


鑒于缺乏項目中的實戰經驗沉淀,若有異議望指正。
HBase
HBase 是 Apache hadoop 中的一個子項目,屬于 bigtable 的開源版本,所實現的語言為Java(故依賴 Java SDK)。HBase 依托于 Hadoop 的 HDFS(分布式文件系統)作為最基本存儲基礎單元。
HBase在列上實現了 BigTable 論文提到的壓縮算法、內存操作和布隆過濾器。HBase的表能夠作為 MapReduce(https://zh.wikipedia.org/wiki/MapReduce)任務的輸入和輸出,可以通過Java API來訪問數據,也可以通過REST、Avro或者Thrift的API來訪問。
1. 特點
1.1 數據格式
HBash 的數據存儲是基于列(ColumnFamily)的,且非常松散—— 不同于傳統的關系型數據庫(RDBMS),HBase 允許表下某行某列值為空時不做任何存儲(也不占位),減少了空間占用也提高了讀性能。
不過鑒于其它NoSql數據庫也具有同樣靈活的數據存儲結構,該優勢在本次選型中并不出彩。
我們以一個簡單的例子來了解使用 RDBMS 和 HBase 各自的解決方式:
1)RDBMS方案:
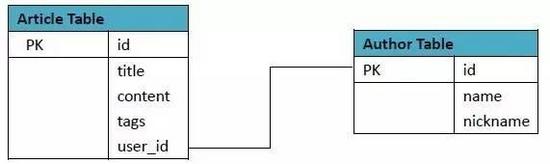
其中Article表格式:
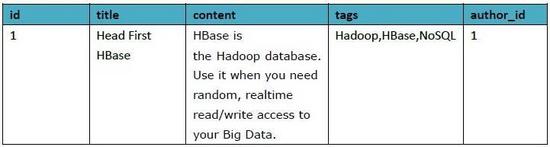
Author表格式:

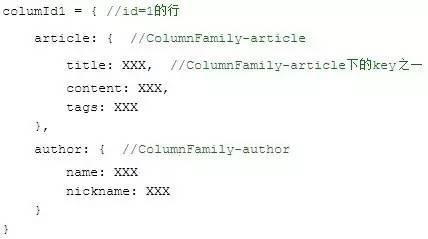
2)等價的HBase方案:

對于前端而言,這里的 Column Keys 和 Column Family 可以看為這樣的關系:
1.2 性能
HStore存儲是HBase存儲的核心,它由兩部分組成,一部分是MemStore,一部分是StoreFiles。
MemStore 是 Sorted Memory Buffer,用戶寫入的數據首先會放入MemStore,當MemStore滿了以后會Flush成一個StoreFile(底層實現是HFile),當StoreFile文件數量增長到一定閾值,會觸發Compact合并操作,將多個StoreFiles合并成一個StoreFile,合并過程中會進行版本合并和數據刪除,因此可以看出HBase其實只有增加數據,所有的更新和刪除操作都是在后續的compact過程中進行的,這使得用戶的寫操作只要進入內存中就可以立即返回,保證了HBase I/O的高性能。
1.3 數據版本
Hbase 還能直接檢索到往昔版本的數據,這意味著我們更新數據時,舊數據并沒有即時被清除,而是保留著:
Hbase 中通過 row+columns 所指定的一個存貯單元稱為cell。每個 cell都保存著同一份數據的多個版本——版本通過時間戳來索引。
時間戳的類型是 64位整型。時間戳可以由Hbase(在數據寫入時自動 )賦值,此時時間戳是精確到毫秒的當前系統時間。時間戳也可以由客戶顯式賦值。如果應用程序要避免數據版本沖突,就必須自己生成具有唯一性的時間戳。每個 cell中,不同版本的數據按照時間倒序排序,即最新的數據排在最前面。
為了避免數據存在過多版本造成的的管理 (包括存貯和索引)負擔,Hbase提供了兩種數據版本回收方式。一是保存數據的最后n個版本,二是保存最近一段時間內的版本(比如最近七天)。用戶可以針對每個列族進行設置。
1.4 CAP類別
2. Node下的使用
HBase的相關操作可參考下表:
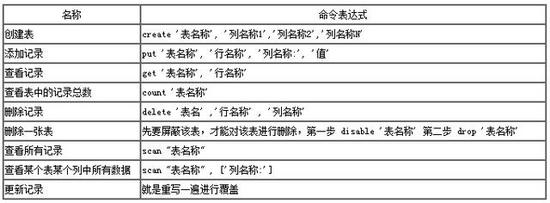
在node環境下,可通過 node-hbase(https://github.com/wdavidw/node-hbase)來實現相關訪問和操作,注意該工具包依賴于 PHYTHON2.X(3.X不支持)和Coffee。
