


Greenplum 數據庫是最先進的分布式開源數據庫技術,主要用來處理大規模的數據分析任務,包括數據倉庫、商務智能(OLAP)和數據挖掘等。自2015年10月正式開源以來,受到國內外業內人士的廣泛關注。本文就社區關心的Greenplum數據庫技術架構進行介紹。

一. Greenplum數據庫簡介
大數據是個炙手可熱的詞,各行各業都在談。一談到大數據,好多人認為就是hadoop。實際上Hadoop只是大數據若干處理方案中的一個。現在的SQL、NoSQL、NewSQL、Hadoop等等,都能在不同層面或不同應用上處理大數據的某些問題。而Greenplum數據庫做為一個分布式大規模并行處理數據庫,在大多數情況下,更適合做大數據的存儲引擎、計算引擎和分析引擎。
Greenplum數據庫也簡稱GPDB。它擁有豐富的特性:
第一,完善的標準支持:GPDB完全支持ANSI SQL 2008標準和SQL OLAP 2003 擴展;從應用編程接口上講,它支持ODBC和JDBC。完善的標準支持使得系統開發、維護和管理都大為方便。而現在的 NoSQL,NewSQL和Hadoop 對 SQL 的支持都不完善,不同的系統需要單獨開發和管理,且移植性不好。
第二,支持分布式事務,支持ACID。保證數據的強一致性。
第三,做為分布式數據庫,擁有良好的線性擴展能力。在國內外用戶生產環境中,具有上百個物理節點的GPDB集群都有很多案例。
第四,GPDB是企業級數據庫產品,全球有上千個集群在不同客戶的生產環境運行。這些集群為全球很多大的金融、政府、物流、零售等公司的關鍵業務提供服務。
第五,GPDB是Greenplum(現在的Pivotal)公司十多年研發投入的結果。GPDB基于PostgreSQL 8.2,PostgreSQL 8.2有大約80萬行源代碼,而GPDB現在有130萬行源碼。相比PostgreSQL 8.2,增加了約50萬行的源代碼。
第六,Greenplum有很多合作伙伴,GPDB有完善的生態系統,可以與很多企業級產品集成,譬如SAS,Cognos,Informatic,Tableau等;也可以很多種開源軟件集成,譬如Pentaho,Talend 等。
二. Greenplum架構
2.1 平臺架構
圖(1)是Greenplum數據庫平臺概括圖。平臺分為四個層次,我們依次從下往上看。
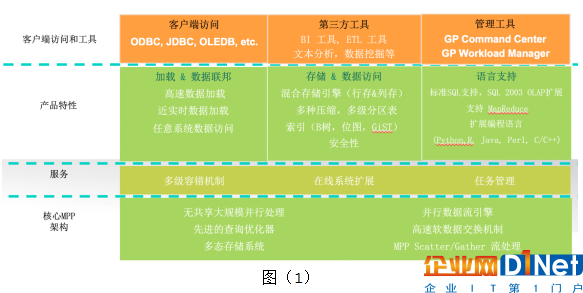
MPP核心架構
GPDB是大規模無共享的處理架構,后面會專門介紹;
先進的并行優化器是性能突出的關鍵之一。GPDB有兩個優化器,一個是基于PostgreSQL planner的優化器;一個是全新開發的ORCA優化器。ORCA是Greenplum 5年以前啟動的全新項目,這個優化器經過幾年的開發和測試之后,最近已經成為GPDB企業版本的默認優化器。
GPDB的存儲引擎支持多態存儲,一個表的數據可以根據訪問模式的不同使用不同的存儲方式。存儲方式對用戶透明,執行查詢時,不用關心待訪問的數據使用的存儲模式,優化器會自動選擇最佳查詢計劃。
