


簡介
我們看到的大多數深度學習應用程序通常面向市場、銷售、金融等領域,但在使用深度學習來保護這些領域的產品和業務、避免惡意軟件和黑客攻擊方面,則鮮有文章或資源。
像谷歌、臉譜、微軟和SalesForce這樣的大型科技公司已經將深度學習嵌入他們的產品之中,但網絡安全行業仍在迎頭趕上。這是一個具有挑戰性的領域,需要我們全力關注。
本文中,我們簡要介紹深度學習(Deep Learning,DL)以及它支持的一些現有信息安全(此處稱為InfoSec)應用。然后,我們深入研究匿名TOR流量檢測這個有趣的問題,并提出一個基于深度學習的TOR流量檢測方案。
本文的目標讀者是已經從事機器學習項目的數據科學專業人員。本文內容假設您具備機器學習的基礎知識,而且當前是深度學習和其應用案例的初學者或探索者。
為了能夠充分理解本文,強烈推薦預讀以下兩篇文章:
《使用數據科學解開信息安全的神秘面紗》
《深度學習的基礎知識-激活功能以及何時使用它們》
目錄
一、信息安全領域中深度學習系統的現狀
二、前饋神經網絡概述
三、案例研究:使用深度學習檢測TOR流量
四、數據實驗-TOR流量檢測
一、信息安全領域中深度學習系統的現狀
深度學習不是解決所有信息安全問題的“靈丹妙藥”,因為它需要廣泛的標注數據集。不幸的是,沒有這樣的標記數據集可供使用。但是,有幾個深度學習網絡對現有解決方案做出重大改進的信息安全案例。惡意軟件檢測和網絡入侵檢測恰是兩個這樣的領域,深度學習已經顯示出比基于規則和經典機器學習的解決方案有更顯著的改進。
網絡入侵檢測系統通常是基于規則和簽名的控件,它們部署在外圍以檢測已知威脅。攻擊者改變惡意軟件簽名,就可以輕易地避開傳統的網絡入侵檢測系統。Quamar等[1]在他們的IEEE學報論文中指出,有望采用自學的基于深度學習的系統來檢測未知的網絡入侵。基于深度神經網絡的系統已經用來解決傳統安全應用問題,例如檢測惡意軟件和間諜軟件[2]。
與傳統的機器學習方法相比,基于深度學習的技術的泛化能力更好。Jung等[3]基于深度學習的系統甚至可以檢測零日惡意軟件。畢業于巴塞羅那大學的Daniel已經做了大量有關CNN(Convolutional Neural Networks,卷積神經網絡)和惡意軟件檢測的工作。他在博士論文中提及,CNNs甚至可以檢測變形惡意軟件。
現在,基于深度學習的神經網絡正在用戶和實體行為分析(User and Entity Behaviour Analytics,UEBA)中使用。傳統上,UEBA采用異常檢測和機器學習算法。這些算法提取安全事件以分析和基線化企業IT環境中的每一個用戶和網絡元素。任何偏離基線的重大偏差都會被觸發為異常,進一步引發安全分析師調查警報。UEBA強化了內部威脅的檢測,盡管程度有限。
現在,基于深度學習的系統被用來檢測許多其他類型的異常。波蘭華沙大學的Pawel Kobojek[4]使用擊鍵動力學來驗證用戶是否使用LSTM網絡。Capital one安全數據工程總監JasonTrost 發表了幾篇博客[5],其中包含一系列有關深度學習在InfoSec應用的技術論文和演講。
二、前饋神經網絡概述
人工神經網絡的靈感來自生物神經網絡。神經元是生物神經系統的基本單元。每一個神經元由樹突、細胞核和軸突組成。它通過樹突接收信號,并通過軸突進行傳遞(圖1)。計算在核中進行。整個網絡由一系列神經元組成。
AI研究人員借用這個原理設計出人工神經網絡(Artificial Neural Network,ANN)。在這樣的設置下,每個神經元完成三個動作:
它收集來自其他不同神經元的輸入或者經過加權處理的輸入
它對所有的輸入進行求和
基于求和值,它調用激活函數
因此,每個神經元可以把一組輸入歸為一類或者其他類。當僅使用單個神經元時,這種能力會受到限制。但是,使用一組神經元足以使其成為分類和序列標記任務的強大機制。