如果是在 window 系統下還需依賴 .NET framwork2.0,64位系統可能無法直接通過安裝包安裝。
官方示例:
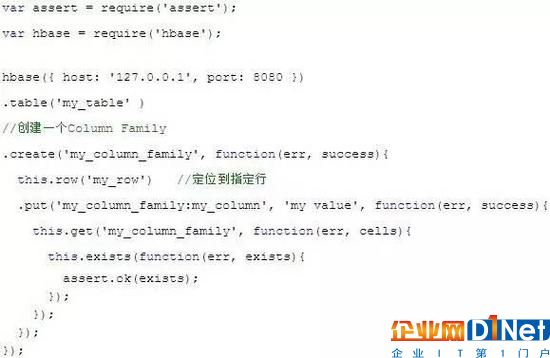
數據檢索:

另有 hbase-client(https://github.com/alibaba/node-hbase-client)也是一個不錯的選擇,具體API參照其文檔。
3. 優缺點
優點:
存儲容量大,一個表可以容納上億行,上百萬列;
可通過版本進行檢索,能搜到所需的歷史版本數據;
負載高時,可通過簡單的添加機器來實現水平切分擴展,跟Hadoop的無縫集成保障了其數據可靠性(HDFS)和海量數據分析的高性能(MapReduce);
在第3點的基礎上可有效避免單點故障的發生。
缺點:
基于Java語言實現及Hadoop架構意味著其API更適用于Java項目;
node開發環境下所需依賴項較多、配置麻煩(或不知如何配置,如持久化配置),缺乏文檔;
占用內存很大,且鑒于建立在為批量分析而優化的HDFS上,導致讀取性能不高;
API相比其它 NoSQL 的相對笨拙。
適用場景:
bigtable類型的數據存儲;
對數據有版本查詢需求;
應對超大數據量要求擴展簡單的需求。
Redis
Redis 是一個開源的使用ANSI C語言編寫、支持網絡、可基于內存亦可持久化的日志型、Key-Value數據庫,并提供多種語言的API。目前由VMware主持開發工作。
Redis 通常被稱為數據結構服務器,因為值(value)可以是 字符串(String), 哈希(Hash/Map), 列表(list), 集合(sets) 和 有序集合(sorted sets)五種類型,操作非常方便。比如,如果你在做好友系統,查看自己的好友關系,如果采用其他的key-value系統,則必須把對應的好友拼接成字符串,然后在提取好友時,再把value進行解析,而redis則相對簡單,直接支持list的存儲(采用雙向鏈表或者壓縮鏈表的存儲方式)。
我們來看下這五種數據類型。
1)String
string 是 Redis 最基本的類型,你可以理解成與 Memcached 一模一樣的類型,一個key對應一個value。
string 類型是二進制安全的。意思是 Redis 的 string 可以包含任何數據。比如 jpg 圖片或者序列化的對象 。
string 類型是 Redis 最基本的數據類型,一個鍵最大能存儲512MB。
實例:

在以上實例中我們使用了 Redis 的 SET 和 GET 命令。鍵為 name,對應的值為"zfpx"。 注意:一個鍵最大能存儲512MB。
2)Hash
Redis hash 是一個鍵值對集合。
Redis hash 是一個 string 類型的 field 和 value 的映射表,hash 特別適合用于存儲對象。
實例:

以上實例中 hash 數據類型存儲了包含用戶腳本信息的用戶對象。 實例中我們使用了 Redis HMSET, HGETALL 命令,user:1 為鍵值。 每個 hash 可以存儲 232- 1 鍵值對(40多億)。
3)List
Redis 列表是簡單的字符串列表,按照插入順序排序。你可以添加一個元素導列表的頭部(左邊)或者尾部(右邊)。
實例:
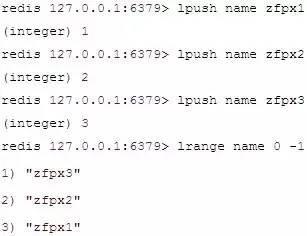
列表最多可存儲 232- 1 元素 (4294967295, 每個列表可存儲40多億)。
4)Sets
Redis的Set是string類型的無序集合。 集合是通過哈希表實現的,所以添加,刪除,查找的復雜度都是O(1)。
