









作者:周雷皓 ,百度外賣大數(shù)據(jù)工程師。
來(lái)自:《程序員》3月技術(shù)板原創(chuàng)投稿。
摘要:本文介紹了大數(shù)據(jù)引擎Greenplum的架構(gòu)和部分技術(shù)特點(diǎn),從GPDB基本背景開始,在架構(gòu)的層面上講解GPDB系統(tǒng)內(nèi)部各個(gè)模塊的概貌,然后圍繞GPDB的自身特性,并行執(zhí)行和運(yùn)維等技術(shù)細(xì)節(jié),闡述了為什么選擇使用Greenplum作為下一代的查詢引擎解決方案。
Greenplum的MPP架構(gòu)
Greenplum(以下簡(jiǎn)稱GPDB)是一款開源數(shù)據(jù)倉(cāng)庫(kù)。基于開源的PostgreSQL改造,主要用來(lái)處理大規(guī)模數(shù)據(jù)分析任務(wù),相比Hadoop,Greenplum更適合做大數(shù)據(jù)的存儲(chǔ)、計(jì)算和分析引擎。
GPDB是典型的Master/Slave架構(gòu),在Greenplum集群中,存在一個(gè)Master節(jié)點(diǎn)和多個(gè)Segment節(jié)點(diǎn),其中每個(gè)節(jié)點(diǎn)上可以運(yùn)行多個(gè)數(shù)據(jù)庫(kù)。Greenplum采用shared nothing架構(gòu)(MPP)。典型的Shared Nothing系統(tǒng)會(huì)集數(shù)據(jù)庫(kù)、內(nèi)存Cache等存儲(chǔ)狀態(tài)的信息;而不在節(jié)點(diǎn)上保存狀態(tài)的信息。節(jié)點(diǎn)之間的信息交互都是通過(guò)節(jié)點(diǎn)互聯(lián)網(wǎng)絡(luò)實(shí)現(xiàn)。通過(guò)將數(shù)據(jù)分布到多個(gè)節(jié)點(diǎn)上來(lái)實(shí)現(xiàn)規(guī)模數(shù)據(jù)的存儲(chǔ),通過(guò)并行查詢處理來(lái)提高查詢性能。每個(gè)節(jié)點(diǎn)僅查詢自己的數(shù)據(jù)。所得到的結(jié)果再經(jīng)過(guò)主節(jié)點(diǎn)處理得到最終結(jié)果。通過(guò)增加節(jié)點(diǎn)數(shù)目達(dá)到系統(tǒng)線性擴(kuò)展。
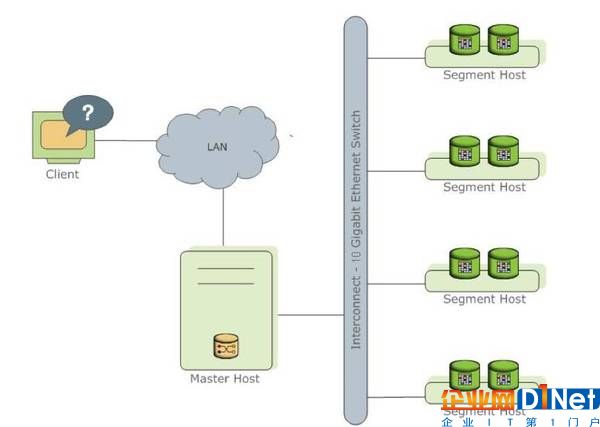
圖1 GPDB的基本架構(gòu)
如上圖1為GPDB的基本架構(gòu),客戶端通過(guò)網(wǎng)絡(luò)連接到gpdb,其中Master Host是GP的主節(jié)點(diǎn)(客戶端的接入點(diǎn)),Segment Host是子節(jié)點(diǎn)(連接并提交SQL語(yǔ)句的接口),主節(jié)點(diǎn)是不存儲(chǔ)用戶數(shù)據(jù)的,子節(jié)點(diǎn)存儲(chǔ)數(shù)據(jù)并負(fù)責(zé)SQL查詢,主節(jié)點(diǎn)負(fù)責(zé)相應(yīng)客戶端請(qǐng)求并將請(qǐng)求的SQL語(yǔ)句進(jìn)行轉(zhuǎn)換,轉(zhuǎn)換之后調(diào)度后臺(tái)的子節(jié)點(diǎn)進(jìn)行查詢,并將查詢結(jié)果返回客戶端。
