


科學大數據應用場景及管理需求
科學大數據的應用場景及典型特征
科學數據是科研活動的輸入、輸出和資產,是證實或者證偽科學發現或科學觀點事實、證據或者論證推理的基礎。它包括數字化觀測、科學監測等來自儀器設備或傳感器的數據,計算模擬與模型輸出的數據,對情景或現象的描述,對行為的觀測或定性描述,以及用于管理或者商業目的的統計數據等。目前科學大數據普遍存在于各個領域的科學研究,尤其在天文學、高能物理、微生物學等大科學領域,科學大數據的應用場景尤為明顯。
在天文學領域,中法合作伽馬暴探測天文衛星SVOM?的關鍵地面設備?GWAC?的每個相機?15?s?內會產生?32?MB?的天區圖,并于下一個天區圖產生之前完成點源提取、交叉認證等操作,最終在?3—5?s?內完成?100?萬—10?000?萬行星表數據的插入,10?億—100?億行星表數據的?JOIN?運算。
在高能物理領域,歐洲核子物理研究組織構建的大型強子對撞機(LHC)每秒進行?6?億次碰撞實驗,產生?6?PB?事例數據,經事例篩選后存儲大約?1?GB?實驗數據。目前?LHC?產生的實驗數據已超過?200?PB,未來?5?年?LHC?產生的數據將會超過?1?EB,事例數將達到千萬億級別,需在?10?s?內完成百萬分之一的事例篩選操作。
在微生物學領域,中國科學院微生物研究所世界數據中心(WDCM)對?Taxonomy、GenBank、Gene?等?36?個數據源進行實體識別、歧義消除、本體構建等數據處理操作,構建了包含?830?萬個節點、1.3?億條邊的知識圖譜結構。預計未來?5?年內,WDCM?還將匯聚開放生物資源、文獻、序列和疾病等數據,在?10?000?多個數據源中構建?100?億條關聯的知識圖譜數據,并要求?1?s?內完成?100?億條關聯數據的?6?步關聯查詢。
自?2011?年麥肯錫年度總結報告中提出“大數據”概念以來,學術界和工業界對大數據定義一直存在爭議,這些爭議主要來自不同領域中大數據的特征體現。目前學術界公認大數據具有“4V”特征——體量大(volume)、生成快(velocity)、多樣性(variety)和密度低(value),科學大數據應用場景充分體現了這“4V”特征,并具有以下獨特的性質。
科學發現的準確性建立在海量實驗數據的重復計算驗證之上。例如,“上帝粒子”和暗物質發現的正確性經過了對數百?PB?量級數據的多次重復計算,多次驗證重復出現同一結論時才能發布結論。
