


首先hadoop實(shí)現(xiàn)了一個(gè)分布式文件系統(tǒng)(HadoopDistributedFileSystem),簡(jiǎn)稱HDFS。HDFS有高容錯(cuò)性的特點(diǎn),并且設(shè)計(jì)用來(lái)部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(highthroughput)來(lái)訪問應(yīng)用程序的數(shù)據(jù),適合那些有著超大數(shù)據(jù)集(largedataset)的應(yīng)用程序。HDFS放寬了(relax)POSIX的要求,可以以流的形式訪問(streamingaccess)文件系統(tǒng)中的數(shù)據(jù)。
Hadoop的框架最核心的設(shè)計(jì)就是:HDFS和MapReduce。HDFS為海量的數(shù)據(jù)提供了存儲(chǔ),則MapReduce為海量的數(shù)據(jù)提供了計(jì)算。一句話來(lái)講Hadoop就是存儲(chǔ)加計(jì)算。
Hadoop這個(gè)名字不是一個(gè)縮寫,而是一個(gè)虛構(gòu)的名字。該項(xiàng)目的創(chuàng)建者,DougCutting解釋Hadoop的得名:“這個(gè)名字是我孩子給一個(gè)棕黃色的大象玩具命名的。
Hadoop是一個(gè)能夠讓用戶輕松架構(gòu)和使用的分布式計(jì)算平臺(tái)。用戶可以輕松地在Hadoop上開發(fā)和運(yùn)行處理海量數(shù)據(jù)的應(yīng)用程序。它主要有以下幾個(gè)優(yōu)點(diǎn):
1、高可靠性Hadoop按位存儲(chǔ)和處理數(shù)據(jù)的能力值得人們信賴。
2、高擴(kuò)展性Hadoop是在可用的計(jì)算機(jī)集簇間分配數(shù)據(jù)并完成計(jì)算任務(wù)的,這些集簇可以方便地?cái)U(kuò)展到數(shù)以千計(jì)的節(jié)點(diǎn)中。
3、高效性Hadoop能夠在節(jié)點(diǎn)之間動(dòng)態(tài)地移動(dòng)數(shù)據(jù),并保證各個(gè)節(jié)點(diǎn)的動(dòng)態(tài)平衡,因此處理速度非常快。
4、高容錯(cuò)性Hadoop能夠自動(dòng)保存數(shù)據(jù)的多個(gè)副本,并且能夠自動(dòng)將失敗的任務(wù)重新分配。
5、低成本與一體機(jī)、商用數(shù)據(jù)倉(cāng)庫(kù)以及QlikView、YonghongZ-Suite等數(shù)據(jù)集市相比,hadoop是開源的,項(xiàng)目的軟件成本因此會(huì)大大降低。
Hadoop帶有用Java語(yǔ)言編寫的框架,因此運(yùn)行在Linux生產(chǎn)平臺(tái)上是非常理想的。Hadoop上的應(yīng)用程序也可以使用其他語(yǔ)言編寫,比如C++。
Hadoop大數(shù)據(jù)處理的意義
Hadoop得以在大數(shù)據(jù)處理應(yīng)用中廣泛應(yīng)用得益于其自身在數(shù)據(jù)提取、變形和加載(ETL)方面上的天然優(yōu)勢(shì)。Hadoop的分布式架構(gòu),將大數(shù)據(jù)處理引擎盡可能的靠近存儲(chǔ),對(duì)例如像ETL這樣的批處理操作相對(duì)合適,因?yàn)轭愃七@樣操作的批處理結(jié)果可以直接走向存儲(chǔ)。Hadoop的MapReduce功能實(shí)現(xiàn)了將單個(gè)任務(wù)打碎,并將碎片任務(wù)(Map)發(fā)送到多個(gè)節(jié)點(diǎn)上,之后再以單個(gè)數(shù)據(jù)集的形式加載(Reduce)到數(shù)據(jù)倉(cāng)庫(kù)里。
Hadoop由以下幾個(gè)項(xiàng)目構(gòu)成
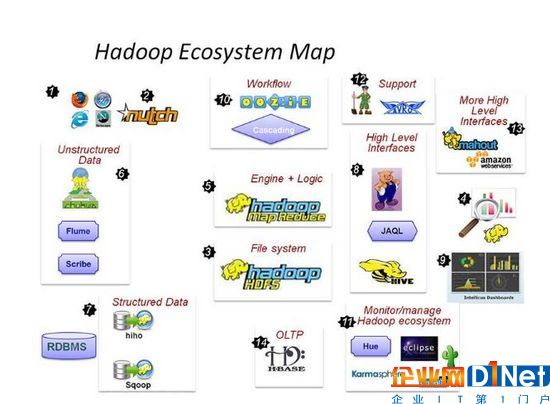
1、HadoopCommon:Hadoop體系最底層的一個(gè)模塊,為Hadoop各子項(xiàng)目提供各種工具,如:配置文件和日志操作等。
2、HDFS:分布式文件系統(tǒng),提供高吞吐量的應(yīng)用程序數(shù)據(jù)訪問,對(duì)外部客戶機(jī)而言,HDFS就像一個(gè)傳統(tǒng)的分級(jí)文件系統(tǒng)。可以創(chuàng)建、刪除、移動(dòng)或重命名文件,等等。但是HDFS的架構(gòu)是基于一組特定的節(jié)點(diǎn)構(gòu)建的(參見圖1),這是由它自身的特點(diǎn)決定的。這些節(jié)點(diǎn)包括NameNode(僅一個(gè)),它在HDFS內(nèi)部提供元數(shù)據(jù)服務(wù);DataNode,它為HDFS提供存儲(chǔ)塊。由于僅存在一個(gè)NameNode,因此這是HDFS的一個(gè)缺點(diǎn)(單點(diǎn)失敗)。
