


今天,OpenAI在官方博客上丟出了7個研究過程中發現的未解決問題。
OpenAI希望這些問題能夠成為新手入坑AI的一種有趣而有意義的方式,也幫助從業者提升技能。
OpenAI版AI界七大未解之謎,現在正式揭曉——

1. Slitherin’
難度指數:☆☆
實現并解決貪吃蛇的多玩家版克隆作為Gym環境。
環境:場地很大,里面有多條蛇,蛇通過吃隨機出現的水果生長,一條蛇在與另一條蛇、自己或墻壁相撞時即死亡,當所有的蛇都死了,游戲結束。
智能體:使用自己選擇的自我對弈的RL算法解決環境問題。你需要嘗試各種方法克服自我對弈的不穩定性。
檢查學習行為:智能體是否學會了適時捕捉食物并避開其他蛇類?是否學會了攻擊、陷害、或者聯合起來對付競爭對手?

2. 分布式強化學習中的參數平均
難度指數:☆☆☆
這指的是探究參數平均方案對RL算法中樣本復雜度和通信量影響。一種簡單的解決方法是平均每個更新的每個worker的梯度,但也可以通過獨立地更新worker、減少平均參數節省通信帶寬。
這樣做還有一個好處:在任何給定的時間內,我們都有不同參數的智能體,可能出現更好的探測行為。另一種可能是使用EASGD這樣的算法,它可以在每次更新時將參數部分結合在一起。
3. 通過生成模型完成的不同游戲中的遷移學習
難度指數:☆☆☆
這個流程如下:
訓練11個Atari游戲的策略。從每個游戲的策略中,生成1萬個軌跡,每個軌跡包含1000步行動。
將一個生成模型(如論文Attention Is All You Need提出的Transformer)與10個游戲產生的軌跡相匹配。
然后,在第11場比賽中微調上述模型。
你的目標是量化10場比賽預訓練時的好處。這個模型需要什么程度的訓練才能發揮作用?當第11個游戲的數據量減少10x時,效果的大小如何變化?如果縮小100x呢?

4. 線性注意Transformer
難度指數:☆☆☆
Transformer模型使用的是softmax中的軟注意力(soft attention)。如果可以使用線性注意力(linear attention),我們就能將得到的模型用于強化學習。
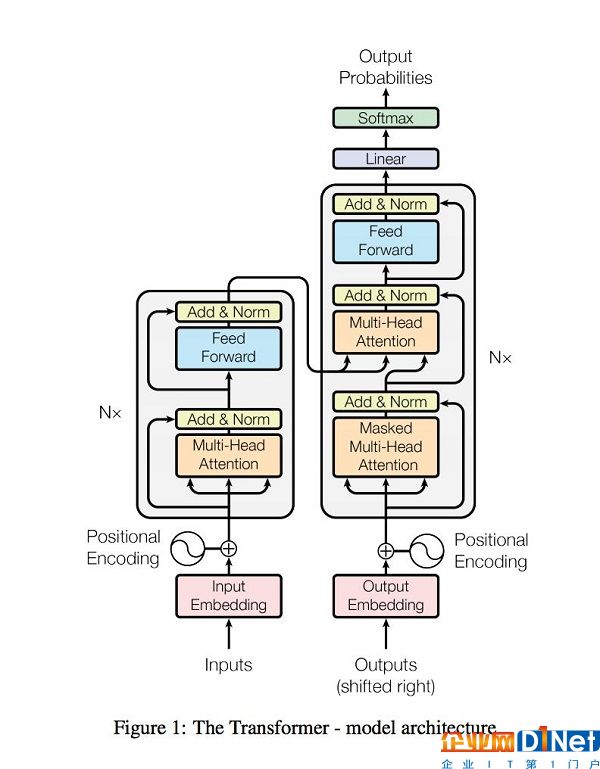
具體來說,在復雜環境下使用Transformer部署RL不切實際,但運行一個具有快速權重(fast weight)的RNN可行。
你的目標是接受任何語言建模任務,訓練Transformer,然后找到一種在不增加參數總數情況下,用具有不同超參數的線性注意Transformer獲取每個字符/字的相同位元的方法。
先給你潑盆冷水:這可能是無法實現的。再給你一個潛在的有用提示,與使用softmax注意力相比,線性注意轉化器很可能需要更高的維度key/value向量,這能在不顯著增加參數數量的情況下完成。
5. 已學習數據的擴充
難度指數:☆☆☆
可以用學習過的數據VAE執行“已學習數據的擴充”。
我們首先可能需要在輸入數據上訓練一個VAE,然后將每個訓練點編碼到一個潛在的空間,之后在其中應用一個簡單(如高斯)擾動,最后解碼回到觀察的空間。用這種方法是否能得到更好的泛化,目前還是一個謎題。
這種數據擴充的一個潛在優勢是,它可能包含視角變換、場景光纖變化等很多非線性轉換。
6. 強化學習中的正則化
難度指數:☆☆☆☆
這指的是實驗性研究和定性解釋不同正則化方法對RL算法的影響。
在監督學習中,正則化對于優化模型和防止過擬合具有極其重要的意義,其中包含一些效果很贊的方法,如dropout、批標準化和L2正則化等。
然而,在策略梯度和Q-learning等強化學習算法上,研究人員還沒有找到合適的正則化方法。順便說一下,人們在RL中使用的模型要比在監督學習中使用的模型小得多,因為大模型表現更差。
7. Olympiad Inequality問題的自動解決方案
難度指數:☆☆☆☆☆
Olympiad Inequality問題很容易表達,但解決這個問題往往需要巧妙的手法。
建立一個關于Olympiad Inequality問題的數據集,編寫一個可以解決大部分問題的程序。目前還不清楚機器學習在這里是否有用,但你可以用一個學習的策略減少分支因素。








 京公網安備 11010502049343號
京公網安備 11010502049343號