


數(shù)據(jù)和商業(yè)智能(BI)是同一枚硬幣的兩面。在存儲、處理和分析方面的進展使數(shù)據(jù)民主化,因此,你不必成為數(shù)據(jù)庫專業(yè)人員或數(shù)據(jù)科學家,就可以使用大量的數(shù)據(jù)集并獲得深入的見解。當然還得通過一個學習曲線來獲取,但是自助式商業(yè)智能和數(shù)據(jù)可視化工具正在重新定義企業(yè)如何利用它們收集到的所有數(shù)據(jù)進行可操作的分析。然而,在商業(yè)智能或數(shù)據(jù)庫公司中,高級分析和人工智能(AI)數(shù)據(jù)庫是有區(qū)別的,它是為訓練機器學習(ML)和深度學習模型而設計的。

ML算法正在被編織進今天軟件的大部分結構中。消費者體驗融合了虛擬助手與人工智能。包括谷歌和微軟在內的科技巨頭正在進一步推動我們的智能未來,不僅是通過研究,還通過重寫他們的技術從而更深入的了解如何與人工智能合作。
訓練機器和深度學習模型的一個挑戰(zhàn)是,你需要訓練一個神經網(wǎng)絡的純粹的數(shù)據(jù)量和處理能力,例如,在諸如圖像分類或自然語言處理(NLP)等領域的復雜模式識別。因此,人工智能數(shù)據(jù)庫開始在市場上流行,以此來優(yōu)化企業(yè)的人工智能學習和培訓流程。筆者與gpu加速的關系數(shù)據(jù)庫提供商Kinetica進行了交談,后者已經建立了一個自己的人工智能數(shù)據(jù)庫,PCMag的常駐BI和數(shù)據(jù)庫專家Pam Baker還為我們揭秘了人工智能數(shù)據(jù)庫和傳統(tǒng)數(shù)據(jù)庫的工作方式。

人工智能數(shù)據(jù)庫是什么?
人工智能數(shù)據(jù)庫瞬息萬變的性質使得它很難建立術語。你經常聽到諸如ML、deep learning和AI這樣的術語,實際上,它們在人工智能的大傘下發(fā)展。因此,Baker表示,對于人工智能數(shù)據(jù)庫的定義,有兩種截然不同的定義:一種是實際的,另一種是就有點空想了。