Greenplum Master
Master只存儲(chǔ)系統(tǒng)元數(shù)據(jù),業(yè)務(wù)數(shù)據(jù)全部分布在Segments上。其作為整個(gè)數(shù)據(jù)庫(kù)系統(tǒng)的入口,負(fù)責(zé)建立與客戶端的連接,SQL的解析并形成執(zhí)行計(jì)劃,分發(fā)任務(wù)給Segment實(shí)例,并且收集Segment的執(zhí)行結(jié)果。正因?yàn)镸aster不負(fù)責(zé)計(jì)算,所以Master不會(huì)成為系統(tǒng)的瓶頸。
Master節(jié)點(diǎn)的高可用(圖2),類似于Hadoop的NameNode HA,如下圖,Standby Master通過(guò)synchronization process,保持與Primary Master的catalog和事務(wù)日志一致,當(dāng)Primary Master出現(xiàn)故障時(shí),Standby Master承擔(dān)Master的全部工作。
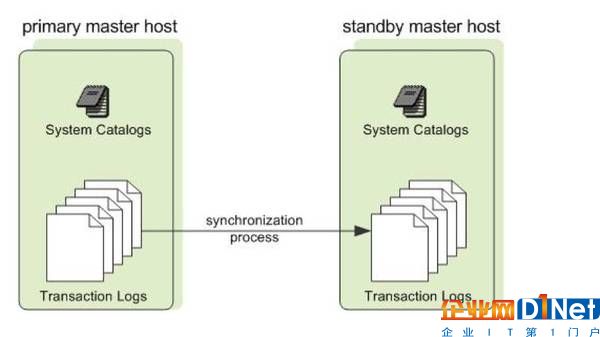
圖2 Master節(jié)點(diǎn)的高可用Segments
Greenplum中可以存在多個(gè)Segment,Segment主要負(fù)責(zé)業(yè)務(wù)數(shù)據(jù)的存儲(chǔ)和存取(圖3),用戶查詢SQL的執(zhí)行,每個(gè)Segment存放一部分用戶數(shù)據(jù),但是用戶不能直接訪問(wèn)Segment,所有對(duì)Segment的訪問(wèn)都必須經(jīng)過(guò)Master。進(jìn)行數(shù)據(jù)訪問(wèn)時(shí),所有的Segment先并行處理與自己有關(guān)的數(shù)據(jù),如果需要關(guān)聯(lián)處理其他Segment上的數(shù)據(jù),Segment可以通過(guò)Interconnect進(jìn)行數(shù)據(jù)的傳輸。Segment節(jié)點(diǎn)越多,數(shù)據(jù)就會(huì)打的越散,處理速度就越快。因此與Share All數(shù)據(jù)庫(kù)集群不同,通過(guò)增加Segment節(jié)點(diǎn)服務(wù)器的數(shù)量,Greenplum的性能會(huì)成線性增長(zhǎng)。
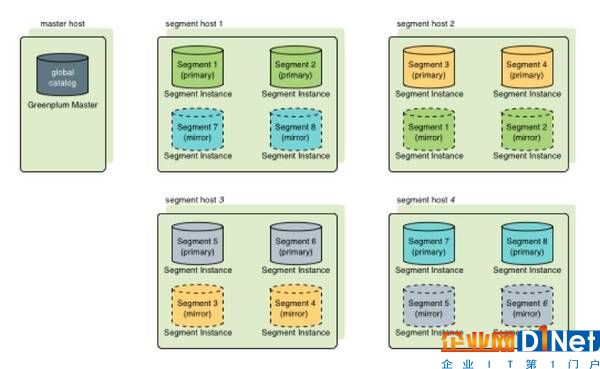
圖3 Segment負(fù)責(zé)業(yè)務(wù)數(shù)據(jù)的存取