分布式數據庫中,某些操作(例如跨節點關聯)需要多個節點間進行數據交換。GPDB的并行數據庫流引擎,可以根據數據的特點,例如分布方式、數據量等選擇最合適的數據流操作符。目前GPDB支持兩種數據流操作符:重分發(Redistribution)和廣播(Broadcast)。重分發根據數據的哈希值重新分發到各個數據節點上,適用于數據量大的情況;廣播則將數據發送給所有數據節點,適用于數據量較小的情況,例如維度表。
軟件交換機是GPDB的一個重要組件,軟件交換機可以在各個數據節點間及與主節點間建立可靠的UDP數據通訊機制,是實現高效數據流的核心。
Scatter/Gather 流引擎是專為并行數據加載和導出而設計,Scatter指數據通過并行加載服務器并行分散到各個數據節點,Gather指數據在 GPDB內部可以根據分布策略按需并行分發。
服務層
GPDB支持多級容錯機制和高可用:
o 主節點(Master)高可用:為了避免主節點單點故障,可以設置一個主節點的副本(稱為 Standby Master),他們之間通過流復制技術實現同步復制。當主節點發生故障時,從節點成為主節點,處理用戶請求并協調查詢執行。它們之間通過心跳檢測故障。
o 數據節點(Segment)高可用:每個數據節點都可以配備一個鏡像,它們之間通過文件操作級別的同步實現數據的同步復制(稱為filerep技術)。數據節點上建議使用RAID5磁盤,以進一步提高數據的高可用。故障檢測進程(ftsprobe)定期發送心跳給各個數據節點。當某個節點發生故障時,GPDB會自動進行故障切換。
o 網絡高可用:為了避免網絡的單點故障,每個主機配置多個網口,并使用多個交換機避免網絡故障時造成整個服務不可用。
在線擴展:數據量增大,現有集群不能滿足需求時,可以對GPDB數據庫進行動態擴展。擴展過程中,業務可以繼續運行,不需要宕機。
任務管理是指對資源的管理和使用情況的管理。
產品特性
數據加載在后面會專門介紹。
數據聯邦是比較有意思的,最近“數據湖泊”這個詞非常火熱,數據湖泊的目的是不需再對數據像以前那樣經過定制,生成特定的業務報表;而是保存原始數據,什么時候想分析就從原始數據上直接處理。GBDB可以實現數據湖泊(我們稱之為數據聯邦),它能訪問和處理數據中心里面的所有數據,不管你的數據是在Hadoop、在文件系統上、還是在其他數據庫中,Greenplum可以使用一個SQL在保證ACID的前提下訪問所有數據。
GPDB即支持行存,也支持列存。還為不需更新的數據存儲和處理進行了專門的優化。
支持多種壓縮方法,包括QuickLZ,Zlib,RLE 等。
支持多級分區表,分區支持多種模式,包括范圍,列表等。
支持B樹、位圖和GiST 等索引
GPDB認證機制支持多種方式,包括LDAP和Kerberos等。通過訪問控制列表(ACL),可以實現靈活的基于角色的安全控制。
擴展語言支持:GPDB 支持使用多種流行語言實現用戶自定義函數(UDF,類似于Oracle的存儲過程),包括 Python,R,Java,Perl,C/C++ 等。
地理信息處理:通過集成PostGIS,GPDB支持對地理信息進行存儲和分析。
內建數據挖掘算法庫:通過MADLib(現在是Apache孵化項目)算法庫,可以內建幾十種常見的數據分析和挖掘算法到GPDB數據庫中,包括邏輯回歸,決策樹,隨機森林等。不需要寫任何算法代碼,通過SQL就可以使用其中的所有算法。
