


本周一,正如其它每個周一,一億多 Spotify 用戶每人都收到了一個嶄新的歌單。這個叫做每周發現的歌單內混合了用戶從未聽過但是可能會喜歡的 30首歌曲。效果堪稱神奇。
我自己是 Spotify 的超級粉絲,對每周發現尤其喜愛。為什么呢?因為我覺得它懂我。它比我生命中的任何人都更清楚我的音樂品味。我很高興每周它都能滿足我的需求,一如既往地推薦一些我自己永遠都不會找到或知道會喜歡的歌曲。
對于那些兩耳不聞窗外事的人們,請允許我介紹一下我的虛擬好友:
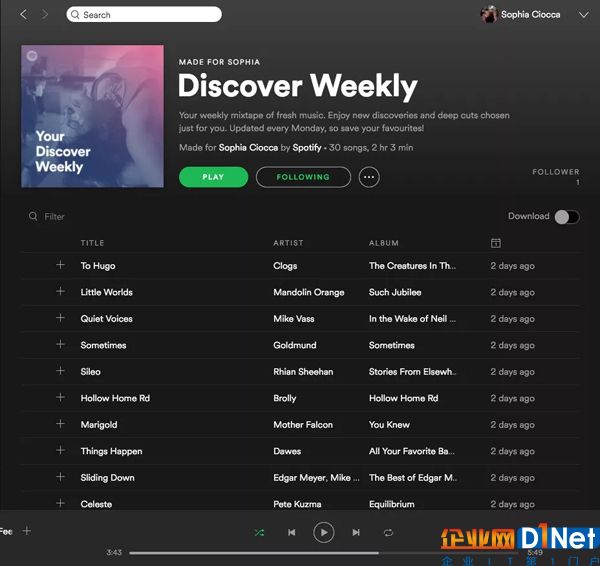
[圖片說明: 我的 Spotify 每周發現歌單]
沒想到,在這方面我不是一個人,不光是我對每周發現如此著迷 – 整個用戶群體都趨之若鶩。這股熱潮使得 Spotify 重新調整了它的重心,并在基于算法的歌單上投入了更多的資源。
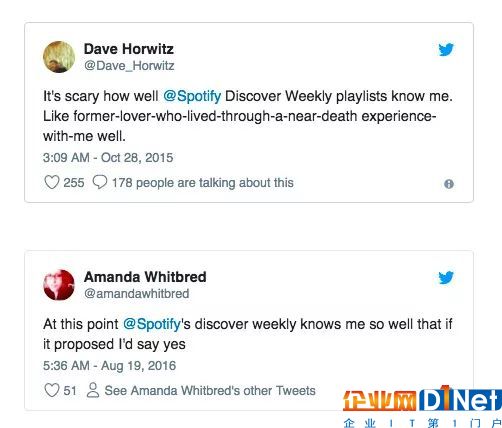
Dave Howitz: @Spotfiy 每周發現的歌單對我的了解程度簡直毛骨悚然,熟悉到就像一個曾經與我有過一起瀕死體驗的前女友一樣。
Amanda Whitbred: 現在 @Spotify 的每周發現對我已經了解到如果它現在求婚,我也會說同意的地步了。
自「每周發現」在 2015 年第一次上線以來,我就迫切想知道它是怎么運作的(而且由于我是 Spotify 公司的迷妹,我喜歡假裝在那里工作并研究他們的產品)。 經過三周的瘋狂Google,我終于滿懷感恩地獲取了一些幕后的知識。
所以 Spotify 到底是如何成功做到給每人每周挑選 30 首歌曲的?我們先來仔細看下其它的音樂服務是如何做音樂推薦,以及 Spotify 是如何更勝一籌的。
在線音樂甄選服務簡史

早在千禧年之初,Songza 就開始使用手動甄選為用戶提供歌單。手動甄選的意思就是所謂的音樂專家或者其他編輯會手動挑選一些他們自己認為不錯的音樂做成歌單,然后聽眾可以直接拿來聽。(稍后,Beats 音樂也采取了同樣的策略)。手動甄選效果尚可,但是由于這種方法只是純手工挑選,方式方法也比較簡單,它并不能照顧到每個聽眾音樂品味的微妙差異。
跟 Songza 一樣, Pandora 也是音樂甄選服務領域的早期玩家之一。它使用了一個略為更高級的方法來代替給歌曲屬性手工打標簽。即大眾在聽音樂的時候,對每首歌曲挑選一些描述性的詞語來作為標簽。進而,Pandora 的程序可以直接過濾特定的標簽來生成包含相似歌曲的歌單。
差不多同一時間,一個隸屬于麻省理工學院媒體實驗室的名叫 The Echo Nest 的音樂信息機構,采用了一個完全不同的高級策略來定制音樂。The Echo Nest 使用算法來分析音頻和音樂的文本內容,以完成音樂識別,個性化推薦,歌單創建和分析等。
最后,是 Last.fm 另辟蹊徑,采取了另一個沿用至今的策略。那就是利用協同過濾來識別用戶可能喜歡的音樂。稍后本文會展開討論更多這方面的內容。
所以說既然其他的音樂甄選服務都實現了推薦功能,Spotify 究竟是怎么操作自己的神奇引擎,來實現甩出競爭對手幾條街的用戶品味默契度的呢?