短時間內科學實驗會產生大量觀測數據并進行流程化處理,實驗數據會持續進入持久化存儲設備進行長周期存儲。例如,GWAC?在?15?s?內完成?40×32?MB?天區圖的點源檢測、入庫等操作,產生的所有數據將永久存儲。
科學現象觀測的量化指標存在圖像、語音、時間序列等形式,數據分布在不同國家和機構中,科學研究需要整合這些多源異構數據。例如,WDCM?整合?36?個包括文本、網頁、醫療記錄在內的數據源完成知識圖譜構建。
科學數據來自大科學裝置、互聯網、國家機構等,數據與國家利益和個人隱私相關,數據共享和挖掘分析會產生更大的社會推進作用。例如,“數字絲路”(DBAR)國際科學計劃涉及“一帶一路”沿線?65?個國家共享的地理、農業、社會輿論等數據,挖掘分析這些數據可為地區、國家的決策提供重要參考,然而如何分享成果收益、保護數據隱私是該計劃面臨的一個重要問題。
科學大數據的這些性質對數據管理系統提出了巨大挑戰。
科學大數據管理的挑戰
科學大數據管理涉及數據的收集、存儲、處理、分析、可視化和共享等全生命周期管理。如圖?1?所示,科學應用首先從科學裝置接入或從互聯網采集大量異構實驗或觀測數據,然后經過初步過濾、轉換等數據預處理操作存入持久化設備形成原始科學數據。針對具體科研目標,應用對原始數據進一步運算抽取實驗特征形成特征數據。科學應用對特征數據整合挖掘分析形成科學發現量化指標,并通過可視化的方法將科學發現展現出來。最后整個流程中產生的所有數據都將存檔、發布以備將來查詢、驗證等科研目標使用。
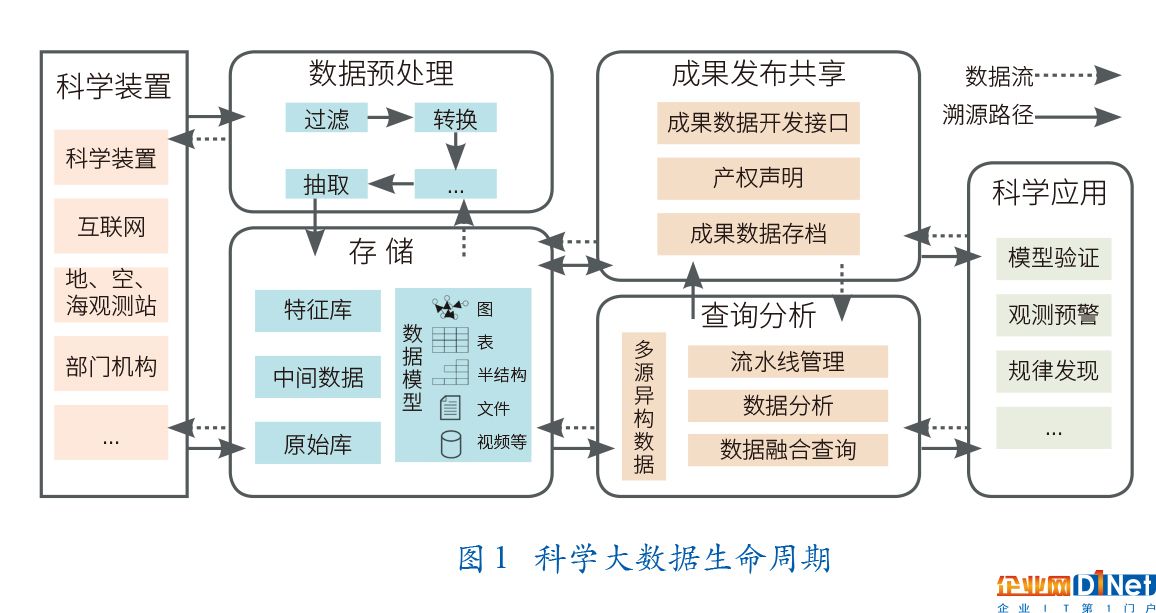
科學大數據管理存在常見的“4V”問題,同時也具有獨特的性質,這些性質決定了科學大數據管理系統生命周期中面臨?4?個方面的挑戰(SPUS)。
規模動態化(Scale Dynamic)。科學實驗持續產生海量科學數據,并需進行長周期持久化存儲。比如上文中提到的大部分科學研究項目(如?GWAC、LHC等)每秒產生?GB?量級的觀測數據,并且數據無失效期,然而科研機構卻無法事先確定存儲和計算資源的配置以最優地滿足科學應用需求。因此,如何彈性動態地為這些數據分配存儲空間和數據處理資源是科學大數據管理需要面對的一個重大挑戰。