文本檢索:通過GPText擴展,GPDB可以支持高效靈活豐富的全文檢索功能。與 MADLib 合用,可以進行并行文本分析和挖掘。
客戶端訪問和工具
通過psql命令行工具可以訪問GPDB數據庫的所有功能,此外還提供了ODBC、JDBC、OLEDB、libpq等應用編程接口。
數據庫或者數據集群的管理工具非常重要,GPDB提供了圖形化的管理工具GPCC(Greenplum Command Center),幫你管理狀態,監控資源使用情況。
Greenplum Workload Manager是剛剛發布的新產品,用以實現基于規則的資源管理。它支持自定義規則,當某個SQL滿足規則描述的條件時會執行某些操作。比如你可以定義規則自動取消消耗CPU資源達50%以上的查詢。
2.2 大規模并行處理(MPP)無共享架構
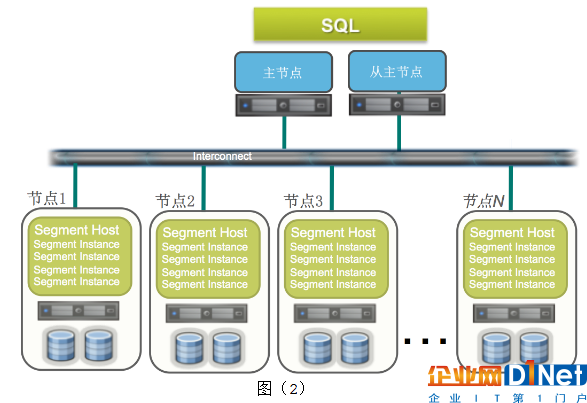
MPP 是Greenplum數據庫最突出的特色。現在很流行MPP這個詞,我們可以看一下它是什么意思。下邊圖(2)中,主節點有兩個,一個是主節點,一個是從主節點。通過軟交換機制,也就是通過高速網絡,主節點連到數據節點。每個數據節點有自己的CPU,自己的內存,自己的硬盤,他們唯一共享的就是網絡。這也是稱為無共享架構的原因。這種架構的好處是集群是分布式的環境,數據可以分布在很多節點上進行并行處理,可以做到線性擴展。
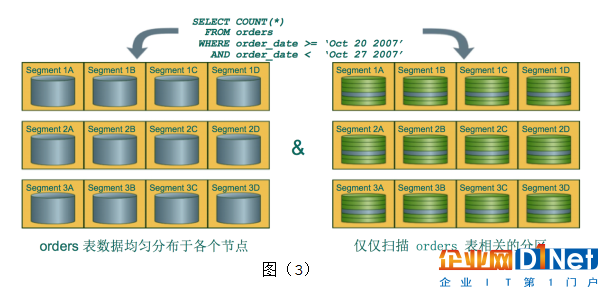
在分布式數據庫中,性能好壞的最重要因素是數據分布是否均勻。如果數據分布不均勻,有的節點上數據非常多,有的節點數據很少,這樣會出現短板效應,整個SQL的效率不會很好。Greenplum支持多種數據分布的策略,默認使用主鍵或者第一個字段進行哈希分布,還支持隨機分布。除了橫向上數據可以按節點分布之外,在某個節點上還可以對數據進行分區。分區的規則比較靈活,可以按照范圍分區,也可以按照列表值分區,如圖(3)。
2.3 并行查詢計劃和執行
下面是個簡單的SQL,如圖(4),從兩張表中找到2008年的銷售數據。圖中右邊是這個SQL的查詢計劃。從生成的查詢計劃樹中看到有三種不同的顏色,顏色相同表示做同一件事情,我們稱之為分片/切片(Slice)。最下層的橙色切片中有一個重分發節點,這個節點將本節點的數據重新分發到其他節點上。中間綠色切片表示分布式數據關聯(HashJoin)。最上面切片負責將各個數據節點收到的數據進行匯總。
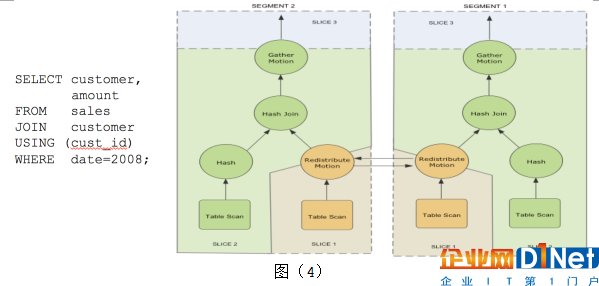
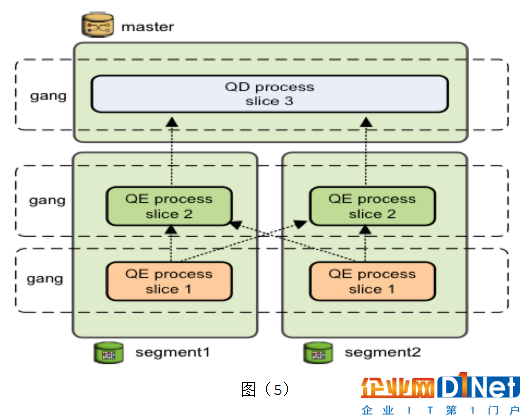
然后看看這個查詢計劃的執行,如圖(5)。主節點(Master)上的調度器(QD)會下發查詢任務到每個數據節點,數據節點收到任務后(查詢計劃樹),創建工作進程(QE)執行任務。如果需要跨節點數據交換(例如上面的HashJoin),則數據節點上會創建多個工作進程協調執行任務。不同節點上執行同一任務(查詢計劃中的切片)的進程組成一個團伙(Gang)。數據從下往上流動,最終Master返回給客戶端。
2.4 多態存儲
上面介紹了GPDB的特點和SQL執行計劃以及執行過程,那數據在每個節點上到底怎么樣存儲?