添加一個string元素到 key 對應的 set 集合中,成功返回1,如果元素已經在集合中返回0,key對應的set不存在返回錯誤,指令格式為
實例:
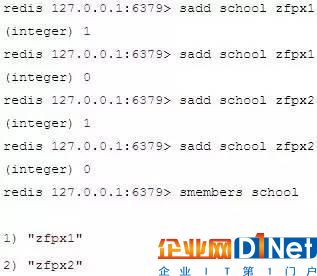
注意:以上實例中 zfpx1 添加了兩次,但根據集合內元素的唯一性,第二次插入的元素將被忽略。 集合中最大的成員數為 232- 1 (4294967295, 每個集合可存儲40多億個成員)。
5)sorted sets/zset
Redis zset 和 set 一樣也是string類型元素的集合,且不允許重復的成員。不同的是每個元素都會關聯一個double類型的分數。redis正是通過分數來為集合中的成員進行從小到大的排序。
zset的成員是唯一的,但分數(score)卻可以重復。可以通過 zadd 命令(格式如下) 添加元素到集合,若元素在集合中存在則更新對應score
實例:
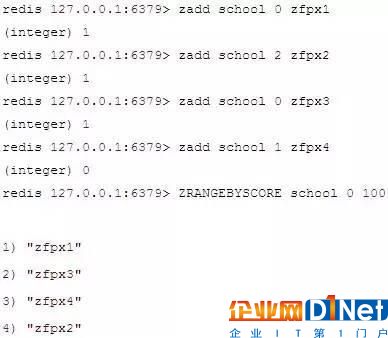
1.2 性能
Redis數據庫完全在內存中,因此處理速度非常快,每秒能執行約11萬集合,每秒約81000+條記錄(測試數據的可參考這篇《Redis千萬級的數據量的性能測試》www.cnblogs.com/lovecindywang/archive/2011/03/03/1969633.html)。
Redis的數據能確保一致性——所有Redis操作是原子性(Atomicity,意味著操作的不可再分,要么執行要么不執行)的,這保證了如果兩個客戶端同時訪問的Redis服務器將獲得更新后的值。
1.3 持久化
通過定時快照(snapshot)和基于語句的追加(AppendOnlyFile,aof)兩種方式,redis可以支持數據持久化——將內存中的數據存儲到磁盤上,方便在宕機等突發情況下快速恢復。
1.4 CAP類別
屬于CP類型(了解更多:www.quora.com/What-is-Redis-in-the-context-of-the-CAP-Theorem)。
2. Node下的使用
node 下可使用 node_redis(https://github.com/NodeRedis/node_redis)來實現 redis 客戶端操作:

非常豐富的數據結構;
Redis提供了事務的功能,可以保證一串 命令的原子性,中間不會被任何操作打斷;
數據存在內存中,讀寫非常的高速,可以達到10w/s的頻率。
缺點:
Redis3.0后才出來官方的集群方案,但仍存在一些架構上的問題(http://sunxiang0918.cn/2015/10/03/Redis%E9%9B%86%E7%BE%A4%E9%83%A8%E7%BD%B2/);
持久化功能體驗不佳——通過快照方法實現的話,需要每隔一段時間將整個數據庫的數據寫到磁盤上,代價非常高;而aof方法只追蹤變化的數據,類似于mysql的binlog方法,但追加log可能過大,同時所有操作均要重新執行一遍,恢復速度慢;
由于是內存數據庫,所以,單臺機器,存儲的數據量,跟機器本身的內存大小。雖然redis本身有key過期策略,但是還是需要提前預估和節約內存。如果內存增長過快,需要定期刪除數據。
適用場景:
適用于數據變化快且數據庫大小可遇見(適合內存容量)的應用程序。更具體的可參照這篇《Redis 的 5 個常見使用場景》譯文(http://blog.jobbole.com/88383/)。
MongoDB
MongoDB 是一個高性能,開源,無模式的文檔型數據庫,開發語言是C++。它在許多場景下可用于替代傳統的關系型數據庫或鍵/值存儲方式。