Spotify 的三種推薦模型
事實上 Spotify 并沒有使用什么單一的革命性推薦模型,而是混合了一些其他公司使用的最好的策略來創建他們自己獨一無二的強大發現引擎。
Spotify 使用三種主要的推薦模型來創建每周發現:
- 協同過濾模型(即 Last.fm 最早使用的那些模型)。工作原理為分析你和其他用戶的行為。
- 自然語言處理(NLP)模型 。工作原理為分析文本。
- 音頻模型。工作原理為分析原始音頻聲道本身。
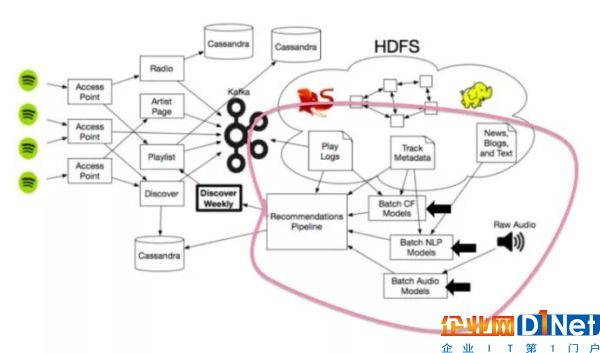
我們來具體看下這些推薦模型是怎么工作的!
推薦模型之一:協同過濾

首先介紹下背景:當很多人聽到協同過濾這幾個詞的時候,他們會立刻聯想到 Netflix,因為它是第一個利用協同過濾來實現推薦模型的公司之一。其做法主要是使用用戶提交的電影星級來計算推薦那些電影給其他類似的用戶。
自 Netflix 將其成功應用以來,協同過濾開始快速流傳開來。現在無論是誰想實現一個推薦模型的話,一般都會拿它作為初次嘗試。
與Netflix不同的是,Spotify 并沒有用戶對他們音樂的星級評價數據。Spotify 所用的數據是隱形反饋的,具體來說就是我們在線聽歌的歌曲次數,以及其他額外信息,諸如用戶是否保存歌曲到個人歌單,或者聽完歌曲后是否接著訪問藝術家主頁等。
但什么是協同過濾,到底它是如何工作的呢?下面用一段簡短對話來做一個大致的介紹。

啥情況? 原來這倆人里面每人都有自己的一些歌曲偏好 – 左邊的人喜歡歌曲 P, Q, R 和 S; 右邊的人喜歡 Q, R, S 和 T。
協同過濾系統進而利用這些數據得出結論,
“嗯。既然你倆都喜歡相同的歌曲 – Q,R 和 S – 那么你們可能是類似的用戶。所以你們應該會喜歡另一個人聽過但是你還沒有聽過的歌曲。”
系統然后建議右邊的人去體驗下歌曲 P,以及左邊的人去體驗下歌曲 T。聽起來夠簡單吧?
但是 Spotify 具體是怎么具體應用這個概念,來計算基于百萬級的用戶偏好從而得出數以百萬計的用戶歌曲推薦呢?
