


本文作者阿薩姆,本文整理自作者在知乎《數(shù)據(jù)科學(xué)工作者(Data Scientist) 的日常工作內(nèi)容包括什么?》問題下的回答。
眾所周知,數(shù)據(jù)科學(xué)是這幾年才火起來的概念,而應(yīng)運(yùn)而生的數(shù)據(jù)科學(xué)家(data scientist)明顯缺乏清晰的錄取標(biāo)準(zhǔn)和工作內(nèi)容。即使在2017年,數(shù)據(jù)科學(xué)家這個(gè)崗位的依然顯得“既性感又曖昧”。
我隨手搜索了幾家國(guó)內(nèi)國(guó)外不同領(lǐng)域的數(shù)據(jù)科學(xué)家招聘廣告(國(guó)內(nèi):阿里巴巴,百度 | 海外: IBM,道明銀行,Manulife保險(xiǎn)),通過簡(jiǎn)單的歸納總結(jié),我們不難發(fā)現(xiàn)其實(shí)崗位要求有很大的重疊部分:
學(xué)歷要求:碩士以上學(xué)歷,博士?jī)?yōu)先。統(tǒng)計(jì)學(xué)、計(jì)算機(jī)科學(xué)、數(shù)學(xué)等相關(guān)專業(yè)。
工作經(jīng)歷: 3年以上相關(guān)工作經(jīng)驗(yàn)。
專業(yè)技能: 熟練掌握HiveSQLhadoop,熟悉大規(guī)模數(shù)據(jù)挖掘、機(jī)器學(xué)習(xí)、自然語(yǔ)言處理(NLP)
分析語(yǔ)言: R, Python, SAS, JAVA
額外要求: 對(duì)數(shù)據(jù)敏感,具備良好的邏輯思維能力、溝通技巧、組織溝通能力、團(tuán)隊(duì)精神以及優(yōu)秀的問題解決能力
有趣的是,這個(gè)廣告適用于來大部分的數(shù)據(jù)科學(xué)家招聘,甚至不分行業(yè)不分地域。可能唯一的不同是,金融領(lǐng)域更強(qiáng)調(diào)擅長(zhǎng)反欺詐和風(fēng)控,而電商領(lǐng)域強(qiáng)調(diào)熟悉推薦系統(tǒng),側(cè)重點(diǎn)不同而已。其實(shí)這個(gè)現(xiàn)象的本質(zhì)就是:數(shù)據(jù)科學(xué)家是一個(gè)不限行業(yè),擁有廣泛就業(yè)需求,高度"相似"卻又"不同"的職位。因此結(jié)合我自己的經(jīng)驗(yàn),以及與國(guó)內(nèi)國(guó)外這一行同事/朋友的交流心得,我想來談?wù)勎覍?duì)數(shù)據(jù)科學(xué)家這個(gè)崗位的理解。
在個(gè)人理解的前提下,我想談?wù)劊?. 數(shù)據(jù)科學(xué)家為什么是“科學(xué)家”?2. 數(shù)據(jù)科學(xué)家的工作內(nèi)容有什么? 3. 一些對(duì)于數(shù)據(jù)分析的感悟 4. 如何成為一個(gè)合格的數(shù)據(jù)科學(xué)家?
1. 什么是數(shù)據(jù)科學(xué)家?“科學(xué)家”是否言過其實(shí)?
