


背景:今日, NVIDIA宣布要收購對象存儲SwiftStack。

正文:
每當看到人工智能(也即AI),我們通常會想到機器人、自動化、圖像語音或視頻識別、算法等高大上的黑科技。而對象存儲則給人一種低調、海量的感覺。是什么原因,讓這兩者相遇,并擦出了火花?
什么是對象存儲?
對象存儲是自包含、自愈合的智能存儲設備,具有容量大、速度快、擴展靈活的特點。每一個對象除了存放數據本身之外,還存放了唯一標識符和數據的元信息,例如創建的日期和時間,屬主,大小,索引,保留周期,QoS等。對象本身使得數據的組織得到了簡化,避免了傳統存儲文件目錄樹形結構的復雜。對象的存放是扁平化地方式保存在bucket(桶)中的,變得更簡單。而且對象的元信息,也方便了檢索。
拿生活中常見的例子來比喻,當圖書館購進新的紙質書籍需要存放時,需要按照圖書分類法(按照圖書的內容、形式、體裁和讀者用途等進行分類),清楚地知道大類、子類和更詳細的分類,才能找到合適的位置上架。文件存儲的數據存放就類似圖書分門別類地存放,如下圖。

類比:文件存儲的數據存放方式就像圖書分類
當我們逛超市需要存包的時候,盡管有那么多儲物柜,但是大家都覺得存取包很簡單。存的時候,按一下存包按鍵,啪的一聲,一個柜子打開,同時你會得到包含二維碼的紙條,你把包放到柜子里,但是不用記住柜子的位置和編號,瀟灑的離開。當你取包的時候,你刷一下二維碼,也是啪的一聲,放包的柜子自動打開,所存物品唾手可得。對象存儲的數據存放方式就和超市存取包很類似,存儲對象的唯一標識符就相當于那個二維碼。

類比:對象存儲的數據存放方式就像超市存包
下圖是對象存儲的一些特點。
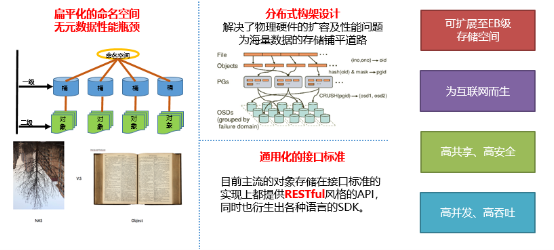
對象存儲特點
不過,我們需要注意的是,文件存儲和對象存儲有著各自適用的場景。下圖列出了分布式文件存儲和分布式對象存儲的區別:

分布式文件存儲與分布式對象存儲的區別
當文件數量級過億的時候,文件目錄樹形結構會對數據的讀寫造成巨大的挑戰,例如在linux中如果用ls查看文件,可能都要等待幾十分鐘以上。但是,量級沒有如此之大時,因為過去的使用習慣,以及相對成熟的生態,使用文件存儲還是不錯的選擇。
如何避免錯誤理解對象存儲
當我們談對象存儲時,需要注意討論的是存儲接口,還是內部數據組織形式。
1)實際上,討論對象存儲大多數是指存儲接口,是否支持RestFul或S3,也即對象接口的形式來訪問存儲空間。
2)少數情況下,對象存儲指存儲設備的內部數據組織形式。在數據猛增的背景下,越來越多的存儲設備內部采用對象存儲的這種內部數據組織形式。例如VMware vSAN,其實是是一種基于服務器端存儲的共享分布式對象存儲系統,只不過存儲接口主要采用的是SCSI方式;或者具備高可靠、高性能、高安全和易管理的浪潮AS13000,如下圖。
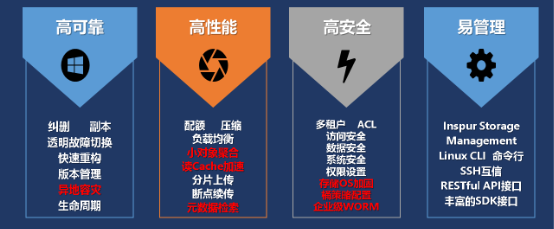
浪潮AS13000G5的對象存儲功能
AI與對象存儲
在許多人的印象中,AI需要大量的算力,是計算密集型的典型應用。而對象存儲大多時候用于海量非結構化數據的存放,備份歸檔,云存儲、企業云盤、文檔影像或視頻的存儲等。從存儲特征來看,對象存儲的延遲可能較難滿足AI的性能需求;從使用習慣來看,大多數AI用戶都是采用文件接口。
實際上,有計算,就會有存儲,只是或多或少,或快或慢,或過渡或長期保存的區別。
在微信公眾號浪潮存儲《2020:下一個十年,存儲發展的趨勢是什么》上篇也即鑒往事篇 一文中,曾提到:
AI所需存儲,可以分為準備、訓練、推理和歸檔等階段,每個階段的IO特征不一樣,對于存儲的要求也不一樣。例如,在推理階段,IO的特征是讀寫混合,并且要求存儲的延時低,能快速響應。
下圖列出了AI各個階段的IO特征,及其對存儲的要求。
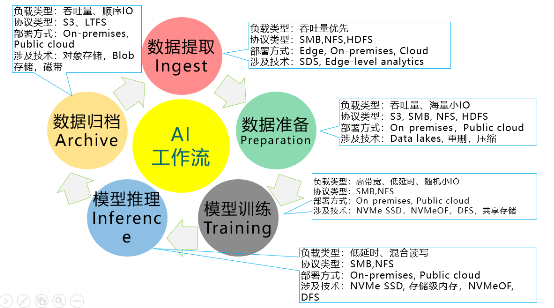
AI各個階段的IO特征及存儲需求
綜合考慮用戶使用習慣、性價比、性能和容量,如果能夠取得一個平衡的話,對象存儲能夠用在AI的多個不同階段中,如提取、準備、訓練、歸檔等。
NVIDIA收購SwiftStack用來做什么呢?
首先,我們來看一下做為事實上的標準的AWS S3,從骨子里說,它代表的對象存儲,是一種在線的海量數據較低成本的存儲方式,適合跨地域讀寫;因此,雖然備份歸檔是對象存儲的使用場景之一,但只是做備份歸檔,其實是委屈了對象存儲。
其次,對象存儲的高并發,特別適合前端呈現分布式負載的場景。AI場景的使用,包括AI訓練、AI推理,是由許許多多個任務并發進行的,任務與任務之間幾乎沒有數據的交互,因此很少考慮存儲通常要顧及的寫一致性。
因此,在我們看來,NVIDIA收購SwiftStack或許有如下幾個原因:
1)NVIDIA欲整合AI基礎架構
NVIDIA是一個非常注重生態的公司,它的版圖里應該不僅僅是計算以及衍生出來的各個組件,從近兩年的動作來看,NVIDIA想整合整個AI基礎架構。2019年3月11日NVIDIA以69億美元收購 Mellanox;2020年3月6日宣布收購SwiftStack。
2)SwiftStack具備數據跨云管理和高并發的優勢
據報道:"Manuvir Das表示,NVIDIA尤其喜歡SwiftStack的1space技術,該技術可以為忙于處理緩存和分層等任務的GPU助一臂之力。
SwiftStack V7于2019年發布,提供數PB的規模,可處理數千個worker節點同時訪問數據的任務。它提供了超過100GB /秒的吞吐速度,性能和容量都能實現線性擴展。
1space是NVIDIA收購Swiftstack的主要原因,這是一種文件連接件,使云原生應用程序可以通過S3或Swift對象API訪問本地數據或AWS數據,并可以確保不斷向數據提供計算資源”
我個人認為,AI訓練有個特點,它一次性將原始訓練集的數據加載到計算節點的內存或者SSD后,需要經過一段較長的時間(也即計算或說訓練),才會再次讀取存儲上的數據。因此,對象存儲的延遲可能不會構成障礙,這一點可以通過高并發來彌補。
3)還可將SwiftStack用于數據提取,或者數據歸檔階段。海量的數據,采用對象存儲是一個不錯的選擇。
4)維護原有使用習慣
NVIDIA內部大量使用SwiftStack來存儲數據,幾年下來,習慣已經養成,而且猜測數據量也非常龐大。通過收購SwiftStack,以免未來受人制肘,也是有可能的。
無論如何,對象存儲在云計算和AI迅猛普及的情況下,一定會迎來它的春天。IDC中國SDS市場數據顯示,2019年對象存儲增長率55.3%,是中國軟件定義存儲市場里增速最快的細分領域。
在中國的對象存儲市場中,浪潮的AS13000做出了貢獻。2019年,AS13000對象存儲成功地在某銀行(國內排名前15)總行的影像系統中部署,并實現了同城容災功能。如下圖所示:
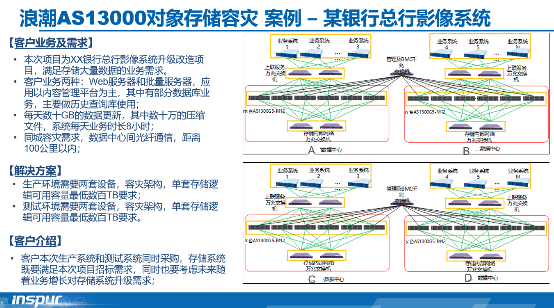
浪潮AS13000對象存儲的實際案例
浪潮分布式存儲在不斷迭代的過程中,除了前面提到的同城容災之外,還開發了大量的其他高級特性。一是小對象聚合。浪潮對象存儲針對海量小文件場景,通過小對象聚合,節約HDD的磁盤IO,提升存儲效率。二是讀Cache加速。在卡口圖片、AI計算場景,通過讀Cache加速提升數據讀取效率。三是元數據檢索。在存儲系統內集成索引引擎,實現根據對象元數據多條件模糊檢索對象的技術,有效地提升了海量非結構化數據中“大海撈針”的效率。四是企業級WORM,滿足企業客戶數據的法規性要求,結合應用特點,靈活設置寬限期和保護期。此外,還有存儲OS加固、桶策略配置等等。
展望未來
受“新冠疫情”影響,在線化、數字化、分散化、自動化等新形態新模式,也對AI、大數據中心(含計算、存儲、網絡和安全)等的發展提出了迫切的需求。
疫情趨勢預測、風險預警、醫療資源和物質的預測和調配,要做到快速、準確、科學的判斷,需要和AI結合。
另外,非接觸的服務和工作、自動化、快速分析決策和響應的需求等,將會爆發。例如,人臉識別(包括免摘口罩的人臉識別)、AI輔助診斷、應急管理、安防監控、知識圖譜、基因研究、醫藥研發、金融服務、智能配送、各行各業的無人值守(例如零售)、物流運輸、個人畫像、軌跡追蹤、輿情分析等等。
我們相信,作為新基建的一部分,包含AI和存儲在內的信息基礎設施將迎來更好更快的發展。








 京公網安備 11010502049343號
京公網安備 11010502049343號