在 MongoDB 中,文檔是對數據的抽象,它的表現形式就是我們常說的 BSON(Binary JSON )。
BSON 是一個輕量級的二進制數據格式。MongoDB 能夠使用 BSON,并將 BSON 作為數據的存儲存放在磁盤中。
BSON 是為效率而設計的,它只需要使用很少的空間,同時其編碼和解碼都是非常快速的。即使在最壞的情況下,BSON格式也比JSON格式再最好的情況下存儲效率高。
對于前端開發者來說,一個“文檔”就相當于一個對象:
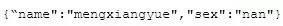
對于文檔是有一些限制的:有序、區分大小寫的,所以下面的兩個文檔是與上面不同的:

另外,對于文檔的字段 MongoDB 有如下的限制:
_id必須存在,如果你插入的文檔中沒有該字段,那么 MongoDB 會為該文檔創建一個ObjectId作為其值。_id的值必須在本集合中是唯一的。
多個文檔則組合為一個“集合”。在 MongoDB 中的集合是無模式的,也就是說集合中存儲的文檔的結構可以是不同的,比如下面的兩個文檔可以同時存入到一個集合中:
1.2 性能
MongoDB 目前支持的存儲引擎為內存映射引擎。當 MongoDB 啟動的時候,會將所有的數據文件映射到內存中,然后操作系統會托管所有的磁盤操作。這種存儲引擎有以下幾種特點:
MongoDB 中關于內存管理的代碼非常精簡,畢竟相關的工作已經有操作系統進行托管。
MongoDB 服務器使用的虛擬內存將非常巨大,并將超過整個數據文件的大小。不用擔心,操作系統會去處理這一切。
在《Mongodb億級數據量的性能測試》(www.cnblogs.com/lovecindywang/archive/2011/03/02/1969324.html)一文中,MongoDB 展現了強勁的大數據處理性能(數據甚至比Redis的漂亮的多)。
另外,MongoDB 提供了全索引支持(www.cnblogs.com/yangecnu/archive/2011/07/19/2110989.html):包括文檔內嵌對象及數組。Mongo的查詢優化器會分析查詢表達式,并生成一個高效的查詢計劃。通常能夠極大的提高查詢的效率。
1.3 持久化
MongoDB 在1.8版本之后開始支持 journal,就是我們常說的 redo log,用于故障恢復和持久化。
當系統啟動時,MongoDB 會將數據文件映射到一塊內存區域,稱之為Shared view,在不開啟 journal 的系統中,數據直接寫入shared view,然后返回,系統每60s刷新這塊內存到磁盤,這樣,如果斷電或down機,就會丟失很多內存中未持久化的數據。
當系統開啟了 journal 功能,系統會再映射一塊內存區域供 journal 使用,稱之為 private view,MongoDB 默認每100ms刷新 privateView 到 journal,也就是說,斷電或宕機,有可能丟失這100ms數據,一般都是可以忍受的,如果不能忍受,那就用程序寫log吧(但開啟journal后使用的虛擬內存是之前的兩倍)。
1.4 CAP類別
MongoDB 比較靈活,可以設置成 strong consistent (CP類型)或者 eventual consistent(AP類型)。
2. Node下的使用
MongoDB 在 node 環境下的驅動引擎是 node-mongodb-native(http://github.com/mongodb/node-mongodb-native),作為依賴封裝到 mongodb 包里,我們直接安裝即可:
實例:

另外我們也可以使用MongoDB的ODM(面向對象數據庫管理器) —— mongoose(http://mongoosejs.com/docs/index.html)來做數據庫管理,具體參照其API文檔。
