










摘要:Q1.下面哪個步驟/假設,影響回歸建模中欠擬合(under-fitting)和過度擬合(over-fitting)之間的平衡。
Q1.下面哪個步驟/假設,影響回歸建模中欠擬合(under-fitting)和過度擬合(over-fitting)之間的平衡。
A.多項式的次數
B.計算權重的方式是矩陣求逆還是梯度下降法
C.常數項的使用
答案:A
選擇合適的多項式次數在回歸的擬合中起關鍵作用。如果我們選擇更高次數的多項式,會顯著增加過度擬合的可能。
Q2.假設你有以下數據,一組輸入變量和一組輸出變量。請問如果使用線性方程,留一法交叉驗證的均方誤差是?
A.10/27
B.20/27
C.50/27
D.49/27
答案:D
我們需要計算每個交叉驗證點的殘差。使用兩個點計算擬合線,留一個點來做交叉驗證。
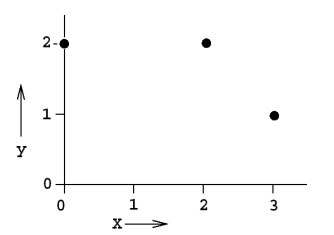
留一法交叉驗證的均方誤差= (2^2 +(2/3)^2 +1^2) /3 = 49/27
Q3.關于最大似然估計(Maximum Likelihood estimate ,MLE)下面說法正確的有?
1.不一定存在最大似然估計值
2.一定存在最大似然估計值
3.如果存在最大似然估計值 ,可能不是唯一解
4.如果存在最大似然估計值 ,一定是唯一解
A.1 和 4
B.2 和 3
C.1 和3
D.2和 4
答案:C
最大似然值可能不是一個轉折點,如函數(或對數似然函數)的一階導數消失了
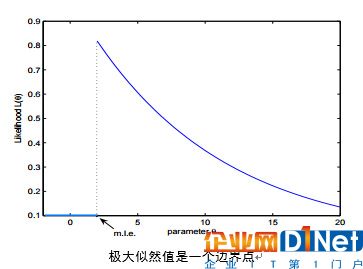
最大似然值可能不唯一
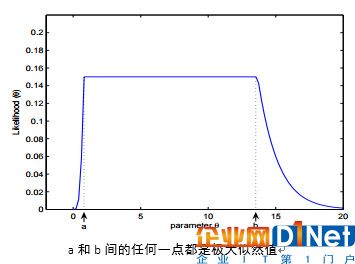
Q4.假設,一個“線性回歸”模型能完美的符合訓練數據(train error)(訓練誤差是0)。則下列哪個陳述是正確的?
A.你的測試誤差(test error)總是0
B.你不會再有測試誤差為0
C.以上都不對
答:C
如果測試數據里沒有噪聲,測試誤差可能是零。換句話說,如果測試數據完美的代表了訓練數據,測試誤差可能是0,但并非總是如此。
Q5.在一個線性回歸問題中,我們使用”R^2″來衡量擬合優度。如果我們在線性回歸模型中增加了一個特征后再訓練同一個模型,以下說法正確的是?
A.如果R^2 增加,則這個變量顯著影響
B.如果R^2 減少,則這個變量不顯著
C.只有R^2 不能說明變量的重要性,還不能做出判斷
D.以上都不對
答:C
只有R^2 不能說明一個變量是否顯著,因為每次我們增加一個特征時,可決系數可能增加或者保持不變。但是,如果是調整R^2則不一樣(如果特征是顯著的,調整R^2增加)
Q6. 有關回歸分析里的殘差,以下哪個陳述是正確的?
A.殘差的均值總是0
B.殘差的均值總是小于0
C.殘差的均值總是大于0
D.殘差沒有這樣的規則
答:A
回歸里殘差和總是0。殘差的總和是0,那均值也肯定是0.
Q7.下面關于異方差性(Heteroskedasticity)正確的是?
A.不同誤差的線性回歸
B.恒定誤差的線性回歸
C.0誤差的線性回歸
D.以上都不對
答:A
誤差的不恒定產生了異方差性。一般來說,因為異常值或者極具影響的值,產生了不恒定的方差。
你可以參考這篇文章了解更多有關回歸分析的更多細節。
Q8.下面哪一項說明X和Y存在非常強的關系?
A.相關系數( Correlation coefficient)=0.9
B.零假設(β=0)的p值為0.0001
C.零假設(β=0)的t統計量為30
D.以上都不對
答:A
變量間的相關系數=0.9,說明變量間的關系是非常強的。而另一方面,p值和t統計量僅僅衡量了存在關系的顯著性。如果有足夠的數據,即使弱關系也會有顯著性。
Q9.推導線性回歸參數時,我們基于以下哪些假設。
1.因變量y和自變量x的之間的關系是線性的
2.模型誤差是獨立的
3.誤差分布的均值為0,標準差為一個常數
4.自變量x是非隨機的,測量是無誤差的
A.1,2,3
B.1,3,4
C.1,3
D.以上所有
答案:D
推導線性回歸參數時,我們基于以上所有假設。如果違背了任意一條假設,模型都會推導錯誤。
Q10. 要測量因連續變量y(因變量)和x(自變量 )之間的線性關系,最適合下面哪種圖?
A.散點圖
B.柱狀圖
C.直方圖
D.以上都不是
答:A
使用散點圖去測量連續變量之間的線性關系是一個很好的選擇。我們可以發現一個變量怎么隨著另一個變量改變。散點圖顯示了兩個定量變量之間的關系。

















 京公網安備 11010502049343號
京公網安備 11010502049343號