


這些年來
圍繞私有云與公有云的辯論
“成本”二字是繞也繞不開的話題
直到越來越多的研究表明
公有云并不比本地便宜
有時(shí)甚至可能更貴
這個(gè)爭(zhēng)論才逐漸平息
但對(duì)于特殊的
深度學(xué)習(xí)應(yīng)用呢
跑在公有云是否會(huì)比本地便宜?
云是托管AI開發(fā)和生產(chǎn)的最經(jīng)濟(jì)方式嗎?Moor Insights&Strategy高級(jí)分析師Karl Freund認(rèn)為,最好的方案取決于你在AI旅程中的位置、你將如何密集地建立你的AI能力,以及期望實(shí)現(xiàn)的成果。
為何云對(duì)AI有如此吸引力?
云服務(wù)提供商(CSP)擁有廣泛的開發(fā)工具組合和預(yù)訓(xùn)練的深度神經(jīng)網(wǎng)絡(luò),用于語音、文本、圖像和翻譯處理。例如,微軟Azure提供了大量個(gè)預(yù)訓(xùn)練的網(wǎng)絡(luò)和工具,可以被你的云托管應(yīng)用程序作為API訪問。
許多模型甚至可以用用戶自己的數(shù)據(jù)進(jìn)行定制,如特定的詞匯或圖像。谷歌也有一連串相當(dāng)驚人的工具。比如它的AutoML可以自動(dòng)構(gòu)建深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò),在某些情況下可以節(jié)省大量時(shí)間。

所有這些工具都有幾個(gè)共同點(diǎn)。首先,它們使構(gòu)建AI應(yīng)用看起來非常容易。由于大多數(shù)公司都在努力為AI項(xiàng)目配備員工,因此這一點(diǎn)非常有吸引力。
其次,它們提供易用性,承諾在一個(gè)充滿相對(duì)晦澀難懂的技術(shù)的領(lǐng)域中點(diǎn)擊即可使用。但是,所有這些服務(wù)都有一個(gè)陷阱——他們要求你在他們的云中開發(fā)應(yīng)用程序,并在他們的云中運(yùn)行。
因此,這些服務(wù)具有極大的“綁定”特性。如果你使用微軟的預(yù)訓(xùn)練的DNN進(jìn)行圖像處理,你不能輕易在自己的服務(wù)器上運(yùn)行所產(chǎn)生的應(yīng)用程序。你可能永遠(yuǎn)不會(huì)在非谷歌的數(shù)據(jù)中心看到谷歌的TPU,也無法使用谷歌的AutoML工具。

“綁定”本身并不一定是件壞事。但這里有一個(gè)問題:很多AI開發(fā),特別是訓(xùn)練深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò),最終需要大量的計(jì)算。此外,你不會(huì)停止訓(xùn)練一個(gè)(有用的)網(wǎng)絡(luò),你需要用新的數(shù)據(jù)和功能來不斷保持它的“新鮮度”。
我所看到的公開研究表明,這種水平的計(jì)算在云中可能變得相當(dāng)昂貴,成本是建立自己的私有云來訓(xùn)練和運(yùn)行神經(jīng)網(wǎng)絡(luò)的2-3倍。
因此,對(duì)于小型,未知或可變的計(jì)算要求,云計(jì)算是有意義的,但是對(duì)于連續(xù)的、大規(guī)模深度學(xué)習(xí)而言,使用本地基礎(chǔ)設(shè)施可節(jié)省大量成本。而且除了成本因素以外,還有更多原因需要使用自我托管。
01部署
啟動(dòng)一個(gè)AI項(xiàng)目可能需要大量的時(shí)間、精力和費(fèi)用。云AI服務(wù)可以大大減少開始時(shí)的痛苦,不過一些硬件供應(yīng)商也在提供硬件和軟件的捆綁,力求AI的部署變得簡(jiǎn)單。