流水線管理(Pipeline Management)。科學實驗有嚴密的實驗步驟,科學裝置產生的海量原始科學數據會經過大量的特征提取、轉換、分析等數據加工操作最終產出科研成果。以?GWAC?新星發現應用為例,原始數據進入系統以后,系統需要完成特征提取、交叉認證等嚴密的數據處理操作;新星預警發生后,系統需要溯源到預警產生的特征記錄、天區圖、鏡頭等并對它們進行反復確認。此外,同一個科學裝置下也會出現大量類似的實驗流程,因此有效地創建、執行、管理這些實驗步驟和數據將極大提高科學實驗的效率。
統一訪問(Unified Access)。大科學應用經常會對不同領域、不同機構的異構數據進行融合挖掘分析。以中國科學家發起的?DBAR?國際科學計劃為例,為了給地區決策提供參考,需要獲取天、空、地綜合數據資源構建共享的地球大數據平臺。這其中涉及衛星遙感數據、氣候觀測站數據、生物觀測站數據以及社交網絡中的輿論熱點數據等異構數據的融合管理。因此,如何用統一的方式訪問多源異構數據將極大地提升科學發現的價值和規模。
共享管理(Sharing Management)。科學實驗產生的成果數據以及中間數據通過互聯開放共享以便集全世界科學家的力量進行實驗驗證、模型改進等后續科學研究,比如全世界物理學家通過互聯網從?LHC?中獲取數據進行粒子發現實驗,并通過互聯網共享科研成果。科學數據開放性帶來的重大問題有:數據提供者與科研人員如何合理劃分科研成果、數據提供者著作權認證和激勵機制、共享數據的隱私保護等。如果不能妥善解決這些問題,將影響科研人員的積極性和科研生態圈的健康發展。
科學大數據管理系統體系架構
科學大數據管理系統主要由?4?個核心部分構成:計算和存儲管理、數據流水線管理、數據融合查詢管理和數據共享管理,系統體系架構如圖?2?所示。計算和存儲管理組件需要支持海量數據的存儲和處理,并隨著數據量增長動態地擴展其存儲和處理能力;數據處理流程統一管理組件需要支持數據流水線的數據接入、執行、溯源和分享等一站式統一管理;數據融合管理組件需要提供對多源異構數據的統一查詢分析接口;數據共享管理組件需要規范科學發現的權益劃分、數據共享的隱私保護與激勵機制。
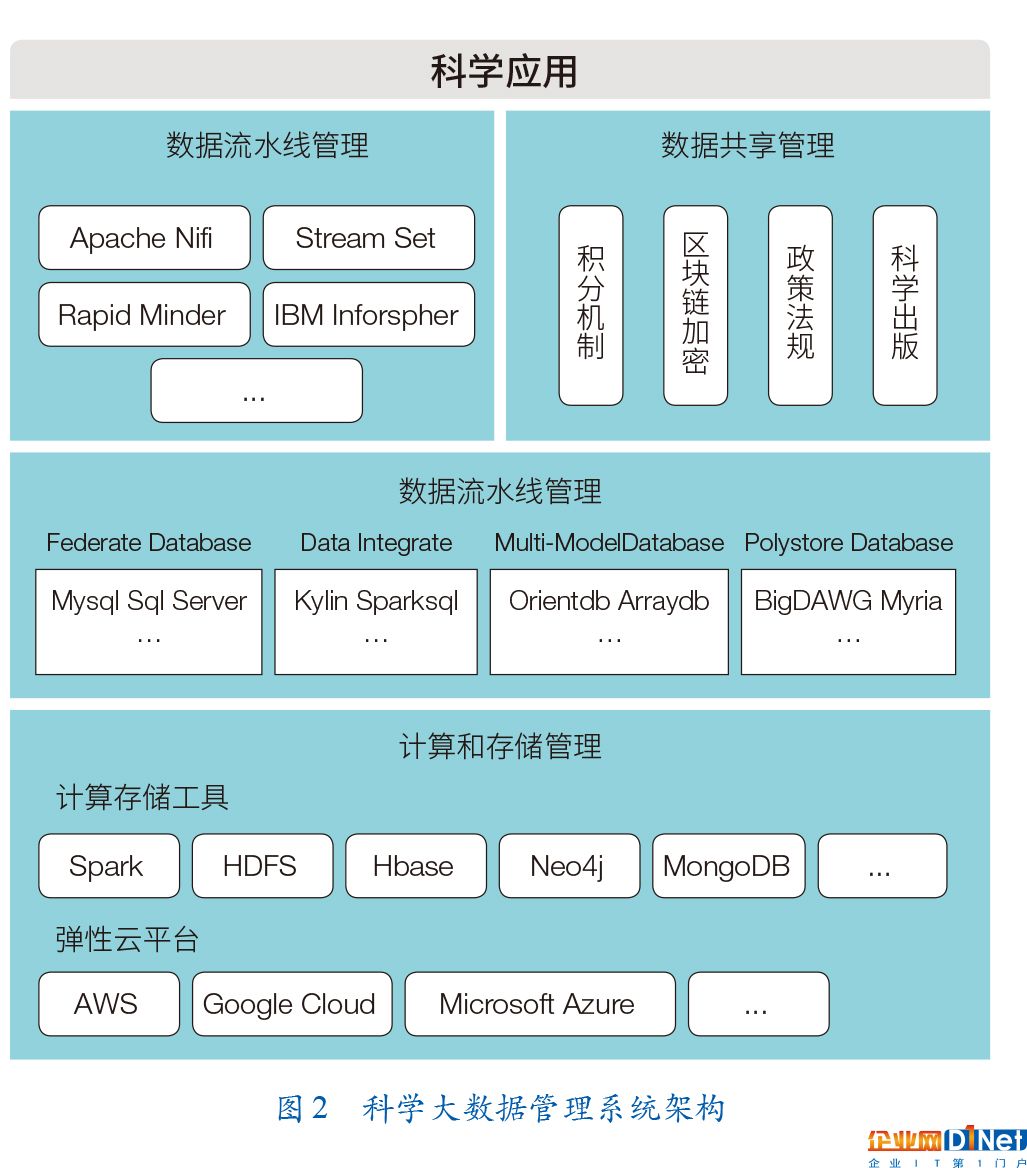