每個(gè)Segment的數(shù)據(jù)冗余存放在另一個(gè)Segment上,數(shù)據(jù)實(shí)時(shí)同步,當(dāng)Primary Segment失效時(shí),Mirror Segment將自動(dòng)提供服務(wù),當(dāng)Primary Segment恢復(fù)正常后,可以很方便的使用gprecoverseg -F工具來(lái)同步數(shù)據(jù)。
Interconnect
Interconnect是Greenplum架構(gòu)中的網(wǎng)絡(luò)層(圖4),是GPDB系統(tǒng)的主要組件,默認(rèn)情況下,使用UDP協(xié)議,但是Greenplum會(huì)對(duì)數(shù)據(jù)包進(jìn)行校驗(yàn),因此可靠性等同于TCP,但是性能上會(huì)更好。在使用TCP協(xié)議的情況下,Segment的實(shí)例不能超過(guò)1000,但是使用UDP則沒有這個(gè)限制。
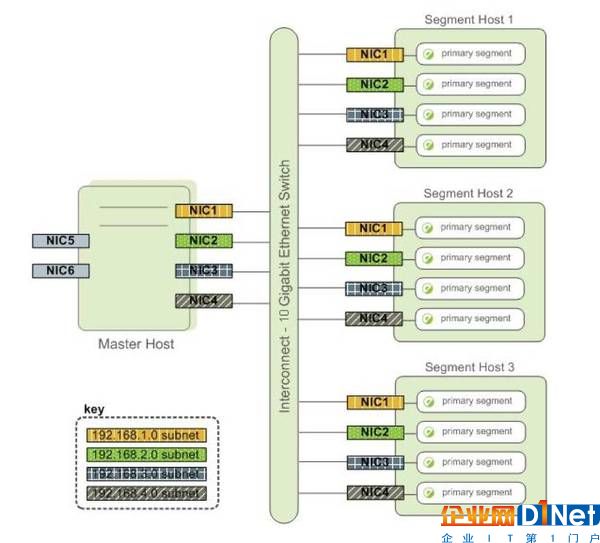
圖4 Greenplum網(wǎng)絡(luò)層InterconnectGreenplum,新的解決方案
前面介紹了GPDB的基本架構(gòu),讓讀者對(duì)GPDB有了初步的了解,下面對(duì)GPDB的部分特性描述可以很好的理解為什么選擇GPDB作為新的解決方案。
豐富的工具包,運(yùn)維從此不是事兒
對(duì)比開源社區(qū)的其他項(xiàng)目在運(yùn)維上的困難,GPDB提供了豐富的管理工具,圖形化的web監(jiān)控頁(yè)面,幫助管理員更好的管理集群,監(jiān)控集群本身以及所在服務(wù)器的運(yùn)行狀況。
最近的公有云集群遷移過(guò)程中,impala總查詢段達(dá)到100的時(shí)候,系統(tǒng)開始變得極不穩(wěn)定,后來(lái)在外援的幫助下發(fā)現(xiàn)是系統(tǒng)內(nèi)核本身的問(wèn)題,在惡補(bǔ)系統(tǒng)內(nèi)核參數(shù)的同時(shí),發(fā)現(xiàn)GPDB的工具也變相的填充了我們的短板,比如提供了gpcheck和gpcheckperf等命令,用以檢測(cè)GPDB運(yùn)行所需要的系統(tǒng)配置是否合理以及對(duì)相關(guān)硬件做性能測(cè)試,如下,執(zhí)行g(shù)pcheck命令后,檢測(cè)sysctl.conf中參數(shù)的設(shè)置是否符合要求,如果對(duì)參數(shù)的含義感興趣,可以自行百度學(xué)習(xí)。
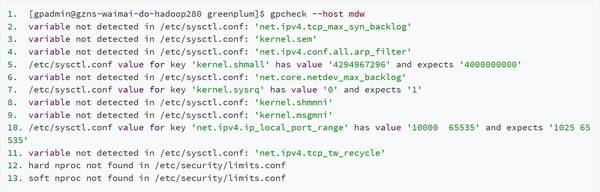
(點(diǎn)擊可查看高清版)
另外,在安裝過(guò)程中,用其提供的gpssh-exkeys命令打通所有機(jī)器免密登錄后,可以很方便的使用gpassh命令對(duì)所有的機(jī)器批量操作,如下圖演示了在master主機(jī)上執(zhí)行g(shù)pssh命令后,在集群的五臺(tái)機(jī)器上批量執(zhí)行pwd命令。
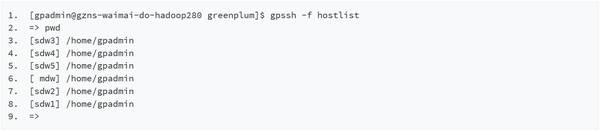
(點(diǎn)擊可查看高清版)