存儲(chǔ)在HDFS中的文件被分成塊,然后將這些塊復(fù)制到多個(gè)計(jì)算機(jī)中(DataNode)。這與傳統(tǒng)的RAID架構(gòu)大不相同。塊的大小(通常為64MB)和復(fù)制的塊數(shù)量在創(chuàng)建文件時(shí)由客戶機(jī)決定。NameNode可以控制所有文件操作。HDFS內(nèi)部的所有通信都基于標(biāo)準(zhǔn)的TCP/IP協(xié)議。
3、MapReduce:一個(gè)分布式海量數(shù)據(jù)處理的軟件框架集計(jì)算集群。
4、Avro:dougcutting主持的RPC項(xiàng)目,主要負(fù)責(zé)數(shù)據(jù)的序列化。有點(diǎn)類似Google的protobuf和Facebook的thrift。avro用來(lái)做以后hadoop的RPC,使hadoop的RPC模塊通信速度更快、數(shù)據(jù)結(jié)構(gòu)更緊湊。
5、Hive:類似CloudBase,也是基于hadoop分布式計(jì)算平臺(tái)上的提供datawarehouse的sql功能的一套軟件。使得存儲(chǔ)在hadoop里面的海量數(shù)據(jù)的匯總,即席查詢簡(jiǎn)單化。hive提供了一套QL的查詢語(yǔ)言,以sql為基礎(chǔ),使用起來(lái)很方便。
6、HBase:基于HadoopDistributedFileSystem,是一個(gè)開源的,基于列存儲(chǔ)模型的可擴(kuò)展的分布式數(shù)據(jù)庫(kù),支持大型表的存儲(chǔ)結(jié)構(gòu)化數(shù)據(jù)。
7、Pig:是一個(gè)并行計(jì)算的高級(jí)的數(shù)據(jù)流語(yǔ)言和執(zhí)行框架,SQL-like語(yǔ)言,是在MapReduce上構(gòu)建的一種高級(jí)查詢語(yǔ)言,把一些運(yùn)算編譯進(jìn)MapReduce模型的Map和Reduce中,并且用戶可以定義自己的功能。
8、ZooKeeper:Google的Chubby一個(gè)開源的實(shí)現(xiàn)。它是一個(gè)針對(duì)大型分布式系統(tǒng)的可靠協(xié)調(diào)系統(tǒng),提供的功能包括:配置維護(hù)、名字服務(wù)、分布式同步、組服務(wù)等。ZooKeeper的目標(biāo)就是封裝好復(fù)雜易出錯(cuò)的關(guān)鍵服務(wù),將簡(jiǎn)單易用的接口和性能高效、功能穩(wěn)定的系統(tǒng)提供給用戶。
9、Chukwa:一個(gè)管理大型分布式系統(tǒng)的數(shù)據(jù)采集系統(tǒng)由yahoo貢獻(xiàn)。
10、Cassandra:無(wú)單點(diǎn)故障的可擴(kuò)展的多主數(shù)據(jù)庫(kù)。
11、Mahout:一個(gè)可擴(kuò)展的機(jī)器學(xué)習(xí)和數(shù)據(jù)挖掘庫(kù)。
Hadoop設(shè)計(jì)之初的目標(biāo)就定位于高可靠性、高可拓展性、高容錯(cuò)性和高效性,正是這些設(shè)計(jì)上與生俱來(lái)的優(yōu)點(diǎn),才使得Hadoop一出現(xiàn)就受到眾多大公司的青睞,同時(shí)也引起了研究界的普遍關(guān)注。到目前為止,Hadoop技術(shù)在互聯(lián)網(wǎng)領(lǐng)域已經(jīng)得到了廣泛的運(yùn)用,如Yahoo、Facebook、Adobe、IBM、百度、阿里巴巴、騰訊、華為、中國(guó)移動(dòng)等。
關(guān)于怎樣學(xué)習(xí)hadoop,首先要了解并且深刻認(rèn)識(shí)什么是hadoop,它的原理以及作用是什么,包括基本構(gòu)成是什么,分別有什么作用,當(dāng)然,在學(xué)習(xí)之前,至少要掌握一門基礎(chǔ)語(yǔ)言,這樣在學(xué)習(xí)起來(lái)才會(huì)事半功倍,因?yàn)槟壳癶adoop在國(guó)內(nèi)發(fā)展時(shí)間不長(zhǎng),有興趣的朋友不妨在大講臺(tái)hadoop培訓(xùn)課程先試學(xué)下,另大講臺(tái)IT職業(yè)在線學(xué)習(xí)教育平臺(tái)為您提供權(quán)威的大數(shù)據(jù)培訓(xùn)視頻教程系統(tǒng),通過大講臺(tái)金牌講師在線錄制的第一套自適應(yīng)Hadoop在線視頻課程系統(tǒng),讓你快速掌握Hadoop從入門到精通大數(shù)據(jù)開發(fā)實(shí)戰(zhàn)技能。






淺談什么是Hadoop及如何學(xué)習(xí)Hadoop")

 京公網(wǎng)安備 11010502049343號(hào)
京公網(wǎng)安備 11010502049343號(hào)