計算和存儲管理組件。即計算和存儲資源隨上層應用負載規模的變化而彈性伸縮,從而達到處理時間與資源投入的比例最優化。目前,彈性伸縮分為漸進式和定量式兩種方案。漸進式伸縮方法監控上層應用對底層計算和存儲資源的競爭度,動態地增加或縮減底層資源。例如,在?AWS?云平臺的?E-MapReduce?集群上運行的?MapReduce?作業對資源的競爭度是集群剩余可用內存的數量,競爭度超過閾值會將新計算或存儲節點納入集群從而完成集群的自動擴容。定量式伸縮方法是通過預估目標應用的計算和存儲資源需求,提前確定應用的計算和存儲資源規模。與漸進式伸縮相比,定量式伸縮的反應時間較短,然而定量式伸縮方法高度依賴對目標應用的計算和對存儲資源需求的準確預估,如通過建立目標應用的負載模型預估系統的計算和存儲資源。
數據流水線管理組件。通過對數據處理流程的抽象,將數據處理過程映射為流水線中的若干邏輯處理單元,從而對數據處理過程進行規范和統一管理。通常情況下,流水線中?1?個處理單元代表?1?個函數、WebService?或?SQL?語句等,處理單元的輸出可以作為其他?1?個或多個處理單元的輸入;通過分支、循環等方式,這些處理單元組裝在一起統一管理完成科學發現的流程。流水線管理與工作流、指令流等有相似的形式化表示,如?Pi?代數、Petri?網等,通過這些流水線形式化表示,系統可在理論上保證執行過程的準確性并對異常進行捕獲處理。在實際應用中,除了保證流水線的正確運行之外,流水線管理還需要解決數據接入、數據溯源、中間數據轉換等核心問題,常見的流水線管理工具有?Apache Nifi、Stream Set?等。
數據融合查詢管理組件。即用統一的方式訪問分析多源異構數據。目前數據融合主要有聯邦數據庫(Federate Database)、多模型數據庫(Multi-model Database)、多存儲數據庫(Polystore Database)、數據集成(Data Integration)4?種方式。聯邦數據庫將多個自治的異構或同構數據庫中的數據透明地映射到一個全局視圖中,具有自治、異源或異構、分布式的明顯特征,比如在?SQL Server?2000?和?Mysql?5.0?中的?Federate?功能。多模型數據庫是指一個數據庫后端存儲多種類型的數據,如?OrientDB、ArangoDB?等。多存儲數據庫架構沒有統一全局視圖,而是由局部視圖和中間視圖構成,通過統一的查詢語言進行查詢,典型的?Polystore?架構有?BigDAWG、Myria?等。根據數據轉換的方式,數據集成可以分為在線集成和離線集成兩種方式。離線集成將不同數據源中數據通過?ETL?轉換,存儲在全局視圖數據源中進行統一管理分析,如數據倉庫、數據湖泊、DataHub?等方式。在線集成通過解析查詢語句將局部視圖中的數據在線轉換為全局視圖,如?Sparksql、Impala、Presto?等。