在這個行業(yè)里有一種松散的共識,即人工智能數(shù)據(jù)庫將完全脫離自然語言查詢。用戶界面將是這樣的,你不需要依賴搜索詞和關鍵短語來找到你需要的信息,允許用戶用NLP來調用數(shù)據(jù)集就好。所以,現(xiàn)在的人工智能數(shù)據(jù)庫的定義實際上是對原本定義的一種延伸。
更實際的定義,本質上是使用一個專用數(shù)據(jù)庫來加速ML模型的訓練。一些科技公司已經在開發(fā)專門的人工智能芯片,以減輕新的硬件產品的沉重處理負載,原因是供應商們推出了更多的基于AI的功能,需要大量的計算能力。在數(shù)據(jù)方面,使用人工智能數(shù)據(jù)庫可以幫助你更好地解決與訓練ML和深度學習模型相關的容量、速度和復雜數(shù)據(jù)治理和管理挑戰(zhàn)方面的問題,以節(jié)省時間并優(yōu)化資源。
了解機器學習
“現(xiàn)在有很多加速ML的訓練的不同的策略,”Baker解釋說,一個是將基礎設施與人工智能研究人員的編碼分開,這樣自動化的功能就是處理基礎設施和培訓ML模型。這樣,你可以在30天或30分鐘內觀察,而不是花3個月的時間來培訓一個模型。
Kinetica將這個想法分解為一個集成的數(shù)據(jù)庫平臺,以對ML和深度學習建模進行優(yōu)化。人工智能數(shù)據(jù)庫結合了數(shù)據(jù)倉庫、高級分析和內存數(shù)據(jù)庫中的可視化功能。Kinetica先進技術集團的副總裁兼首席軟件工程師Mate Radalj表示,人工智能數(shù)據(jù)庫應該能夠同時吸收、探索、分析和可視化快速、復雜的數(shù)據(jù)。我們的目標是降低成本,產生新的收入,并整合ML模型,這樣企業(yè)就可以做出更高效、更有數(shù)據(jù)驅動的決策。
“人工智能數(shù)據(jù)庫是一般數(shù)據(jù)庫的子集,”Radalj說,“現(xiàn)在,人工智能數(shù)據(jù)庫非常流行。但是很多解決方案都使用分布式組件,如:[Apache]Spark,[Hadoop]MapReduce和HDFS。我們的數(shù)據(jù)庫是在一個平臺上用集成的cpu和gpu構建的。對我們來說,高層次的好處是更快的配置和更低的硬件內存,基于模型的訓練,快速周轉并分析集成到同一個平臺上。
人工智能數(shù)據(jù)庫是如何工作的?
在實踐中有許多人工智能數(shù)據(jù)庫的例子。Microsoft Batch AI提供基于云的基礎設施,用于培訓練深度學習和在微軟(Microsoft gpu)上運行的Azure Learn上的ML模型。該企業(yè)的Azure Data Lake產品,使企業(yè)和數(shù)據(jù)科學家更容易在分布式架構中處理和分析數(shù)據(jù)。
另一個例子是谷歌的AutoML方法,從根本上重新設計了ML模型的訓練方式。谷歌自動化ML模型設計是基于特定的數(shù)據(jù)集生成新的神經網(wǎng)絡架構,然后測試并迭代數(shù)千次,以編碼更好的系統(tǒng)。事實上,谷歌的人工智能現(xiàn)在可以創(chuàng)造比人類研究人員更好的模型。
谷歌的AutoML:用ML編寫ML代碼,所以你甚至不需要人。一些企業(yè)正試圖將先進的分析技術作為一種方式進行,但事實并非如此,而其他人則在這樣一個先進水平上做ML,這超出了大多數(shù)企業(yè)目前所能理解的范圍。
還有Kinetica,這家總部位于舊金山的初創(chuàng)公司已經籌集了6300萬美元的風險投資(VC)資金,為快速數(shù)據(jù)攝取和分析提供了一個高性能的SQL數(shù)據(jù)庫。Kinetica是Radalj所說的一個大規(guī)模并行處理(MPP)分布式數(shù)據(jù)庫和計算平臺,其中每個節(jié)點都包含內存數(shù)據(jù)、CPU和GPU。
是什么使得人工智能數(shù)據(jù)庫不同于傳統(tǒng)數(shù)據(jù)庫,Radalj解釋說,涉及到三個核心元素:
·加速數(shù)據(jù)攝入
·內存數(shù)據(jù)聯(lián)合本地(跨數(shù)據(jù)庫節(jié)點的并行處理)
·數(shù)據(jù)科學家、軟件工程師和數(shù)據(jù)庫管理員的共同平臺,可以更快地迭代和測試模型,并直接將結果應用于分析。
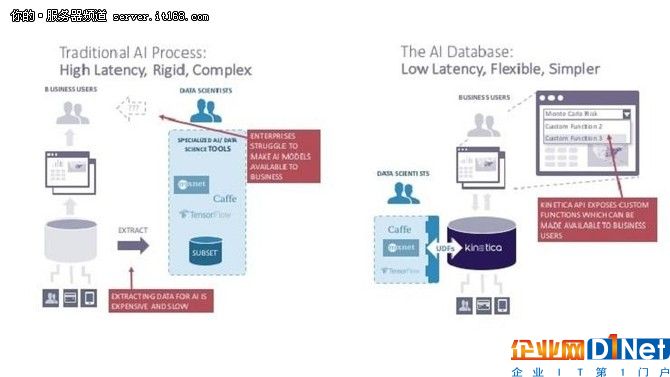
Kinetica 人工智能數(shù)據(jù)庫
對于所有的非數(shù)據(jù)庫和人工智能模型訓練專家來說,Radalj打破了這三個核心元素,并解釋了人工智能數(shù)據(jù)庫與有形的商業(yè)價值。數(shù)據(jù)可用性和數(shù)據(jù)攝取是關鍵的因素,因為處理實時流媒體數(shù)據(jù)的能力可以讓企業(yè)對人工智能驅動的洞察力采取快速行動。

