和訓練輔助功能,涵蓋了不同的任務需求。
8. RAG: RAG
(Retrieval-AugmentedGeneration)
是一種結合了檢索和生成的技術,用于提高語言模型在特定任務上的表現,如問答和文本生成。
PrivateGPT: 私有發布的 RAG 平臺,使用 LlamaIndex 搭建 RAG 流水線,在本地運行 Chat UI,提供大部分模型管理以及文檔管理功能,同時提供 OpenAI API 兼容的接口,可以方便地與現有的應用集成。
LocalGPT: 使用 LangChain,llama-cpp 和 Streamlit 搭建的 RAG 平臺,主要特點是支持各種 quantized LLM 和 CPU 運行,可以快速在單機上運行。
9. ChatBot
集成聊天機器人,專注于構建和部署交互式對話系統,一般提供對話管理、提示詞工程管理、歷史管理的功能。
NextChat: 用于快速創建和部署跨平臺的 ChatGPT/Gemini 應用,可以快速地搭建自己的私人聊天機器人,支持 GPT3, GPT4 和 Gemini Pro 等多種語言模型以及提示詞管理,歷史管理等核心功能,提供 Linux / Windows / MacOS 客戶端。
Jan: 提供了一個跨平臺的本地 ChatBot 桌面應用,支持 Linux / Windows / MacOS,內嵌使用其自主開發的 Nitro 推理引擎來運行大模型,可以作為一個完全離線的 ChatGPT 替代產品。
然而,使用這個生態系統搭建模型流水線的一個主要挑戰是管理和維護各種依賴項的兼容性,包括 Python 版本、第三方庫版本、CUDA 版本以及硬件和操作系統的兼容性。這些因素共同構成了一個復雜的環境,經常導致版本沖突和不兼容的情況。此外,如何將各個組件的配置統一管理起來,不用重復配置,不用手動配置各種端口以避免沖突,動態管理依賴,也是常見需要解決的問題。除了應用運行之外,數據在這些組件之間的流動也需要完善的管理以保證數據的正確性以及數據任務的及時完成。這些問題聽起來是不是有些熟悉呢?是的,這些問題其實還是屬于傳統數據流水線(Data Pipeline)和運維(DataOps)的范疇,只不過多了幾個特定功能場景:使用 GPU 或者 CPU 來發布大模型,用 sequence 數據(大部分是文檔)來 finetune, pretrain 大模型,或者用大模型來進行 inference 服務或者以 agent 形式提供自動操作。在 A16Z 的“Emerging Architectures for LLM Applications”博客中列出的大模型應用技術棧中,除了 Data Pipelines 本身就屬于這個技術棧的一部分之外,類似 Embedding Model, Vector DB, Logging/Observability, Orchestration 這些組件,其實和 DataOps 中相應的組件的管理運營方式差別不大,特別是在云原生和容器化這個方向上,基本是一致的。
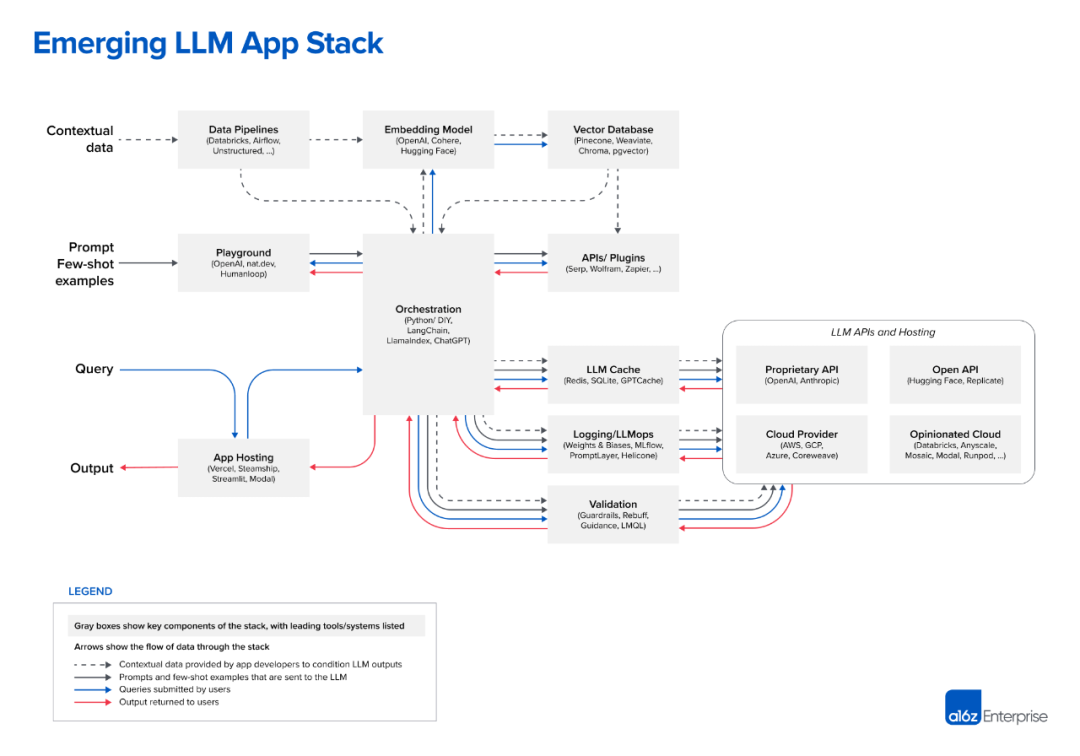
所以,我們認為,將這些組件以容器的形式實現標準化發布(上面的組件中很多都已經提供 Docker 發布方式),使用類似于 Kubernetes 這樣的資源調度平臺來管理這些組件的運行,可以大大降低大模型流水線的使用門檻,提高大模型應用發布和運行的效率。而且,不管后端的基礎大模型如何變化,這樣建設流水線的工作都是需要的甚至我們可以說,為了適應快速迭代的基礎大模型,我們應該以云原生,容器化,服務化,標準化的方式建設我們的大模型流水線,允許我們在不同的私有發布,公有發布的大模型之間隨意切換,選擇最適合我們應用場景和和價格最合適的大模型使用模式。我們將會在”容器中的大模型”系列博客中,以不同的大模型應用場景(例如 RAG,Text2SQL 等等)為例,展示如何以容器化的方式發布這些開源大模型應用組件并合理地將它們組織起來來完成具體場景的工作。希望這些博客能為準備建設大模型流水線的讀者提供一些參考,也非常期待大家的反饋和建議。
















 京公網安備 11010502049343號
京公網安備 11010502049343號