強大的自動化 shading 功能(了解更多:http://xiezhenye.com/2012/12/mongodb-sharding-%E6%9C%BA%E5%88%B6%E5%88%86%E6%9E%90.html);
全索引支持,查詢非常高效;
面向文檔(BSON)存儲,數據模式簡單而強大;
支持動態查詢,查詢指令也使用JSON形式的標記,可輕易查詢文檔中內嵌的對象及數組;
支持 javascript 表達式查詢,可在服務器端執行任意的 javascript函數。
缺點:
單個文檔大小限制為16M,32位系統上,不支持大于2.5G的數據;
對內存要求比較大,至少要保證熱數據(索引,數據及系統其它開銷)都能裝進內存;
非事務機制,無法保證事件的原子性。
適用場景:
適用于實時的插入、更新與查詢的需求,并具備應用程序實時數據存儲所需的復制及高度伸縮性;
非常適合文檔化格式的存儲及查詢;
高伸縮性的場景:MongoDB 非常適合由數十或者數百臺服務器組成的數據庫;
對性能的關注超過對功能的要求。
Couchbase
本文之所以沒有介紹 CouchDB 或 Membase,是因為它們合并了。合并之后的公司基于 Membase 與 CouchDB 開發了一款新產品,新產品的名字叫做 Couchbase。
Couchbase 可以說是集合眾家之長,目前應該是最先進的Cache系統,其開發語言是 C/C++。
Couchbase Server 是個面向文檔的數據庫(其所用的技術來自于Apache CouchDB項目),能夠實現水平伸縮,并且對于數據的讀寫來說都能提供低延遲的訪問(這要歸功于Membase技術)。
Couchbase 跟 MongoDB 一樣都是面向文檔的數據庫,不過在往 Couchbase 插入數據前,需要先建立 bucket —— 可以把它理解為“庫”或“表”。
因為 Couchbase 數據基于 Bucket 而導致缺乏表結構的邏輯,故如果需要查詢數據,得先建立 view(跟RDBMS的視圖不同,view是將數據轉換為特定格式結構的數據形式如JSON)來執行。
Bucket的意義 —— 在于將數據進行分隔,比如:任何 view 就是基于一個 Bucket 的,僅對 Bucket 內的數據進行處理。一個server上可以有多個Bucket,每個Bucket的存儲類型、內容占用、數據復制數量等,都需要分別指定。從這個意義上看,每個Bucket都相當于一個獨立的實例。在集群狀態下,我們需要對server進行集群設置,Bucket只側重數據的保管。
每當views建立時, 就會建立indexes, index的更新和以往的數據庫索引更新區別很大。 比如現在有1W數據,更新了200條,索引只需要更新200條,而不需要更新所有數據,map/reduce功能基于index的懶更新行為,大大得益。
要留意的是,對于所有文件,couchbase 都會建立一個額外的 56byte 的 metadata,這個 metadata 功能之一就是表明數據狀態,是否活動在內存中。同時文件的 key 也作為標識符和 metadata 一起長期活動在內存中。
1.2 性能
couchbase 的精髓就在于依賴內存最大化降低硬盤I/O對吞吐量的負面影響,所以其讀寫速度非常快,可以達到亞毫秒級的響應。
couchbase在對數據進行增刪時會先體現在內存中,而不會立刻體現在硬盤上,從內存的修改到硬盤的修改這一步驟是由 couchbase 自動完成,等待執行的硬盤操作會以write queue的形式排隊等待執行,也正是通過這個方法,硬盤的I/O效率在 write queue 滿之前是不會影響 couchbase 的吞吐效率的。