數(shù)據(jù)科學(xué)家成為了一個(gè)跨學(xué)科職位。我將數(shù)據(jù)科學(xué)家定義為: 能夠獨(dú)立處理數(shù)據(jù),進(jìn)行復(fù)雜建模,從中攫取商業(yè)價(jià)值,并擁有良好溝通匯報(bào)能力的人。
關(guān)于數(shù)據(jù)科學(xué)家這個(gè)崗位怎么來的,說法不一。我自己的理解是隨著機(jī)器學(xué)習(xí)和更多預(yù)測(cè)模型的發(fā)展,數(shù)據(jù)分析變得"大有可為"。為了區(qū)分擁有建模能力的高端人才和普通商業(yè)分析師/數(shù)據(jù)分析師(data analyst),數(shù)據(jù)科學(xué)家這個(gè)職位自然就產(chǎn)生了。通過這個(gè)新崗位,行業(yè)可以與時(shí)俱進(jìn)的吸收高端人才。在機(jī)器學(xué)習(xí)沒有大行其道,也沒有大數(shù)據(jù)支撐之前,這個(gè)崗位更貼近統(tǒng)計(jì)科學(xué)家(statistician),和研究科學(xué)家(research scientist)也有一點(diǎn)點(diǎn)相似。
對(duì)于科學(xué)家,我們的一般的定義是在特定領(lǐng)域有深入研究的人,因此潛臺(tái)詞一般是“擁有博士學(xué)位的人”。而數(shù)據(jù)科學(xué)家的基本要求是碩士以上學(xué)歷,甚至有時(shí)候本科學(xué)歷也會(huì)被接受,而且似乎數(shù)據(jù)科學(xué)家的工作并不會(huì)在特定領(lǐng)域有深度。那么數(shù)據(jù)科學(xué)家是否言過其實(shí)了?
我的看法是:不,數(shù)據(jù)科學(xué)家的“廣度"就是其"深度"。從另外一個(gè)角度來看,數(shù)據(jù)科學(xué)家的優(yōu)勢(shì)在于其優(yōu)秀的跨領(lǐng)域技能,既可以抓取數(shù)據(jù),也可以分析,進(jìn)行建模,還能將有用的信息用抓人的眼球提供給決策層。能擁有這樣解決問題能力的人,似乎并不愧對(duì)一聲“科學(xué)家”。
而正因?yàn)閿?shù)據(jù)分析更要求的廣度而不是深度,所有現(xiàn)在只有紐約大學(xué)提供科學(xué)博士,而現(xiàn)在大部分從業(yè)的博士都是統(tǒng)計(jì)學(xué)/計(jì)算機(jī)/數(shù)學(xué)/物理背景。正是這個(gè)原因,這個(gè)行業(yè)對(duì)于數(shù)據(jù)科學(xué)家的要求是碩士及以上,而計(jì)算機(jī)或者統(tǒng)計(jì)的人更適合的原因是其在機(jī)器學(xué)習(xí)/統(tǒng)計(jì)學(xué)習(xí)方面的積累,其他所需技能可以以很低的代價(jià)趕上。相對(duì)應(yīng)的,如果一個(gè)心理學(xué)博士想要從事這一行就會(huì)發(fā)現(xiàn)需要補(bǔ)充的技能太多,而因此不能適應(yīng)這個(gè)崗位。
與研究科學(xué)家(research scientist)相比,數(shù)據(jù)科學(xué)家更像是全能手但在特定領(lǐng)域深度不足。和普通分析師(analyst)相比,數(shù)據(jù)科學(xué)家應(yīng)該有更強(qiáng)的建模和分析能力。在和數(shù)據(jù)工程師相對(duì)比時(shí),數(shù)據(jù)科學(xué)家應(yīng)該具備更強(qiáng)的匯報(bào)和溝通能力。
2. 數(shù)據(jù)科學(xué)家的日常工作內(nèi)容包括什么?
我最近在和朋友閑聊時(shí),驚訝的發(fā)現(xiàn)大家的工作內(nèi)容都很相似。主要包括:
2.1. 分析數(shù)據(jù)和建模
此處的工作特指根據(jù)客戶需求,從數(shù)據(jù)中攫取商業(yè)價(jià)值,而這個(gè)過程中一般都會(huì)涉及統(tǒng)計(jì)模型(statistical learning)和機(jī)器學(xué)習(xí)模型(machine learning)。如果在數(shù)據(jù)沒有處理的情況下,我們的工作偶爾也涉及清理數(shù)據(jù)。有時(shí)候我們反而希望數(shù)據(jù)是未經(jīng)過處理的,因?yàn)楹芏嘀匾畔⒍荚诒惶幚碇羞z失了。一般的項(xiàng)目遵循以下幾個(gè)流程:
確定商業(yè)痛點(diǎn) - 明白要解決的問題是什么?