圖1:我們能獲得的最大靈感來自大自然——圖中描繪了一個生物神經元和一個人工神經元可以使用神經元層來構建神經網絡。網絡需要實現的目標不同,其架構也是不同的。常見的網絡架構是前饋神經網絡(Feed ForWard Neural Network,FFN)。神經元在無環的情況下線性排列,形成FFN。因為信息在網絡內部向前傳播,它被稱為前饋。信息首先經過輸入神經元層,然后經過隱藏神經元層和輸出神經元層(圖2)。
圖2:具有兩個隱藏層的前饋網絡與任何監督學習模型一樣,FFN需要使用標記的數據進行訓練。訓練的形式是通過減少輸出值和真值之間的誤差來優化參數。要優化的一個重要參數是每個神經元賦予其每個輸入信號的權重。對于單個神經元來說,使用權重可以很容易地計算出誤差。
然而,在多層中調整一組神經元時,基于輸出層算出的誤差來優化多層中神經元的權重是具有挑戰性的。反向傳播算法有助于解決這個問題[6]。反向傳播是一項舊技術,屬于計算機代數的分支。這里,自動微分法用來計算梯度。網絡中計算權重的時候需要用到梯度。
在FFN中,基于每個連接神經元的激活獲得結果。誤差逐層傳播。基于輸出與最終結果的正確性,計算誤差。接著,將此誤差反向傳播,以修正內部神經元的誤差。對于每個數據實例來說,參數是經過多次迭代優化出來的。
三、案例研究:使用深度學習檢測TOR流量
網絡攻擊的主要目的是竊取企業用戶數據、銷售數據、知識產權文件、源代碼和軟件秘鑰。攻擊者使用加密流量將被盜數據混夾在常規流量中,傳輸到遠程服務器上。
大多數經常攻擊的攻擊者使用匿名網絡,使得安全保護人員難以跟蹤流量。此外,被盜數據通常是加密的,這使得基于規則的網絡入侵工具和防火墻失效。最近,匿名網絡以勒索軟件/惡意軟件的變體形式用于C&C。例如,洋蔥勒索[7]使用TOR網絡和其C&C服務器進行通信。
圖3:Alice與目標服務器之間TOR通信的說明。通信開始于Alice向服務器請求一個地址。TOR網絡給出AES加密的路徑。路徑的隨機化發生在TOR網絡內部。包的加密路徑用紅色顯示。當到達TOR網絡的出口節點時,將簡單分組轉發給服務器。出口節點是TOR網絡的外圍節點。
匿名網絡/流量可以通過多種方式完成,它們大體可分為:
基于網絡(TOR,I2P,Freenet)
基于自定義系統(子圖操作系統,Freepto)
其中,TOR是比較流行的選擇之一。TOR是一款免費軟件,能夠通過稱為洋蔥路由協議的專用路由協議在互聯網上進行匿名通信[9]。該協議依賴于重定向全球范圍內多個免費托管中繼的互聯網流量。在中繼期間,就像洋蔥皮的層一樣,每個HTTP包使用接收器的公鑰加密。
在每個接收點,使用私鑰對數據包進行解密。解密后,下一個目標中繼地址就會披露出來。這個過程會持續下去,直到找到TOR網絡的出口節點為止。在這里數據包解密結束,一個簡單的HTTP數據包會被轉發到原始目標服務器。在圖3中展示了Alice和服務器之間的一個示例路由方案。
啟動TOR最初的目的是保護用戶隱私。但是,攻擊者卻用它代替其他不法方式,來威逼善良的人。截至2016年,約有20%的TOR流量涉及非法活動。在企業網絡中,通過不允許安裝TOR客戶端或者攔截保護或入口節點的IP地址來屏蔽TOR流量。
不管怎樣,有許多手段可以讓攻擊者和惡意軟件訪問TOR網絡以傳輸數據和信息。IP攔截策略不是一個合理的策略。一篇來自Distil網站[5]的自動程序情勢不佳報告顯示,2017年70%的自動攻擊使用多個IP,20%的自動攻擊使用超過100個IP。
可以通過分析流量包來檢測TOR流量。這項分析可以在TOR 節點上進行,也可以在客戶端和入口節點之間進行。分析是在單個數據包流上完成的。每個數據包流構成一個元組,這個元組包括源地址、源端口、目標地址和目標端口。
提取不同時間間隔的網絡流,并對其進行分析。G.He等人在他們的論文“從TOR加密流量中推斷應用類型信息”中提取出突發的流量和方向,以創建HMM(Hidden Markov Model,隱馬爾科夫模型)來檢測可能正在產生那些流量的TOR應用程序。這個領域中大部分主流工作都利用時間特征和其他特征如大小、端口信息來檢測TOR流量。
我們從Habibi等人的“利用時間特征來發現TOR流量的特點”論文中得到啟發,并遵循基于時間的方法提取網絡流,用于本文TOR流量的檢測。但是,我們的架構使用了大量可以獲得的其他元信息,來對流量進行分類。這本質上是由于我們已經選擇使用深度學習架構來解決這個問題。
