


一位谷歌的工程經理呼吁采用新的人工智能架構,包括一種保護數據隱私的分布式方法。在他的演講之后,在ISSCC(國際固態電路會議)上,有超過六篇學術論文描述了機器學習的新方法。
幾篇ISSCC論文將計算和存儲合并起來,這是一種長期以來追求的研究思想,一些人認為機器學習最終可以帶來廣泛的商業用途。就谷歌而言,該公司正在探索一種混合方法,讓最終用戶保留他們的數據,只是將神經網絡權重發送到云中的參數服務器進行處理。
最終,谷歌及其同行需要在計算能力方面實現巨大突破,才能實現人工智能在其數據中心的前景。Olivier Temam是這家搜索巨頭一項未指明的人工智能計劃的經理,Temam表示,機器學習支持的谷歌圖片搜索完成一個任務的一個循環就需要110億次/秒的操作
Temam呼吁采用分布式的方法,這樣邊緣設備和云服務可以協作訓練神經網絡。設備在本地使用原始數據進行一些訓練,然后將他稱為語義數據的更改或神經網絡權重發送到云端,神經網絡模型在其中會進一步訓練和完善。
Temam表示:“出于非常容易理解的原因,人們或公司不想將他們的數據發送到云端,所以我們已經表明可以創建聯合學習的模型。”
一位觀察者指出,這種方法可能會吸引黑客試圖從語義數據中推斷出原始數據。
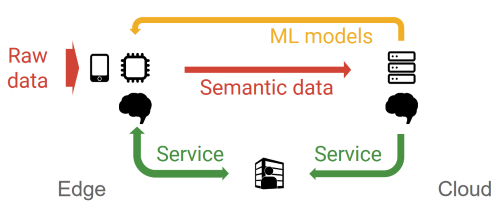
谷歌呼吁邊緣設備和云服務合作進行神經網絡培訓
谷歌同意在這里向數百名芯片設計師發表演講,希望能為更強大的人工智能加速器產生新的點子。設計這種芯片的一個挑戰是處理器和神經網絡需要的大量內存之間的瓶頸。
搜索巨頭需要的內存帶寬在100TB/秒的范圍。Temam表示,今天的高帶寬存儲器堆棧的速度慢了兩個數量級,而SRAM則太過昂貴而且非常耗電。
一些學者描述了將計算嵌入到內存中的方法。由于各種專用存儲器——包括記憶電阻、ReRAM等——的興起,以及有時會使用大容量存儲器或者模擬陣列的、受到大腦啟發的計算機設計的影響,這一領域目前非常熱門。
麻省理工學院副教授Vivienne Sze在2016年與人合著了一篇關于Eyeriss架構的論文,該架構可以解決這個問題。Vivienne Sze表示:“我們發現神經網絡絕大部分能量都耗費在數據移動之中。”她表示:“你需要管理大量的數據和權重,所以數據移動消耗掉的能源比計算還要多。”
她在麻省理工學院的小組現在正在研究的靈活架構可以運行越來越多種類的神經網絡,包括開始出現的許多簡化。他們還在探索在機器人和無人機相機等應用上單位功率可以完成多少神經網絡加速。