獲得數(shù)據(jù)并進(jìn)行清理,常見的數(shù)據(jù)預(yù)處理包括: a. 缺失值處理 b.特征變量轉(zhuǎn)化 c.特征選擇和維度變化(升維或者降維) d. 標(biāo)準(zhǔn)化/歸一化/稀疏化。涉及文字的時(shí)候可能還要使用一些自然語(yǔ)言處理的手段,更多的相關(guān)方法可以看我最近的回答[1]。
模型選擇與評(píng)估。這個(gè)過程常常是比較粗暴的,往往需要做多個(gè)模型進(jìn)行評(píng)估對(duì)比。
提取商業(yè)價(jià)值,編寫報(bào)告或意見書,并向相關(guān)負(fù)責(zé)人匯報(bào)。
2.2. 與團(tuán)隊(duì)其他成員的溝通
與純粹的機(jī)器科學(xué)工程師不同,數(shù)據(jù)科學(xué)家的重要工作內(nèi)容是交流溝通。如果無法了解清楚客戶的需求是什么,可能白忙活一場(chǎng)。如果無法了解數(shù)據(jù)工程師在采集數(shù)據(jù)時(shí)的手段,我們使用的原始數(shù)據(jù)可能有統(tǒng)計(jì)學(xué)偏見。如果不能講清楚如何才能有效的評(píng)估模型,負(fù)責(zé)在云端運(yùn)行模型的工程師可能給出錯(cuò)誤的答案。因此,數(shù)據(jù)科學(xué)家除了建模必須親手來做以外,其他的環(huán)節(jié)可以“外包”給別人。在數(shù)據(jù)量特別大的時(shí)候,這個(gè)需求變得更為明顯。
2.3. 開會(huì)/匯報(bào)/寫報(bào)告
良好的溝通能力不僅僅是指和團(tuán)隊(duì)成員的溝通,向老板和客戶的匯報(bào)也很考察數(shù)據(jù)科學(xué)家的能力。作為一個(gè)數(shù)據(jù)科學(xué)家,我們一般有幾個(gè)原則:
匯報(bào)時(shí)避免“黑話”,避免給不同背景的老板和客戶造成疑惑。
直擊重點(diǎn)而不炫技。盡量簡(jiǎn)明扼要,不要過分介紹模型的內(nèi)部構(gòu)造,重心是得到的結(jié)論。
實(shí)事求是不夸大模型能力。很多機(jī)器學(xué)習(xí)模型其實(shí)都已經(jīng)不同程度過擬合,不刻意避開交叉驗(yàn)證而選擇“看似表現(xiàn)良好的”過擬合模型。
給出可以進(jìn)一步優(yōu)化和提高的方向,為項(xiàng)目提出新的方向。
在匯報(bào)時(shí)盡量用可視化來代替枯燥的文字。
以我去年做的一個(gè)項(xiàng)目為例:
我們公司的領(lǐng)導(dǎo)層希望了解為什么我們的員工離職率很高,如何才可以避免這一點(diǎn)。遵循我上面介紹的流程:
從人事部門收集數(shù)據(jù),清楚的告訴他們我需要的數(shù)據(jù)時(shí)間跨度,變量。并和法務(wù)部門一起將數(shù)據(jù)中的隱私部分去除。
進(jìn)行數(shù)據(jù)預(yù)處理,建模并評(píng)估。
從中挖掘商業(yè)價(jià)值,如 a. 為什么員工會(huì)離職(將變量重要性進(jìn)行排序,用決策樹可視化分類結(jié)果) b. 什么樣的員工值得留住?