四、數據實驗-TOR流量檢測
為了完成本文的數據實驗,我們從紐布倫斯威克大學的Habibi Lashkari等人[11]那里獲取了數據。他們的數據由從校園網絡流量分析中提取的特征組成。從數據中提取的元信息如下表所示:
圖4:本文使用的數據集實例請注意,源IP/端口、目標IP/端口和協議字段已經從實例中刪除,因為它們會導致模型過擬合。我們使用具有N隱藏層的深度前饋神經網絡來處理其他所有特征。神經網絡的架構如圖5所示。
圖5:用于Tor流量檢測的深度學習網絡表示隱藏層層數在2和10之間變化。當N=5時是最優的。為了激活,線性整流函數(Rectified Linear Unit, ReLU)用于所有隱藏層。隱藏層每一層實際上都是密集的,有100個維度。
Keras中的FFN的Python代碼片段:
model = Sequential()
model.add(Dense(feature_dim, input_dim= feature_dim, kernel_initializer='normal', activation='relu'))
for _ in range(0, hidden_layers-1):
model.add(Dense(neurons_num, kernel_initializer='normal', activation='relu'))
model.add(Dense(1,kernel_initializer='normal', activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=["accuracy"])
輸出節點由Sigmoid函數激活。這被用來輸出二分類結果-TOR或非TOR。
我們在后端使用帶有TensorFlow的Keras來訓練深度學習模塊。使用二元交叉熵損失來優化FFN。模型會被訓練不同次數。圖7顯示,在一輪仿真訓練中,隨著訓練次數的增加,性能也在增加,損失值也在下降。
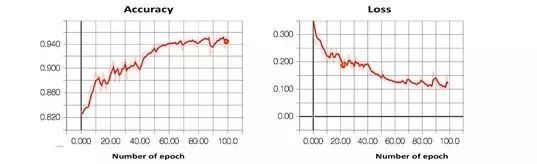
圖7:網絡訓練過程中Tensorboard生成的靜態圖我們將深度學習系統的結果與其他預測系統進行了比較。使用召回率(Recall)、精準率(Precision)和F-Score這些標準分類指標來衡量預測系統性能。我們基于深度學習的系統能夠很好地檢測TOR類。但是,我們更加重視非TOR類。可以看出,基于深度學習的系統可以減少非TOR類的假陽性情況。結果如下表:
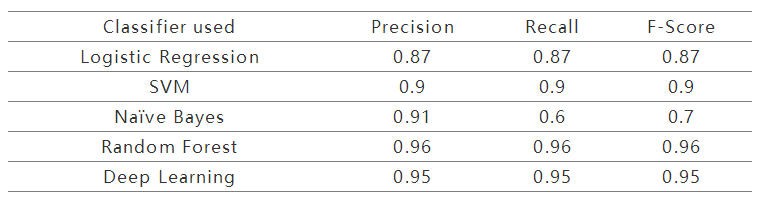
表2:用于TOR流量檢測實驗的深度學習和機器學習模型結果在各種分類器中,隨機森林和基于深度學習的方法比其他方法更好。所示結果基于5,500個訓練實例。本實驗中使用數據集的大小相對小于典型的基于深度學習的系統。隨著訓練數據的增加,基于深度學習的系統和隨機森林分類器的性能將會進一步提升。
但是,對于大型數據集來說,基于深度學習的分類器通常優于其他分類器,并且可以針對相似類型的應用程序進行推廣。例如,如果需要訓練檢測使用TOR的應用程序,那么只需要重新訓練輸出層,并且其他所有層可以保持不變。而其他機器學習分類器則需要在整個數據集上重新訓練。請記住,對于大型數據集來說,重新訓練模型需要耗費巨大的計算資源。
尾記
每個企業面臨的匿名流量檢測的挑戰是存在細微差別的。攻擊者使用TOR信道以匿名模式偷竊數據。當前流量檢測供應商的方法依賴于攔截TOR網絡的已知入口節點。這不是一個可拓展的方法,而且很容易繞過。一種通用的方法是使用基于深度學習的技術。
本文中,我們提出了一個基于深度學習的系統來檢測TOR流量,具有高召回率和高精準率。請下面的評論部分告訴我們您對當前深度學習狀態的看法,或者如果您有其他替代方法。








 京公網安備 11010502049343號
京公網安備 11010502049343號