谷歌的Temam表示,只要實用而且成本低廉,該公司就可以接受所有新想法。Temam表示:“我們希望不斷降低成本,以便更大規模地部署,并最終實現最佳性能。”
后面的幾頁扼要介紹了六篇關于人工智能加速器的ISSCC論文。其中大部分論文的目標都是降低推理工作的能耗,其中有一些支持一些培訓工作。
使用TSV和電感耦合來堆疊SRAM
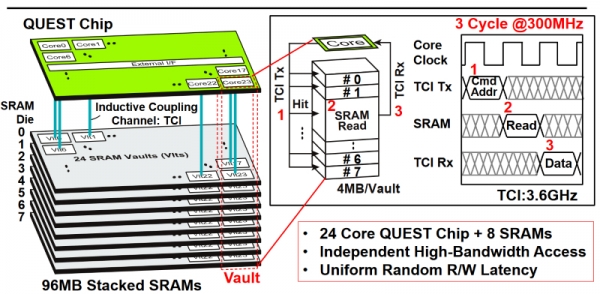
來自日本兩所大學的Quest處理器使用通孔過孔和電感耦合將八個層中的96 MB SRAM堆疊起來。另外,它的24個內核每一個都有自己專用的4Mb的SRAM緩存。
韓國加速1到16位的CNN和RNNs
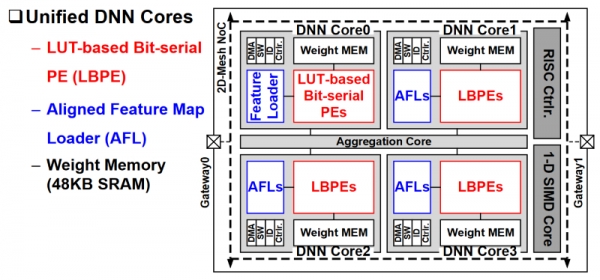
KAIST的研究人員為卷積和遞歸網絡設計了一種加速器,分辨率為1至16位。它使用了均衡功能加載器(AFL),最大限度地減少了對片外存儲訪問的需求。
神經網絡分類器采用了SRAM陣列
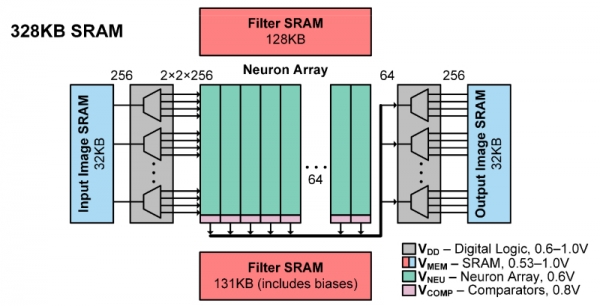
斯坦福大學和Imec的研究人員描述了一款28-nm分類器,芯片上包含了所有必需的存儲器。它能夠以中等的準確度,以每個任務3.79微焦的能耗處理任務,能做到這一點,部分的原因是針對卷積網絡使用了約束BinaryNet算法。
SRAMs 存儲權重,而ADCs負責計算它們
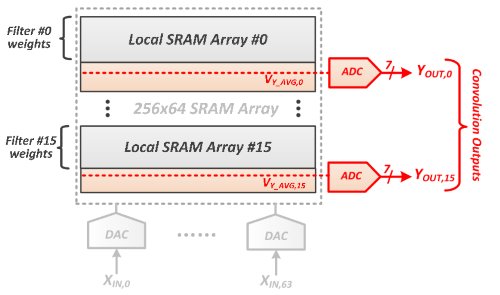
麻省理工學院的研究人員將神經網絡權重存儲在SRAM陣列中,以消除外部存儲器非常耗電的讀取操作。每個陣列上的模數轉換器計算部分卷積。
低功耗陣列處理推理,培訓
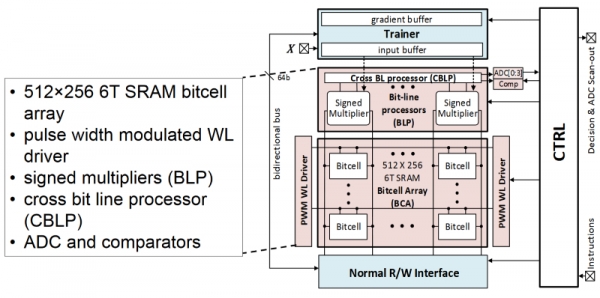
伊利諾斯大學的內存中分類器達到了42皮焦耳/決定。其SRAM陣列具有推理和訓練模式。
碳納米管遇到電阻式RAM單元
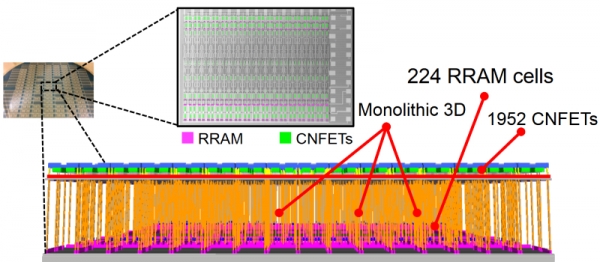
伯克利、麻省理工學院和斯坦福大學的一批資深研究人員使盡渾身解數,采用整體3D工藝創造了一種基于1952個碳納米管FET和224個電阻式RAM單元的新型器件。這個所謂的超維計算納米系統處理語言翻譯任務的準確率達到了98%。








 京公網安備 11010502049343號
京公網安備 11010502049343號