諸如上述的工具GPDB還提供了很多,比如恢復(fù)segment節(jié)點(diǎn)的gprecoverseg命令,比如切換主備節(jié)點(diǎn)的gpactivatestandby命令,等等。這類工具的提供讓集群的維護(hù)變得很簡(jiǎn)單,當(dāng)然我們也可以基于強(qiáng)大的工具包開發(fā)自己的管理后臺(tái),讓集群的維護(hù)更加的傻瓜化。
查詢計(jì)劃和并行執(zhí)行,SQL優(yōu)化利器
查詢計(jì)劃包括了一些傳統(tǒng)的操作,比如:掃表、關(guān)聯(lián)、聚合、排序等。另外,GPDB有一個(gè)特定的操作:移動(dòng)(motion)。移動(dòng)操作涉及到查詢處理期間在Segment之間移動(dòng)數(shù)據(jù)。
下面的SQL是TPCH中Query 1的簡(jiǎn)化版,用來(lái)簡(jiǎn)單描述查詢計(jì)劃。
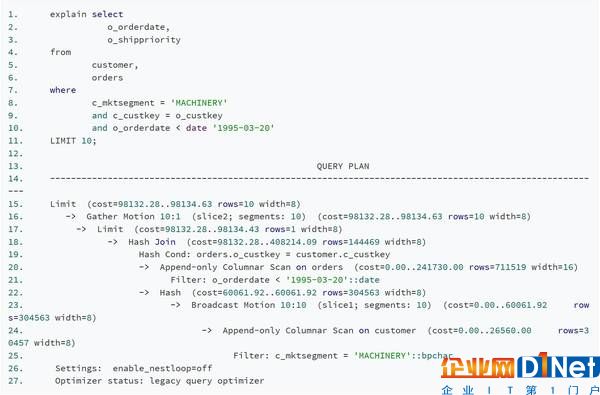
(點(diǎn)擊可查看高清版)
執(zhí)行計(jì)劃執(zhí)行從下至上,可以看到每個(gè)計(jì)劃節(jié)點(diǎn)操作的額外信息。
Segment節(jié)點(diǎn)掃描各自所存儲(chǔ)的customer表數(shù)據(jù),按照過(guò)濾條件生成結(jié)果數(shù)據(jù),并將自己生成的結(jié)果數(shù)據(jù)依次發(fā)送到其他Segment。
每個(gè)Segment上,orders表的數(shù)據(jù)和收到的rs做join,并把結(jié)果數(shù)據(jù)返回給master
上面的執(zhí)行過(guò)程可以看出,GPDB是將結(jié)果數(shù)據(jù)給每個(gè)含有orders表數(shù)據(jù)的節(jié)點(diǎn)都發(fā)了一份。為了最大限度的實(shí)現(xiàn)并行化處理,GPDB會(huì)將查詢計(jì)劃分成多個(gè)處理步驟。在查詢執(zhí)行期間,分發(fā)到Segment上的各部分會(huì)并行的執(zhí)行一系列的處理工作,并且只處理屬于自己部分的工作。重要的是,可以在同一個(gè)主機(jī)上啟動(dòng)多個(gè)postgresql數(shù)據(jù)庫(kù)進(jìn)行更多表的關(guān)聯(lián)以及更復(fù)雜的查詢操作,單臺(tái)機(jī)器的性能得到更加充分的發(fā)揮。
如何查看執(zhí)行計(jì)劃?
如果一個(gè)查詢表現(xiàn)出很差的性能,可以通過(guò)查看執(zhí)行計(jì)劃找到可能的問(wèn)題點(diǎn)。
計(jì)劃中是否有一個(gè)操作花費(fèi)時(shí)間超長(zhǎng)?
規(guī)劃期的評(píng)估是否接近實(shí)際情況?
選擇性強(qiáng)的條件是否較早出現(xiàn)?
規(guī)劃期是否選擇了最佳的關(guān)聯(lián)順序?
規(guī)劃其是否選擇性的掃描分區(qū)表?
規(guī)劃其是否合適的選擇了Hash聚合與Hash關(guān)聯(lián)操作?