制作報(bào)告,并像領(lǐng)導(dǎo)層匯報(bào)我的發(fā)現(xiàn),過程設(shè)計(jì)可視化等。
和其他部門的同事將這個(gè)項(xiàng)目包裝成一個(gè)案例,賣給我們的其他客戶。
這個(gè)基本包括了數(shù)據(jù)分析項(xiàng)目的基本流程,對(duì)于這個(gè)項(xiàng)目的一些有趣發(fā)現(xiàn)可以看我的另一個(gè)回答[2]。但不難看出,整個(gè)流程中有大量的溝通過程,甚至還包括銷售的部分,這在一次體現(xiàn)了數(shù)據(jù)科學(xué)家的工作廣度。
3. 對(duì)于數(shù)據(jù)科學(xué)家的一些感悟
3.1. 不要沉迷于自己的“職位”
數(shù)據(jù)科學(xué)家是個(gè)聽起來非常“性感的”的崗位,別忘了我們小時(shí)候的夢(mèng)想都是成為一個(gè)科學(xué)家。但拋開這些虛的東西,我們必須認(rèn)清這個(gè)崗位的核心就是將很多技能封裝到一個(gè)人身上。而我們工作的正常開展少不了其他同事的支持和幫助,所以千萬不要看不起別人的工作內(nèi)容。沒有數(shù)據(jù)工程師進(jìn)行數(shù)據(jù)采集,沒有分析師幫我們美化圖表和提出質(zhì)疑,我們無法得到最好的結(jié)果。
數(shù)據(jù)分析項(xiàng)目一直都是眾人拾柴火焰高,沒有人可以當(dāng)超人。所以在得到這樣“高薪性感”的職位后,我們更應(yīng)該把心裝回肚子里,腳踏實(shí)地。
3.2. 不要盲目迷信算法
承接上一點(diǎn),雖然我們的工作重點(diǎn)之一是建模,但請(qǐng)不要神話算法,也不要挾算法以令同事,覺得只有自己做的部分才有價(jià)值。
簡(jiǎn)單來說,可以通過沒有免費(fèi)的午餐定理(No Free Lunch Theorem -> NFL Theorem)來解釋。NFL由Wolpert在1996年提出,其應(yīng)用領(lǐng)域原本為經(jīng)濟(jì)學(xué)。和那句家喻戶曉的"天下沒有免費(fèi)的午餐"有所不同, NFL講的是優(yōu)化模型的評(píng)估問題。
在機(jī)器學(xué)習(xí)領(lǐng)域,NFL告訴機(jī)器學(xué)習(xí)從業(yè)者:"假設(shè)所有數(shù)據(jù)的分布可能性相等,當(dāng)我們用任一分類做法來預(yù)測(cè)未觀測(cè)到的新數(shù)據(jù)時(shí),對(duì)于誤分的預(yù)期是相同的。" 簡(jiǎn)而言之,NFL的定律指明,如果我們對(duì)要解決的問題一無所知且并假設(shè)其分布完全隨機(jī)且平等,那么任何算法的預(yù)期性能都是相似的。這個(gè)定理對(duì)于“盲目的算法崇拜”有毀滅性的打擊。例如,現(xiàn)在很多人沉迷“深度學(xué)習(xí)”不可自拔,那是不是深度學(xué)習(xí)就比其他任何算法都要好?在任何時(shí)候表現(xiàn)都更好呢?未必,我們必須要加深對(duì)于問題的理解,不能盲目的說某一個(gè)算法可以包打天下。
周志華老師在《機(jī)器學(xué)習(xí)》一書中也簡(jiǎn)明扼要的總結(jié):“NFL定理最重要的寓意,是讓我們清楚的認(rèn)識(shí)到,脫離具體問題,空泛的談‘什么學(xué)習(xí)算法更好’毫無意義。”
在這個(gè)深度學(xué)習(xí)就是一切的時(shí)代,作為數(shù)據(jù)科學(xué)家,我們要有自己的獨(dú)立判斷。
3.3. 重視數(shù)據(jù)可視化和模型可解釋度
數(shù)據(jù)科學(xué)家作為一個(gè)更偏商業(yè)應(yīng)用的崗位,而不是研究崗位,需要重視數(shù)據(jù)可視化的重要性以及模型可解釋度的意義。原因很簡(jiǎn)單,如果客戶看不懂我們做的是什么,或者客戶不相信我們做的東西的可靠性,你即使有再酷炫的模型,也只是浪費(fèi)時(shí)間。在大部分中小型的數(shù)據(jù)分析項(xiàng)目中,用深度學(xué)習(xí)的機(jī)會(huì)是很有限的。原因包括但不限于:
數(shù)據(jù)量要求很大
調(diào)參成本太高且奇淫巧技太多
模型可視化即解釋度低