鑒于內存資源肯定遠遠少于硬盤資源,所以如果數據量小,那么全部數據都放在內存上自然是最優選擇,這時候couchbase的效率也是異常高。
但是數據量大的時候過多的數據就會被放在硬盤之中。當然,最終所有數據都會寫入硬盤,不過有些頻繁使用的數據提前放在內存中自然會提高效率。
1.3 持久化
其前身之一 memcached 是完全不支持持久化的,而 Couchbase 添加了對異步持久化的支持:
Couchbase提供兩種核心類型的buckets —— Couchbase 類型和 Memcached 類型。其中 Couchbase 類型提供了高可用和動態重配置的分布式數據存儲,提供持久化存儲和復制服務。
Couchbase bucket 具有持久性 —— 數據單元異步從內存寫往磁盤,防范服務重啟或較小的故障發生時數據丟失。持久性屬性是在 bucket 級設置的。
1.4 CAP類型
Couchbase 群集所有點都是對等的,只是在創建群或者加入集群時需要指定一個主節點,一旦結點成功加入集群,所有的結點對等。
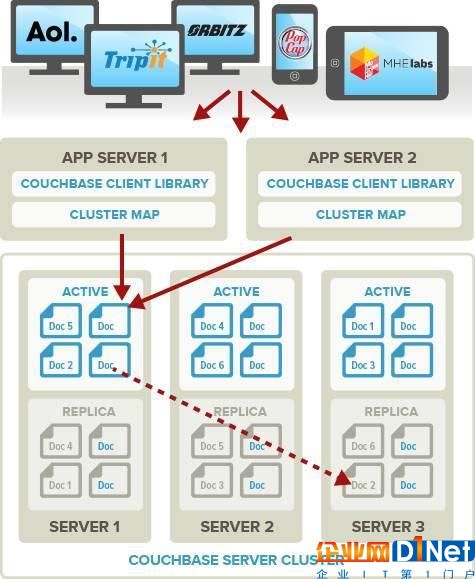
對等網的優點是,集群中的任何節點失效,集群對外提供服務完全不會中斷,只是集群的容量受影響。
由于 couchbase 是對等網集群,所有的節點都可以同時對客戶端提供服務,這就需要有方法把集群的節點信息暴露給客戶端,couchbase 提供了一套機制,客戶端可以獲取所有節點的狀態以及節點的變動,由客戶端根據集群的當前狀態計算 key 所在的位置。
就上述的介紹,Couchbase 明顯屬于 CP 類型。
2. Node下的使用
實例:
高并發性,高靈活性,高拓展性,容錯性好;
以 vBucket 的概念實現更理想化的自動分片以及動態擴容(了解更多:http://jolestar.com/couchbase/);
缺點:
Couchbase 的存儲方式為 Key/Value,但 Value 的類型很為單一,不支持數組。另外也不會自動創建doc id,需要為每一文檔指定一個用于存儲的 Document Indentifer;
各種組件拼接而成,都是c++實現,導致復雜度過高,遇到奇怪的性能問題排查比較困難,(中文)文檔比較欠缺;
采用緩存全部key的策略,需要大量內存。節點宕機時 failover 過程有不可用時間,并且有部分數據丟失的可能,在高負載系統上有假死現象;
逐漸傾向于閉源,社區版本(免費,但不提供官方維護升級)和商業版本之間差距比較大。
適用場景:
適合對讀寫速度要求較高,但服務器負荷和內存花銷可遇見的需求;
需要支持 memcached 協議的需求。
LevelDB
LevelDB 是由谷歌重量級工程師(Jeff Dean 和 Sanjay Ghemawat)開發的開源項目,它是能處理十億級別規模 key-value 型數據持久性存儲的程序庫,開發語言是C++。
除了持久性存儲,LevelDB 還有一個特點是 —— 寫性能遠高于讀性能(當然讀性能也不差)。
1. 特點
LevelDB 作為存儲系統,數據記錄的存儲介質包括內存以及磁盤文件,當LevelDB運行了一段時間,此時我們給LevelDb進行透視拍照,那么您會看到如下一番景象:
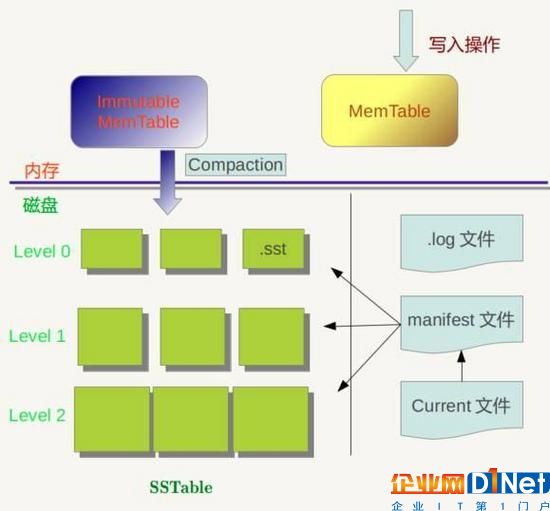
(圖1)
LevelDB 所寫入的數據會先插入到內存的 Mem Table 中,再由 Mem Table 合并到只讀且鍵值有序的 Disk Table(SSTable) 中,再由后臺線程不時的對 Disk Table 進行歸并。
內存中存在兩個 Mem Table —— 一個是可以往里面寫數據的table A,另一個是正在合并到硬盤的 table B。
