


對于大模型的訓練和推理來說,GPU 的選擇至關重要。訓練大型模型時,需要大量的計算能力和顯存支持,因此通常選擇專業級的 GPU 如 NVIDIA H100 或 A100。然而,在推理階段,消費級 GPU 如 NVIDIA RTX 4090 由于其較高的性價比,也可以勝任此任務。

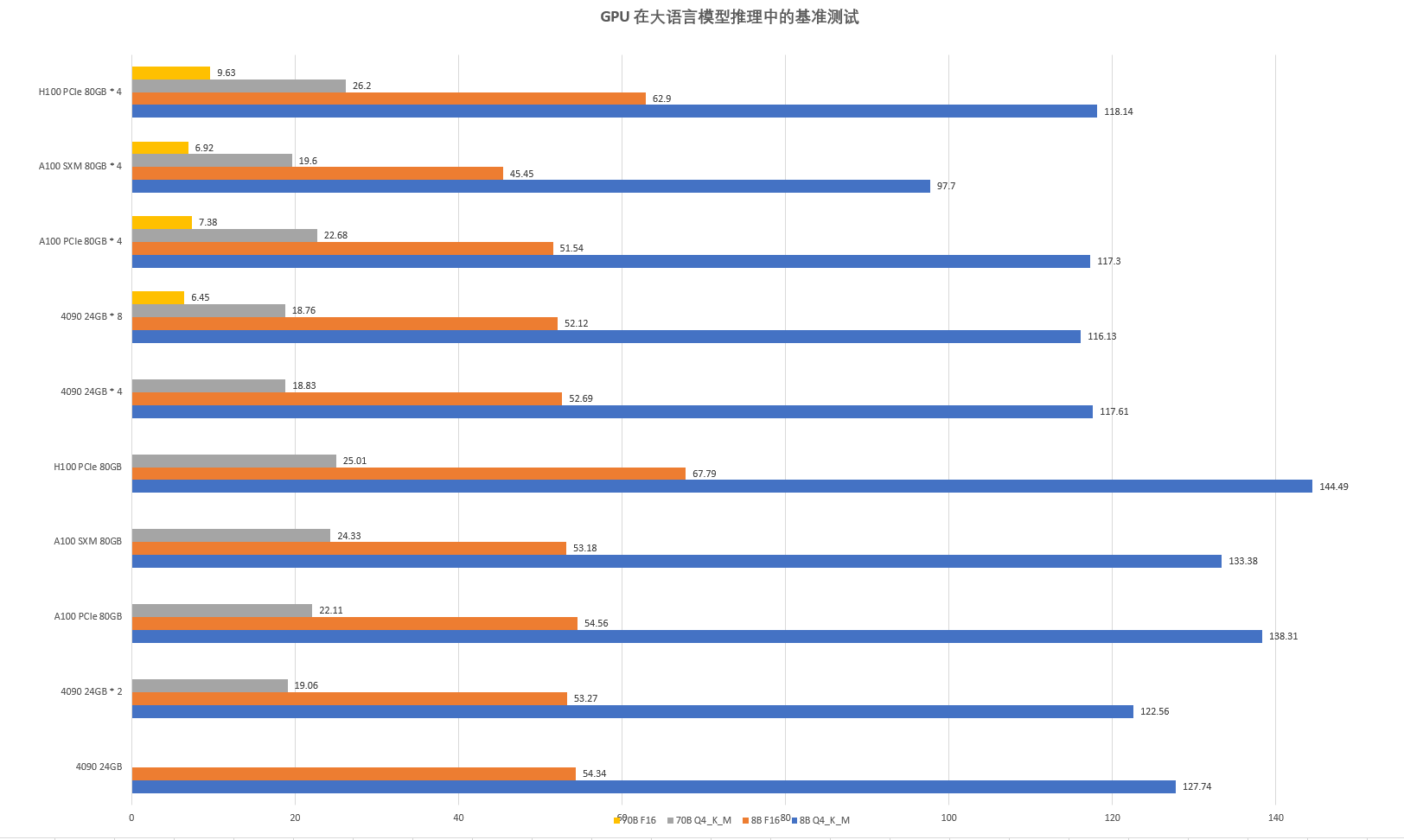
在推理階段,RTX 4090 因其高性價比成為一種可行的選擇。通過下圖GPU在大語言模型推理中的基準測試可以看出,RTX 4090服務器在性能上雖然略遜于H100,但用作推理任務卻完全足夠。主要是因為以下原因:
1.成本低:RTX 4090服務器的價格相對較低,購買和維護成本都比H100要實惠。這意味著在有限的預算下,AIGC以及科研單位可以更好地利用資源,將更多的資金投入到其他重要領域。
2.性能滿足需求:雖然RTX 4090服務器的性能略遜于H100,但在推理任務中,其性能仍然足夠。對于大多數推理任務來說,RTX 4090服務器能夠提供足夠的計算支持,使得推理過程順利進行。
3.適用性廣泛:RTX 4090服務器不僅在推理任務中具有優勢,還能支持其他計算密集型任務,如數據分析和處理等。這意味著科研所可以在多個領域充分利用這一服務器,從而提高設備的利用率。
在推理任務中,內存帶寬和通信能力的需求相對較低,因此 RTX 4090 能夠提供足夠的計算能力,同時降低成本。
四通集團的G5208服務器是8卡風扇RTX 4090智算服務器開創者,旨在彌補消費級和專業級 GPU 之間的空白。它結合了高帶寬內存和先進的通信技術,同時保持較高的性價比,適用于大模型推理的需求。