而比較常用的機(jī)器學(xué)習(xí)模型是: 廣義線性模型(generalized linear models),如最普通的邏輯回歸;還有以決策樹為基底的模型,如隨機(jī)森林和Gradient Boosting Tree等。這兩種模型都有很好的可解釋性,而且都可以得到變量重要性系數(shù)。以Sklearn官方文檔中的簡(jiǎn)單的決策樹可視化為例:
我們可以清楚的看到一個(gè)數(shù)據(jù)點(diǎn)如何從上至下被分到了不同的類別當(dāng)中。作為一個(gè)需要和不同背景的人溝通的職業(yè),分類器可視化是一個(gè)很好溝通基礎(chǔ)。
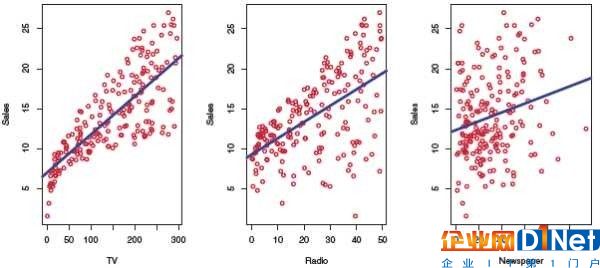
而可視化的好處遠(yuǎn)不止于此,在數(shù)據(jù)建模初期的可視化可以避免我們走很多彎路。以ISL[3]中附帶的線性回歸為例,我們一眼就可以看出最右邊的圖不像左邊的圖中的數(shù)據(jù)可以通過簡(jiǎn)單的線性回歸進(jìn)行擬合,可以直接跳過線性回歸來節(jié)省時(shí)間。
3.4. 避免統(tǒng)計(jì)學(xué)偏見 & 給出嚴(yán)謹(jǐn)?shù)慕Y(jié)論
承接上一點(diǎn),對(duì)于一個(gè)問題我們通常無法得到所有的相關(guān)變量,這導(dǎo)致了大部分?jǐn)?shù)據(jù)分析的結(jié)果其實(shí)或多或少都有偏見。講個(gè)經(jīng)典的統(tǒng)計(jì)學(xué)笑話,夏天溺水身亡的人數(shù)相比冬天大幅度上升,而夏天吃冰激凌的人數(shù)也上升,所以得到結(jié)論: “吃冰激凌”會(huì)導(dǎo)致“溺水”。這種數(shù)據(jù)會(huì)說謊的本質(zhì)就在于我們無法獲得所有的隱變量,如夏天去海邊的人數(shù)上升,游泳的人數(shù)上升等。
而在數(shù)據(jù)分析的項(xiàng)目中,大部分謬誤無法像上面這個(gè)例子一眼就可以看穿,我們常常會(huì)獲得很多看起來很可信但實(shí)則大誤的結(jié)論。作為一個(gè)數(shù)據(jù)科學(xué)家,請(qǐng)?jiān)诜治鰰r(shí)小心在小心,謹(jǐn)慎再謹(jǐn)慎,因?yàn)槲覀兊姆治鼋Y(jié)果往往會(huì)直接影響到公司或者客戶的收益。假設(shè)你做人事分析的項(xiàng)目,錯(cuò)誤的結(jié)論可能導(dǎo)致優(yōu)秀的員工被解雇。
所以萬望大家不要總想搞個(gè)大新聞,對(duì)于沒有足夠顯著性的結(jié)論請(qǐng)?jiān)偃龣z查,不要言過其實(shí)。這是我們的責(zé)任,也是義務(wù)。
4. 如何成為一個(gè)合格的數(shù)據(jù)科學(xué)家?
假設(shè)你已經(jīng)有了基本的從業(yè)資格:即有相關(guān)領(lǐng)域的學(xué)位,掌握了數(shù)據(jù)分析和建模的基礎(chǔ)能力,也懂得至少一門的分析語(yǔ)言(R或Python)和基本的數(shù)據(jù)庫(kù)知識(shí)。下面的這些小建議可以幫助你在這條路上走的更遠(yuǎn)。
4.1. 扎實(shí)的基本功
像我在另一個(gè)機(jī)器學(xué)習(xí)面試回答[4]中提到過的,保證對(duì)基本知識(shí)的了解(有基本的廣度)是對(duì)自己工作的基本尊重。什么程度就算基本了解呢?以數(shù)據(jù)分析為例,我的感受是:
對(duì)基本的數(shù)據(jù)處理方法有所了解
對(duì)基本的分類器模型有所了解并有所使用(調(diào)包),大概知道什么情況使用什么算法較好
對(duì)基本的評(píng)估方法有所掌握,知道常見評(píng)估方法的優(yōu)劣勢(shì)
有基本的編程能力,能夠獨(dú)立的完成簡(jiǎn)單的數(shù)據(jù)分析項(xiàng)目
有基本的數(shù)據(jù)挖掘能力,可以對(duì)模型進(jìn)行調(diào)參并歸納發(fā)現(xiàn)
至于其他軟實(shí)力,暫時(shí)按下不表。
4.2. 從實(shí)踐中培養(yǎng)分析能力
屠龍之技相信大家都有,我常常聽別人說他已經(jīng)刷完了X門在線課,熟讀了X本經(jīng)典書籍,甚至現(xiàn)代、優(yōu)化、概率統(tǒng)計(jì)都又學(xué)了一遍,但為什么Kaggle上還是排名靠后或者工作中缺乏方向?