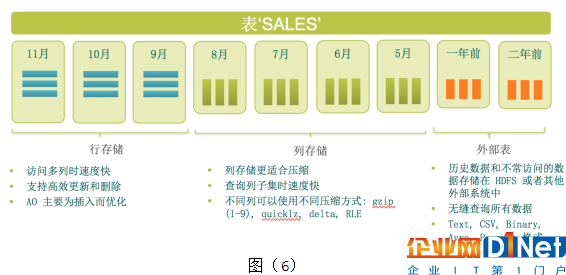
Greenplum提供稱為“多態存儲”的靈活存儲方式。多態存儲可以根據數據熱度或者訪問模式的不同而使用不同的存儲方式。一張表的不同數據可以使用不同的物理存儲方式,如圖(6)。支持的存儲方式包含:
行存儲:行存儲是傳統數據庫常用的存儲方式,特點是訪問比較快,多列更新比較容易。
列存儲:列存儲按列保存,不同列的數據存儲在不同的地方(通常是不同文件中)。適合一次只訪問寬表中某幾個字段的情況。列存儲的另外一個優勢是壓縮比高。
外部表:數據保存在其他系統中例如HDFS,數據庫只保留元數據信息。
2.5 大規模并行數據加載
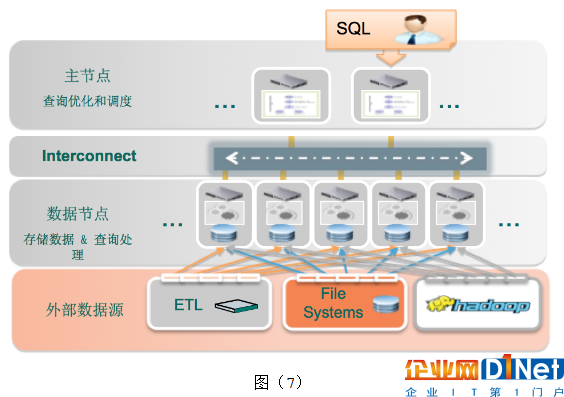
作為一個數據庫,一定會保存和處理數據。那數據來源于什么地方?Oracle這樣的數據庫里面的數據多是客戶生成的,譬如你銀行轉賬、淘寶訂單等。對于數據分析型的數據庫,其源數據通常是在其他系統中,而且數據量很大。這樣數據加載的能力就變得非常重要。Greenplum提供了非常好的數據加載方案,支持高速的加載各種數據源的不同數據格式的數據,如圖(7)。
并行數據加載:因為是并行數據加載,所以性能非常好。Greenplum有叫DCA的一體機產品,第一代DCA可以做到10TB/小時;第二代為16TB/小時。第三代很快就要發布了,速度會更快。
數據源和數據格式:數據源支持Hadoop,文件系統,數據庫,還有 ETL管理的數據。數據格式支持文本,CSV,Parquet,Avro等。
三. Greenplum核心組件
Greenplum 數據庫包括以下核心組件:
解析器:主節點收到客戶端請求后,執行認證操作。認證成功建立連接后,客戶端可以發送查詢給數據庫。解析器負責對收到的查詢SQL字符串進行詞法解析、語法解析,并生成語法樹。
優化器:優化器對解析器的結果進行處理,從所有可能的查詢計劃中選擇一個最優或者接近最優的計劃,生成查詢計劃。查詢計劃描述了如何執行一個查詢,通常以樹形結構描述。Greenplum最新的優化器叫 ORCA,關于 ORCA,可以從 ACM 論文中獲得詳細信息。(http://dl.acm.org/citation.cfm?id=2595637&dl=ACM&coll=DL&CFID=569750122&CFTOKEN=89888184)
調度器(QD):調度器發送優化后的查詢計劃給所有數據節點(Segments)上的執行器(QE)。調度器負責任務的執行,包括執行器的創建、銷毀、錯誤處理、任務取消、狀態更新等。
執行器(QE):執行器收到調度器發送的查詢計劃后,開始執行自己負責的那部分計劃。典型的操作包括數據掃描、哈希關聯、排序、聚集等。
Interconnect:負責集群中各個節點間的數據傳輸。
系統表:系統表存儲和管理數據庫、表、字段的元數據。每個節點上都有相應的拷貝。
分布式事務:主節點上的分布式事務管理器協調數據節點上事務的提交和回滾操作,由兩階段提交(2PC)實現。每個數據節點都有自己的事務日志,負責自己節點上的事務處理。
四、Greenplum開源
2015年3月份,Pivotal宣布了Greenplum的開源計劃,經過6個月緊鑼密鼓的工作,于10月27號正式開源。官方網站為http://greenplum.org。許可證書使用Apache 2許可證。
Greenplum 開源社區提供了運行環境沙盒以及使用教程,里面包含了Greenplum數據庫的一些主要特性。從https://github.com/greenplum-db/gpdb-sandbox-tutorials 可以下載沙盒和教程。
有關Greenplum數據庫使用和開發的任何問題都可以去郵件列表討論:郵件列表有兩個:[email protected] 和[email protected]。
源代碼位于https://github.com/greenplum-db/gpdb,開源不到兩個月就有1187個收藏,256個fork,超過150個pull request,其中136個pull request 已經關閉。貢獻者中除了包含Pivotal的員工外,還有來自全球(包括中國、美國、日本和歐洲)的社區開發人員。關于從源代碼編譯和安裝Greenplum數據庫,可以參考:http://gpdb.rocks/gpdb/2015/10/29/how-to-build-gpdb.html








 京公網安備 11010502049343號
京公網安備 11010502049343號