G5208具有卓越性能、重塑架構、擴展性強和可靠性高等特點,可應用于深度學習模型訓練、深度學習推理、高性能計算、數據分析等多種應用場景,易于管理和部署。

接力式散熱設計
G5208采用前、中、后三段接力式散熱設計,確保了服務器內部組件在持續高負荷工作下依然保持理想的溫度狀態。這種出色的散熱設計帶來了以下顯著優點:
1.維持性能穩定
當服務器內部組件過熱時,它們的性能會受到影響,可能導致服務器響應速度變慢,甚至出現故障。有效的散熱設計可以確保這些組件在適宜的溫度下運行,從而維持服務器性能的穩定。
2.提升系統可靠性
散熱不良常常導致服務器頻繁出現故障,不僅影響業務正常運行,還可能帶來額外的維護成本。G5208采用這種高效的散熱設計,服務器故障率將大大降低,從而提高服務器的可靠性。
3.延長硬件使用壽命
過熱不僅影響性能,更是硬件損壞的主要元兇。通過優化散熱設計,服務器內部溫度得到有效控制,大大降低了硬件過熱的風險,從而顯著延長服務器使用壽命。
CPU-GPU直通拓撲 高效低延時
G5208采用CPU-GPU直通架構,1:4 GPU卡之間數據交換效率高于PCIE Switch架構,使得數據延時更低,實現了數據在處理器和圖形處理器之間的直接傳輸,大大降低了數據延時。與傳統的跨PCIE Switch架構相比,G5208提高了20%以上的數據傳輸效率,讓應用程序響應更迅速,性能更出眾。
卡完美兼容RTX4090 GPU卡
G5208強大的兼容性,使得RTX4090顯卡無需任何額外改動,即可以最佳狀態穩定運行。以消除作坊式改卡帶來的質量風險,讓每一張RTX4090顯卡保持原廠的純正品質,讓用戶享受原廠的質保服務。

高度定制化的服務器功能
G5208 AI智算服務器提供了一系列高度定制化的功能,確保滿足各類用戶和應用場景的獨特需求。
硬件配置的多樣性
G5208采用Intel和AMD兩大主流平臺,為用戶帶來豐富的硬件配置選項。用戶可以根據實際需求,靈活選擇處理器、內存、硬盤以及網卡等核心組件,確保服務器性能完美匹配應用需求。
卓越的擴展性
豐富的擴展槽位和接口為用戶提供了極大的便利,無論是內存、硬盤的擴容,還是其他硬件設備的升級,都能輕松實現,無需更換整臺服務器。
定制化服務
STONETEK堅持以客戶為中心,提供個性化的定制化服務。無論是硬件配置、操作系統選擇,還是軟件安裝,都可根據客戶的具體需求進行精準定制。

AI智算服務器G5208 為模型訓練、推理等任務提供強大的計算能力,輕松應對人工智能應用中的大量數據處理需求。G5208不僅滿足了不斷增長的算力需求,還為用戶帶來更加高效、智能的使用體驗。一經上市,便贏得了市場的廣泛認可。
關注我們,四通集團官網:https://www.ht-tek.com/








 京公網安備 11010502049343號
京公網安備 11010502049343號