Spark是一個用來實現快速而通用的集群計算的平臺。在速度方面,Spark擴展了廣泛使用的MapReduce計算模型,而且高效地支持更多計算模式,包括交互式查詢和流處理。
一.基礎知識
1.Spark
Spark是一個用來實現快速而通用的集群計算的平臺。
在速度方面,Spark擴展了廣泛使用的MapReduce計算模型,而且高效地支持更多計算模式,包括交互式查詢和流處理。
Spark項目包含多個緊密集成的組件。Spark的核心是一個對由很多計算任務組成的、運行在多個工作機器或者是一個計算集群上的應用進行調度、分發以及監控的計算引擎。
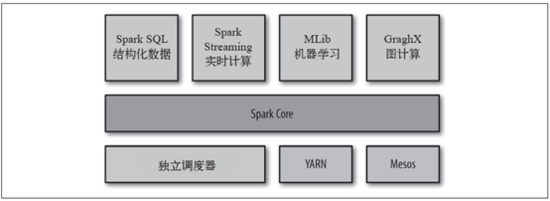
Spark的各個組件
2.hadoop
Hadoop是一個由Apache基金會所開發的分布式系統基礎架構。
用戶可以在不了解分布式底層細節的情況下,開發分布式程序。充分利用集群的威力進行高速運算和存儲。
Hadoop的框架最核心的設計就是:HDFS和MapReduce。HDFS為海量的數據提供了存儲,則MapReduce為海量的數據提供了計算。
二.大數據處理選擇
根據Spark和Hadoop的基礎知識,我們了解Spark和Hadoop都 可以進行大數據處理,那我們如何選擇處理平臺呢?
1.處理速度和性能
Spark擴展了廣泛使用的MapReduce計算模型,其中Spark有個Directed Acyclic Graph(DAG有向無環圖)執行引擎,支持循環數據流和內存計算。
Hadoop是磁盤級計算,進行計算時,都需要從磁盤讀或者寫數據,同時整個計算模型需要網絡傳輸,導致MapReduce具有高延遲的致命弱點。
據統計,基于Spark內存的計算速度比Hadoop MapReduce快100倍以上,基于磁盤的計算速度也要快10倍以上。
2.開發難易度
Spark提供多語言(包括Scala、Java、Python)API,能夠快速實現應用,相比MapReduce更簡潔的代碼,安裝部署也無需復雜配置。使用API可以輕松地構建分布式應用,同時也可以使用Scala和Python腳本進行交互式編程。
3.兼容性
Spark提供了一個強大的技術棧,基于”One Stack to rule them all”的理念實現一體化、多元化的大數據處理平臺,輕松應對大數據處理的查詢語言Spark SQL、機器學習工具MLlib、圖計算工具GraphX、實時流處理工具Spark Streaming無縫連接。
Hadoop的技術棧則相對獨立復雜,各個框架都是獨立的系統,給集成帶來了很大的復雜和不確定性。
4.相互集成性
Spark可以運行在Hadoop集群管理Yarn上,這使得Spark可以讀取Hadoop的任何數據。同時它也能讀取HDFS、HBase、Hive、Cassandra以及任何Hadoop數據源。




