…矩陣運算,用 Python 庫即可實現
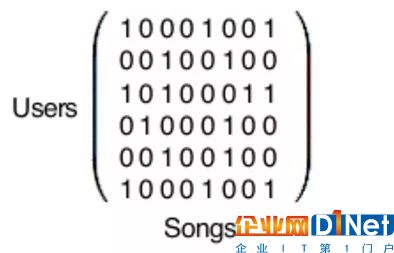
現實中,此處提及的矩陣是極其龐大的。每行都代表了 Spotify 的一億四千萬用戶中的一員(如果你也用 Spotify,那么你也是這個矩陣中的一行),而每一列則代表了 Spotify 數據庫中三億首歌曲中的一首。
然后,Python 庫就開始跑這個漫長而復雜的矩陣分解公式:
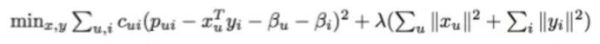
計算完成后,系統會生成兩種類型的向量,在此分別命名為 X 和 Y。X 為用戶向量,代表單個用戶的音樂品味。Y 則為歌曲向量,代表單支歌曲的特征。
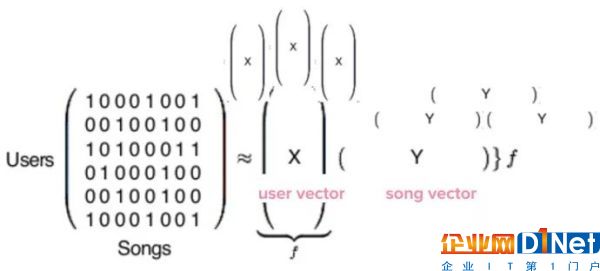
現在我們得到了一億四千萬個用戶向量,每人一個,還有三億歌曲向量。這些向量的具體內容只是一些單獨拎出來自身并無意義的數字,但是在后面進行比較時會非常有用。
為了找到那些跟我相似品味的用戶,協同過濾系統會拿我的向量跟其他用戶的向量作比較,最終會找到那些跟我最相似的用戶。對于 Y 向量,也是同樣的流程 – 你可以拿一首歌的向量與其他的歌曲向量做比較,進而找出哪些歌曲是跟你現在正在看的歌曲最相似。
協同過濾確實效果不錯,但是 Spotify 深知再添加另外一個引擎的話效果會更出色。這就到了自然語言處理出場的時候了。
推薦模型之二:自然語言處理
Spotify 采用的第二個推薦模型就是自然語言處理。這些模型的源數據,正如名字所示,就是一些普通的語言文字 – 例如歌曲的元數據,新聞文章,博客,和互聯網上的其它文本等。

自然語言處理 – 計算機理解人類語言的能力 – 本身就是一個巨大的領域,通常通過情感分析應用編程接口(API)來進行操作處理。
自然語言處理背后的具體原理超出了本文的討論范疇,但是在此本文可以提供一些粗略的描述:Spotify 會在網上不斷爬取博客帖子以及其它音樂相關的文本,并找出人們對特定的藝術家和歌曲的評論 – 比如說人們對這些歌曲經常使用哪些形容詞和語言, 以及哪些其他藝術家和歌曲也會和它們放在一起討論。
雖然我不知道 Spotify 如何處理他們抓取的數據,但是我可以介紹下 The Echo Nest 是如何使用它們的。他們會把數據分類成“文化向量”和“最佳評語集”。每個藝術家和歌曲都有數以千計的每日更新的最佳評語集。每個評語都有一個相關的權重,來表示其描述的重要性(簡單說就是某人可能會用該評語描述某個音樂的概率)。
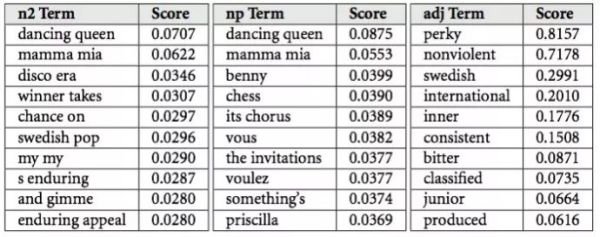
[ “Cultural vectors”, or “top terms”, as used by the Echo Nest. Table from Brian Whitman]
然后,與協同過濾類似,自然語言處理模型用這些評語和權重來創建一個歌曲的表達向量,可以用來確定兩首音樂是否相似。很酷吧?
推薦模型之三:原始音頻模型
首先,你可能會問這個問題:
但是,Sophia,我們已經從前兩種模型中獲取了這么多數據!為什么還要繼續分析音頻本身呢?
額,首先要說的是,引入第三個模型會進一步提高這個已經很優秀的推薦服務的準確性。但實際上,采用這個模型還有另外一個次要目的:原始音頻模型會把新歌考慮進來。
比如說,你的創作歌手朋友在 Spotify 上剛放上了一首新歌。可能它只有 50 次聽歌記錄,所以很少能有其他聽眾來一起協同過濾它。與此同時,它也在網上也沒有留下多少痕跡,所以自然語言處理模型也不會注意到它。幸運的是,原始音頻模型并不區分新歌曲和熱門歌曲。所以有了它的幫忙,你朋友的歌曲也可以和流行歌曲一道出現在每周發現的歌單里面。
好了,到了“如何”的部分了。我們如何才能分析這些看起來如此抽象的原始音頻數據呢?