數據共享管理組件。該組件的根本任務是疏通數據擁有者到用戶之間的鏈路,促進數據資源在擁有者和用戶之間的流通、傳播與重用。目前科學數據共享機制模式的研究主要集中在數據匯交機制、數據出版機制、數據聯盟機制和服務激勵機制(積分機制、在線計算服務模式)4?個方面,如王晴、李成贊等從政策法規、技術保障、評價激勵等方面對數據共享機制進行了深入分析和論證。數據共享的隱私保護技術中最具代表性的是區塊鏈技術,如丁偉等、翁健等提出了基于區塊鏈的數據共享方法,通過公私鑰等非對稱加密算法將數據存儲在區塊鏈上,從而更大程度上保護了用戶數據的隱私,并在醫療、基因等領域進行了驗證。
科學大數據管理系統項目進展
依托國家重點研發計劃項目“科學大數據管理系統”和中國科學院“十三五”信息化建設“科學大數據工程”項目,我們與計算機領域及天文學、高能物理、微生物學等學科領域的?20?多家科研單位進行合作,對科學大數據管理進行了探索,研發了一套科學大數據管理系統?BigSDMS(Big Scientific Data Management System)。該項目的核心內容主要包括?3?個部分:科學大數據管理引擎、科學大數據系統集成和科學大數據應用示范。項目研發的系統總體架構如圖?3?所示。

科學大數據管理引擎
BigSDMS?包括?3?類科學大數據管理引擎:大規模圖數據管理、大規模半結構數據管理和大規模關系型數據管理。其中,大規模圖數據庫?Gstore?支持?100?億條三元組圖數據管理和秒級查詢響應時間。大規模半結構化數據庫?Eventdb?支持萬億級高能物理實驗事例、EB?量級數據管理能力。大規模關系型數據庫?AstroSever?支持千億行天文星表數據的管理,大、中、小規模數據典型操作的查詢優化及滿足數據處理精度與實時性的要求。這?3?類數據庫基本滿足了目前常見科學實驗中大規模數據的存儲、訪問等管理需求。
科學大數據系統集成