Mem Table 用 skiplist(http://blog.csdn.net/ict2014/article/details/17394259)實現,寫數據時,先寫日志(.log),再往A插入,因為一次寫入操作只涉及一次磁盤順序寫和一次內存寫入,所以這是為何說LevelDb寫入速度極快的主要原因。如果當B還沒完成合并,而A已經寫滿時,寫操作必須等待。
DiskTable(SSTable,格式為.sst)是分層的(leveldb的名稱起源),每一個大小不超過2M。最先 dump 到硬盤的 SSTable 的層級為0,層級為0的 SSTable 的鍵值范圍可能有重疊。如果這樣的 SSTable 太多,那么每次都需要從多個 SSTable 讀取數據,所以LevelDB 會在適當的時候對 SSTable 進行 Compaction,使得新生成的 SSTable 的鍵值范圍互不重疊。
進行對層級為 level 的 SSTable 做 Compaction 的時候,取出層級為 level+1 的且鍵值空間與之重疊的 Table,以順序掃描的方式進行合并。level 為0的 SSTable 做 Compaction 有些特殊:會取出 level 0 所有重疊的Table與下一層做 Compaction,這樣做保證了對于大于0的層級,每一層里 SSTable 的鍵值空間是互不重疊的。
SSTable 中的某個文件屬于特定層級,而且其存儲的記錄是 key 有序的,那么必然有文件中的最小 key 和最大 key,這是非常重要的信息,LevelDB 應該記下這些信息 —— Manifest 就是干這個的,它記載了 SSTable 各個文件的管理信息,比如屬于哪個Level,文件名稱叫啥,最小 key 和最大 key 各自是多少。下圖是 Manifest 所存儲內容的示意:

圖中只顯示了兩個文件(Manifest 會記載所有 SSTable 文件的這些信息),即 Level0 的 Test1.sst 和 Test2.sst 文件,同時記載了這些文件各自對應的 key 范圍,比如 Test1.sstt 的 key 范圍是“an”到 “banana”,而文件 Test2.sst 的 key 范圍是“baby”到“samecity”,可以看出兩者的 key 范圍是有重疊的。
那么上方圖1中的 Current 文件是干什么的呢?這個文件的內容只有一個信息,就是記載當前的 Manifest 文件名。因為在 LevleDB 的運行過程中,隨著 Compaction 的進行,SSTable 文件會發生變化,會有新的文件產生,老的文件被廢棄,Manifest 也會跟著反映這種變化,此時往往會新生成 Manifest 文件來記載這種變化,而 Current 則用來指出哪個 Manifest 文件才是我們關心的那個 Manifest 文件。
注意,鑒于 LevelDB 不屬于分布式數據庫,故CAP法則在此處不適用。
2. Node下的使用
Node 下可以使用 LevelUP(https://github.com/Level/levelup)來操作 LevelDB 數據庫:

LevelUp 的API非常簡潔實用,具體可參考官方文檔。
操作接口簡單,基本操作包括寫記錄,讀記錄和刪除記錄,也支持針對多條操作的原子批量操作;
寫入性能遠強于讀取性能;
數據量增大后,讀寫性能下降趨平緩。
缺點:
隨機讀性能一般;
對分布式事務的支持還不成熟。而且機器資源浪費率高。
適應場景:
適用于對寫入需求遠大于讀取需求的場景(大部分場景其實都是這樣)。








 京公網安備 11010502049343號
京公網安備 11010502049343號