


存儲供應商PureStorage公司的演講報告引用了其他兩家供應商的兩個數據點:首先,思科公司2017年6月發布的白皮書“Zettabyte時代:趨勢與分析”推斷了互聯網帶寬的增長。其次是由希捷公司委托IDC公司進行研究的調查報告“數據時代2025”推測了全球數據增長的趨勢。PureStorage公司結合了這兩家公司的推斷,得出了結論。如下圖所示。
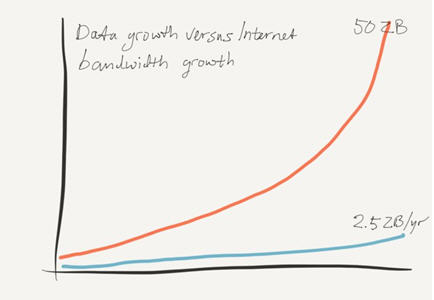
PureStorage公司的報告描述了全球數據增長和全球互聯網帶寬增長之間的沖突
如果這些趨勢成為現實,并且有足夠的理由認為這些預測是合理的,那么這些趨勢將在未來幾年對計算和數據格局產生重大影響。并將對云計算的應用產生特別的影響。注意:云計算是真實的,將成為未來IT環境的重要組成部分,但是IT部門認為它是一種靈丹妙藥這種簡單化的想法,會讓人想起當初網絡熱潮的破滅。而人們知道將會有什么樣的結果。
不能回避的問題
無論如何,所有IT都有兩個核心要素:數據與數據的邏輯。每個使用大數據的人都知道:要使用大量的數據,首先需要對數據進行處理,而其處理都會產生一個傳輸瓶頸,并嚴重影響其性能,并且這種邏輯的任何功能都變成純粹的理論。
即使有少量的數據,這也可能是因為延遲而發生。例如,企業將其應用程序服務器遷移到云端,同時將數據庫服務器保留在本地,這可能在理論上可行,但是當應用程序對數據庫與數據庫之間的網絡延遲敏感時,就根本不起作用。對于少量的數據來說,情況就是如此。這就是為什么許多組織都在嘗試調整軟件的原因,使其對延遲的敏感度降低,從而能夠進入云端。但是,如果數據量很大,則需要將數據處理和數據彼此靠近,否則就無法工作。企業增加對大量并行性的需求來處理這些數據,并獲得Hadoop和其他處理大量數據問題的體系結構。
現在,全球的數據量呈指數增長。如果IDC公司的推測成為事實的話,那么在幾年的時間里,全世界將存儲大約50ZB的數據。另一方面,雖然互聯網傳輸數據的總容量也在增長,但增長速度更為緩慢。在全球數據量增長到50ZB的同一時期,互聯網總帶寬將達到每年2.5ZB(如果思科的推斷成為事實的話)。
從這兩個推斷(并不是不合理的)中得出的結論是,全球可用的互聯網帶寬遠遠不能滿足移動大量數據的需求。而且這也忽略了目前大約80%的帶寬用于流媒體視頻的事實。因此,即使企業已經針對核心應用程序中的延遲問題編寫了代碼,對于數據量較大的情況,也會出現帶寬問題。
現在這個隱患實際上成為了一個問題嗎?如果處理或使用這些數據在本地部署的數據中心發生的話,也就是說在同一個數據中心中存儲數據。但是,一方面,數據量呈指數增長,另一方面,全球各行業也在積極尋求云戰略,就是把將所有類型的工作負載都遷移到云端,即使是“無服務器”(例如,AWS Lambda),這樣的做法也是絕對極端的。
假設只有小規模的結果(從龐大的數據集中計算出來)也許會有所幫助,因為大量數據的實際價值來自它們的結合。這可能意味著將來自不同所有者的數據(例如企業的客戶記錄與來自Twitter的數據)結合起來。而這所有不同的集合將會成為一個難題。
所以,人們看到的是兩個相反的事態發展。一方面,人們都忙于適應基于云的體系結構,這種體系結構最終是基于分布式數據的分布式處理。另一方面,人們使用的數據量越來越大,必須將數據和處理整合到一個物理位置。
那么這意味著什么?
人們可以預期,Hadoop在應用程序架構層面所做的工作也將在全球范圍內發生:龐大的數據集將成為使數據的邏輯具有意義的吸引力。而那些龐大的數據集將會被吸引到一起。
舉個例子:許多公司現在都在努力減少移動數據的需求。因此,在物聯網領域有很多關于邊緣計算的討論:本地處理傳感器和其他物聯網設備的數據。當然,這也意味著處理過程也必須是本地化的,可以放心地假設一下,企業不會在一組傳感器中擁有同樣的計算能力,而不是在大分析中可以做到的設置。或者:也許自主駕駛汽車的數據很可能不會再采用Hadoop集群,而可以通過這種方式來最小化數據流量,但以計算量為代價。
這個問題還有另一個解決方案:與數據中心結合在一起。數據中心托管提供商提供的服務正在崛起。他們提供具有優化內部流量功能的大型數據中心,云計算提供商和大型云用戶的服務器都在一起。從邏輯上講,用戶的業務可能在云端,但實際上與云計算服務提供商在同一處所。
企業不僅想在AWS或Azure上運行其邏輯數據,也想在數據中心這樣做,企業也有自己的私有數據湖,所以所有的數據都在本地處理,數據聚合也在本地。但是數據中心托管模式是另一種可能的解決方案,用于解決因數據呈指數級增長而帶來的帶寬和延遲問題。
情況可能不像那兩個調查報告描述的那樣可怕。例如,所有數據的實際平均波動率最終將非常低。另一方面,企業不希望在陳舊的數據上運行分析。但是可以得出一個結論:簡單地假設企業可以將其工作負載分配給不同的云提供商是有風險的,尤其是如果同時處理的數據量(如果企業都想把他們自己的數據與來自Twitter、Facebook的數據流結合起來,那么更不用說這些組合產生了各種各樣的新數據流)。
因此,企業對數據和處理的位置做出良好的戰略設計決策是成功的關鍵。
版權聲明:本文為企業網D1Net編譯,轉載需注明出處為:企業網D1Net,如果不注明出處,企業網D1Net將保留追究其法律責任的權利。








 京公網安備 11010502049343號
京公網安備 11010502049343號