BigSDMS?集成包含彈性部署(EMR)、流水線(Piflow)、融合查詢(Simba)和數據共享(Pishare)4?個部分。其中,EMR?的彈性伸縮方案綜合使用漸進式伸縮和定量式伸縮的優點:當負載模型可信度低于閾值時,采用漸進式方法進行伸縮,并根據擴容后的資源競爭修正負載模型;若負載模型可信度達到閾值后則采用定量式伸縮方法。Piflow?基于?Petri?網,處理單元(processor)在未知狀態(unknown)、活躍狀態(active)、休眠狀態(hibernated)3?種狀態之間進行轉換,完成流程的執行與監控。Simba?基于?Sparksql,在?Zeppelin?可視化界面中通過?SQL?查詢進行多種數據源的融合查詢分析。Pishare?基于開源區塊鏈項目?Hyperledger,在區塊鏈上?Pishare?會對數據進行加密存儲和產權認證,并通過積分機制(科學幣)對數據提供者進行獎勵以及數據市場的交易。
科學大數據應用示范
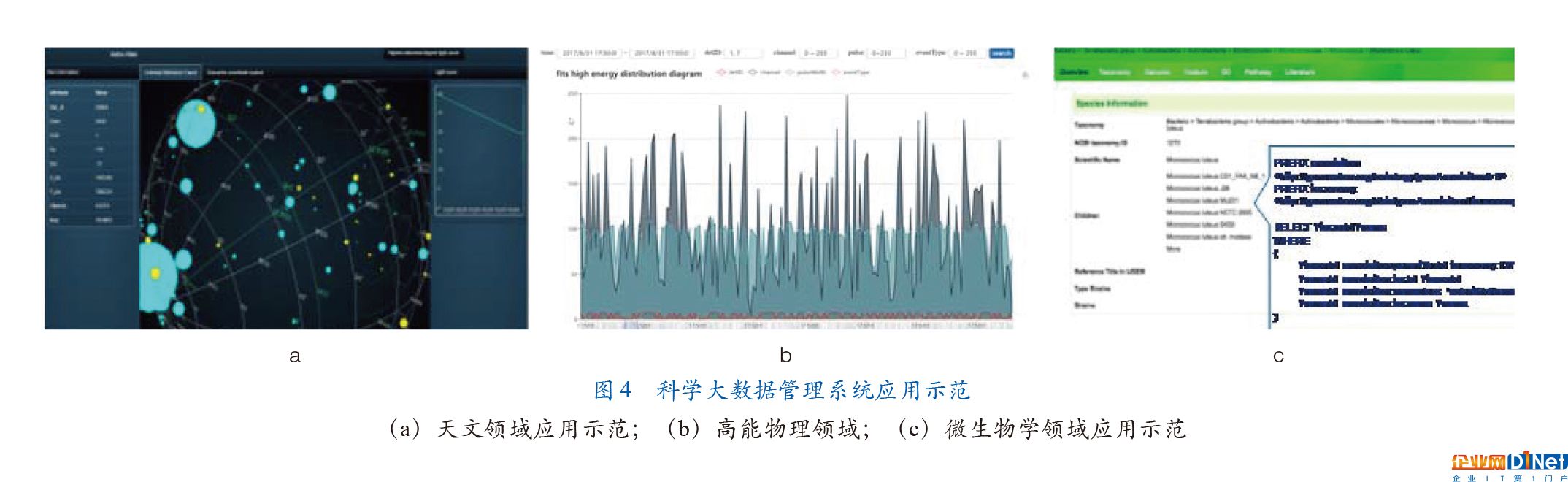
目前,基于?BigSDMS,我們在天文學、高能物理、微生物學領域構建了?3?個應用示范:①天文學領域使用了?100?億行星表數據,定義了?5?個光變曲線處理流程,實現?680?萬行星表數據插入時間少于?3?s,“異常發現”時間小于?1?s(圖?4a);②高能物理領域使用了?BESIII?產生的?942.9?億條事例數據,相對于業界常用的?Boss?查詢平均查詢效率提高?10?倍以上(圖?4b);③微生物學領域整合了?200?種微生物種菌信息,構建了?5?億條規模的?RDF?知識圖譜數據(圖?4c)。
隨著人類對客觀世界的深入認知,越來越多的社會和自然現象能夠通過觀測設備進行量化,這將導致科學數據的體量和類型持續增加。在數據驅動的科學發現模式下,應對科學大數據管理的?SPUS?挑戰已成為眼下刻不容緩的任務。由中國科學院計算機網絡信息中心牽頭的國家重點研發計劃“科學大數據管理系統”項目對這些問題進行了深入探索,研發了一套科學大數據管理系統?BigSDMS。未來我們還會在彈性部署、流水線、數據融合和數據發布共享?4?個方面進行更深入的探索,如競爭度的量化與預測、流水線中間數據模型設計、多查詢引擎的?Polystore?方式集成、數據共享機制優化等。隨著科學大數據管理技術和系統研究不斷深入,科學大數據對科學發現的貢獻將會越來越大!








 京公網安備 11010502049343號
京公網安備 11010502049343號