Radalj表示,曾有零售客戶,每隔五分鐘就想要跟蹤銷售費率。于是,利用人工智能來預測,根據(jù)過去幾個小時的歷史數(shù)據(jù),明確他們是否應該補充庫存,然后優(yōu)化這一過程。但要實現(xiàn)機器驅動的庫存補充,就需要(數(shù)據(jù)庫)支持每秒600 - 1200個查詢。
Baker認為,ML需要大量的數(shù)據(jù),所以對于人工智能數(shù)據(jù)庫來說,快速攝取它是非常重要的。第二個因素,“內存數(shù)據(jù)的聯(lián)合位置”。內存中的數(shù)據(jù)庫存儲主要內存中的數(shù)據(jù),而不是單獨的磁盤存儲。它這樣做是為了更快地處理查詢,特別是在分析商業(yè)智能數(shù)據(jù)庫中。
因此,人工智能數(shù)據(jù)庫支持并行處理——它模擬了人腦處理多個刺激的能力,同時還能在可伸縮的數(shù)據(jù)庫基礎設施中繼續(xù)分布。這就阻止了更大的硬件占用,這導致了Radalj所說的“數(shù)據(jù)傳輸”,或者需要在不同的數(shù)據(jù)庫組件之間來回發(fā)送數(shù)據(jù)。
在實際的數(shù)據(jù)庫硬件方面,Kinetica與英偉達(Nvidia)合作,該企業(yè)擁有強大的人工智能gpu陣容,并正在與英特爾(Intel)探索更多的機會。很多企業(yè)正在密切關注新興的人工智能硬件和基于云的基礎設施,如谷歌的張量處理單元(tpu)。
最后,有一個統(tǒng)一的模型訓練過程的概念。如果一個人工智能數(shù)據(jù)庫的好處是更快的攝入和處理服務為企業(yè)的ML和深度學習的努力提供更大的、面向業(yè)務的目標,那么它只會更有效。

炒作還是現(xiàn)實?
Kinetica對于人工智能數(shù)據(jù)庫底線的定義是優(yōu)化計算和數(shù)據(jù)庫資源。這樣,你就可以創(chuàng)建更好的ML和深度學習模型,更快、更有效地訓練它們,并保持一條貫穿于在如何應用于你的業(yè)務方面。
Radalj給出了一個艦隊管理或卡車運輸公司的例子。在這個例子中,人工智能數(shù)據(jù)庫可以處理來自車隊的大量實時信息。然后,通過對地理空間數(shù)據(jù)的建模,并將其與分析相結合,數(shù)據(jù)庫可以動態(tài)地重新路由卡車并優(yōu)化路線。它更容易快速提供、原型和測試。
作為一個商業(yè)概念,深度學習、ML,所有這些都是一個可靠的概念。我們所研究的是可以解決的技術問題,即使我們還沒有解決它們。
至于人工智能數(shù)據(jù)庫是否都是炒作,或者它們是否代表了商業(yè)運行的一個重要趨勢,Baker認為,兩者都有一點。作為一個營銷術語,大數(shù)據(jù)現(xiàn)在已經不受歡迎了。現(xiàn)在有一些先進的、數(shù)據(jù)驅動的分析和真正的ML和深度學習算法之間的市場融合。無論如何,不管你是在談論什么,它的開始與結束都是數(shù)據(jù)。






實?人工智能數(shù)據(jù)庫未來在哪")

 京公網(wǎng)安備 11010502049343號
京公網(wǎng)安備 11010502049343號