高效的數(shù)據(jù)導(dǎo)入,批量不再是瓶頸
前面提到,Greenplum的Master節(jié)點(diǎn)只負(fù)責(zé)客戶端交互和其他一些必要的控制,而不承擔(dān)任何的計(jì)算任務(wù)。在加載數(shù)據(jù)的時(shí)候,會(huì)先進(jìn)行數(shù)據(jù)分布的處理工作,為每個(gè)表指定一個(gè)分發(fā)列,接下來(lái),所有的節(jié)點(diǎn)同時(shí)讀取數(shù)據(jù),根據(jù)選定的Hash算法,將當(dāng)前節(jié)點(diǎn)數(shù)據(jù)留下,其他數(shù)據(jù)通過(guò)interconnect傳輸?shù)狡渌?jié)點(diǎn)上去,保證了高性能的數(shù)據(jù)導(dǎo)入。通過(guò)結(jié)合外部表和gpfdist服務(wù),GPDB可以做到每小時(shí)導(dǎo)入2TB數(shù)據(jù),在不改變ETL流程的情況下,可以從impala快速的導(dǎo)入計(jì)算好的數(shù)據(jù)為消費(fèi)提供服務(wù)。
使用gpfdist的優(yōu)勢(shì)在于其可以確保再度去外部表的文件時(shí),GPDB系統(tǒng)的所有Segment可以完全被利用起來(lái),但是需要確保所有Segment主機(jī)可以具有訪問(wèn)gpfdist的網(wǎng)絡(luò)。
其他
GPDB支持LDAP認(rèn)證,這一特性的支持,讓我們可以把目前Impala的角色權(quán)限控制無(wú)縫的遷移到GPDB。
GPDB基于Postgresql 8.2開發(fā),通過(guò)psql命令行工具可以訪問(wèn)GPDB數(shù)據(jù)庫(kù)的所有功能,另外支持JDBC、ODBC等訪問(wèn)方式,產(chǎn)品接口層只需要進(jìn)行少量的適配即可使用GPDB提供服務(wù)。
GPDB支持基于資源隊(duì)列的管理,可以為不同類型工作負(fù)載創(chuàng)建資源獨(dú)立的隊(duì)列,并且有效的控制用戶的查詢以避免系統(tǒng)超負(fù)荷運(yùn)行。比如,可以為VIP用戶,ETL生產(chǎn),任性和adhoc等創(chuàng)建不同的資源隊(duì)列。同時(shí),支持優(yōu)先級(jí)的設(shè)置,在并發(fā)爭(zhēng)用資源時(shí),高優(yōu)先級(jí)隊(duì)列的語(yǔ)句將可以獲得比低優(yōu)先級(jí)資源隊(duì)列語(yǔ)句更多的資源。
最近在對(duì)GPDB做調(diào)研和測(cè)試,過(guò)程中用TPCH做性能的測(cè)試,通過(guò)和網(wǎng)絡(luò)上其他服務(wù)的對(duì)比發(fā)現(xiàn)在5個(gè)節(jié)點(diǎn)的情況下已經(jīng)有了很高的查詢速度,但是由于測(cè)試環(huán)境服務(wù)器問(wèn)題,具體的性能數(shù)據(jù)還要在接下來(lái)的新環(huán)境中得出,不過(guò)GPDB基于postgresql開發(fā),天生支持豐富的統(tǒng)計(jì)函數(shù),支持橫向的線性擴(kuò)展,內(nèi)部容錯(cuò)機(jī)制,有很多功能強(qiáng)大的運(yùn)維管理命令和代碼,相比impala而言,顯然在SQL的支持、實(shí)時(shí)性和穩(wěn)定性上更勝一籌。
本文只是對(duì)Greenplum的初窺,接下來(lái)更深入的剖析以及在工作中的實(shí)踐經(jīng)驗(yàn)分享也請(qǐng)關(guān)注DA的wiki。更多的關(guān)于Greenplum基本的語(yǔ)法和特性,也可以參考PostgreSQL的官方文檔。
本文參考:Pivotal Greenplum Database 4.3.9.1 Documentation















 京公網(wǎng)安備 11010502049343號(hào)
京公網(wǎng)安備 11010502049343號(hào)