…用卷積神經網絡!
卷積神經網絡同樣也是支撐面部識別的技術。只不過在 Spotify 的案例中,他們被稍作修改以基于音頻數據處理而不是像素點。下面是一個神經網絡架構的例子:
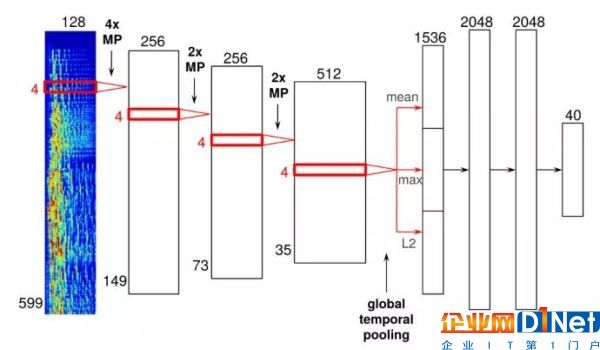
[Image credit: Sander Dieleman]
這個特定的神經網絡有四個卷積層,具體為圖中左側的寬柱,和右邊的稍微窄些的三根柱。輸入是音頻幀的時頻表示,進而連接起來形成頻譜圖。
音頻幀會穿過這些卷積層,經過最后一個卷積層,你可以看到一個“全局臨時池”層。該層在整個時間軸上匯集數據,并有效計算和統計歌曲時長內的學習特征。
處理完之后,神經網絡會得出其對歌曲的理解,包括估計的時間簽名,音調,調式,拍子及音量等特征。下面就是 Draft Punk 的 “Around the World” 30 秒片段的數據圖。
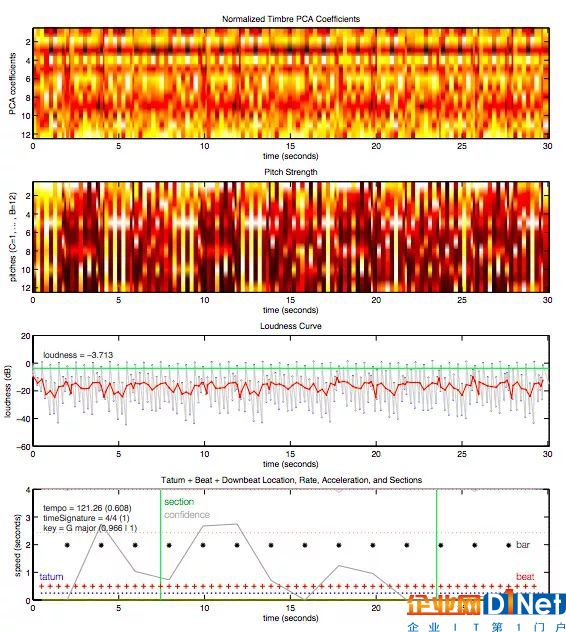
[Image Credit: Tristan Jehan & David DesRoches (The Echo Nest)]
最終,對這些對歌曲關鍵特征的理解可以讓 Spotify 來決定歌曲之間的相似度,以及根據用戶聽歌歷史來判斷哪些用戶可能會喜歡它們。
這些基本涵蓋了為每周發現提供支持的推薦作業流程所依賴的三種主要模型。
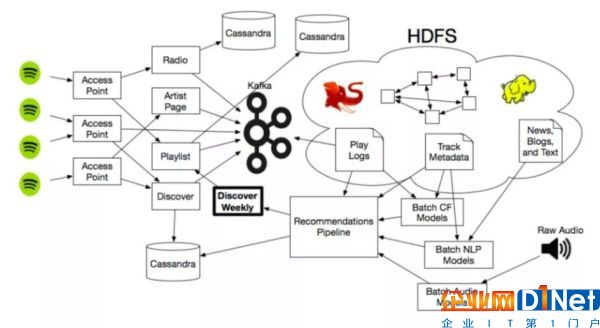
[ Cassandra instances]
當然了,這些推薦模型也和 Spotify 其它更大的生態系統連接在一起,其中包括利用海量的數據存儲以及非常多的 Hadoop 集群來做推薦服務的擴展,使得引擎得以計算巨型矩陣,無窮無盡的互聯網音樂文章和大量的音頻文件。
我希望本文可以對你有所啟發,并且像當時它對我一樣能夠激起你的好奇。懷著對幕后的機器學習技術的了解和感激之情,現在我將通過我自己的每周發現來尋找我喜歡的音樂。








 京公網安備 11010502049343號
京公網安備 11010502049343號