簡(jiǎn)單來說,上面提到的這些儲(chǔ)備,甚至包括Kaggle經(jīng)驗(yàn),都屬于屠龍之技。數(shù)據(jù)分析領(lǐng)域的陷阱隨處可見,遠(yuǎn)不是幾本書幾篇論文就能講得清楚。最好的方法只有從工作中實(shí)踐,跟著你的師傅學(xué)習(xí)怎么分解項(xiàng)目,怎么提取價(jià)值。
我記憶很深的一個(gè)例子是:有一次我和我的老板為某國(guó)家鑄幣中心制定最優(yōu)的紀(jì)念幣定價(jià)方案,來最大化收益。但根據(jù)客戶給我們的例子,我們的優(yōu)化模型效果很差,誤差極大。我的老板給了我?guī)讉€(gè)建議:1. 把回歸問題轉(zhuǎn)為分類問題,犧牲一部分精度 2. 舍棄掉一部分密度很低的數(shù)據(jù),對(duì)于高密度區(qū)域根據(jù)密度重建模型 3. 如果不行,對(duì)于高密度區(qū)域用有限混合模型(Finite Mixture Model)再做一次。采納了老板的建議,最終我們對(duì)于百分之75%的紀(jì)念幣做到了最佳的優(yōu)化結(jié)果,為客戶帶來了價(jià)值。客戶對(duì)于剩下25%無法預(yù)測(cè)表示理解,因?yàn)樗麄儫o法提供更多的市場(chǎng)數(shù)據(jù)。
那個(gè)時(shí)候的我總覺得不能舍棄數(shù)據(jù),但我的老板用行動(dòng)告訴我客戶最需要的是獲得價(jià)值,而不是完美的模型。而這種感悟,我們只有在實(shí)際工作中才能獲得。所以當(dāng)你作為數(shù)據(jù)科學(xué)家開始工作時(shí),請(qǐng)多想想如何產(chǎn)生價(jià)值,而不是一味地炫屠龍之技。
4.3. 平衡技術(shù)與溝通能力
數(shù)據(jù)科學(xué)家的重要工作內(nèi)容就是匯報(bào)和寫報(bào)告,因而良好的"講故事"(storytelling)能力非常重要。在學(xué)習(xí)的過程中,請(qǐng)不要把全部的重心放在技術(shù)能力上。技術(shù)能力可以保證你有東西可以說,但講故事這種軟實(shí)力可以保證你的辛苦沒有白費(fèi),你的能力獲得大家的認(rèn)可。同時(shí),這種溝通能力也可以讓你在社交中更加如魚得水,一改理工科給人留下的沉悶的印象。輕溝通,重技術(shù),是一種工程師思維,但這并不適用于數(shù)據(jù)科學(xué)家。
最后想不恰當(dāng)?shù)囊靡痪湮鞣街V語(yǔ):“欲戴王冠,必承其重。”在這個(gè)數(shù)據(jù)為王的時(shí)代里面,成為優(yōu)秀的數(shù)據(jù)科學(xué)家不僅僅代表著高薪,還代表著我們對(duì)于這個(gè)時(shí)代的貢獻(xiàn)與價(jià)值。然而道路阻且長(zhǎng),還有太多太多需要我們學(xué)習(xí)和完善的方向。






據(jù)科學(xué)工作者(Data Scientist) 的日常工作內(nèi)容包括什么?")

 京公網(wǎng)安備 11010502049343號(hào)
京公網(wǎng)安備 11010502049343號(hào)