*例如,戴爾科技針對(duì)深度和機(jī)器學(xué)習(xí)推出了 "AI就緒型解決方案",其配備的完整GPU和集成軟件棧,專為降低部署AI門檻而設(shè)計(jì)。
02數(shù)據(jù)安全
一些行業(yè)受到嚴(yán)格的監(jiān)管,需要內(nèi)部的基礎(chǔ)設(shè)施。如金融行業(yè),則認(rèn)為將敏感信息放入云中風(fēng)險(xiǎn)太大。
03數(shù)據(jù)引力
這是對(duì)一些企業(yè)最重要的因素。簡(jiǎn)單說,如果你的重要數(shù)據(jù)在云中,你應(yīng)該建立你的AI,并把你的應(yīng)用程序也放在那里。但如果你的重要數(shù)據(jù)放在企業(yè)內(nèi)部,數(shù)據(jù)傳輸?shù)穆闊┖统杀究赡苁欠敝氐模貏e是考慮到神經(jīng)網(wǎng)絡(luò)訓(xùn)練數(shù)據(jù)集的巨大規(guī)模。因此,在內(nèi)部建立你的人工智能也是有意義的。

結(jié) 論
在哪里訓(xùn)練和運(yùn)行AI是一個(gè)深思熟慮的決定。這里的問題是,通常在你的開發(fā)道路上走得很遠(yuǎn),才能確定所需基礎(chǔ)設(shè)施的大小(服務(wù)器的數(shù)量、GPU的數(shù)量、存儲(chǔ)的類型等)。
一個(gè)常見的選擇是在公有云中開始你的模型實(shí)驗(yàn)和早期開發(fā),并制定一個(gè)帶有預(yù)定義的退出計(jì)劃,告訴你是否以及何時(shí)應(yīng)該把工作搬回家。這包括了解CSP的機(jī)器學(xué)習(xí)服務(wù)的好處,以及如果你決定把所有東西都搬到自己的硬件上,你將如何取代它們。

省時(shí)省力還省心
從選好一個(gè)硬件供應(yīng)商開始
AI正在革新我們的未來,而現(xiàn)在才剛剛起步。如同Karl Freund所認(rèn)為的:本地AI基礎(chǔ)設(shè)施可以比公有云更具經(jīng)濟(jì)效益。如果您計(jì)劃在AI領(lǐng)域進(jìn)行大量投資,一個(gè)好的硬件供應(yīng)商(比如戴爾科技集團(tuán))不僅可以切合您的需要,其中一些服務(wù)更可以相當(dāng)實(shí)惠。
憑借豐富的IT硬件組合,以及廣泛的合作伙伴生態(tài)系統(tǒng),戴爾科技正協(xié)助客戶簡(jiǎn)化并積極推動(dòng)數(shù)據(jù)科學(xué)及AI項(xiàng)目,無論是機(jī)器學(xué)習(xí)項(xiàng)目還是深度學(xué)習(xí)項(xiàng)目,涵蓋的部署范圍包括IoT網(wǎng)關(guān)、工作站、服務(wù)器、存儲(chǔ)、AI就緒解決方案和HPC等。
用于機(jī)器學(xué)習(xí)的硬件
針對(duì)機(jī)器學(xué)習(xí)項(xiàng)目,戴爾易安信PowerEdge R750或R740xd是理想的平臺(tái)。這些通用的2U服務(wù)器支持加速器和大容量存儲(chǔ),為后續(xù)的深度學(xué)習(xí)項(xiàng)目提供了未來的保障,其中xd版本還支持額外的存儲(chǔ)容量。AI就緒型解決方案
戴爾科技提供預(yù)配置的AI就緒解決方案,可簡(jiǎn)化配置過程,降低成本,并加快部署分布式多節(jié)點(diǎn)機(jī)器學(xué)習(xí)和深度學(xué)習(xí)集群。這些集成系統(tǒng)對(duì)硬件、軟件和服務(wù)進(jìn)行了優(yōu)化,有助于AI工作人員快速投入到生產(chǎn)并產(chǎn)生結(jié)果。用于AI的存儲(chǔ)
存儲(chǔ)性能對(duì)于機(jī)器學(xué)習(xí)項(xiàng)目的性能平衡至關(guān)重要,戴爾科技提供廣泛的全閃存和混合存儲(chǔ)產(chǎn)品組合,可以滿足AI的苛刻要求,這包括戴爾易安信PowerScale和ECS的存儲(chǔ)以及采用NFS和Lustre的分布式存儲(chǔ)解決方案。

此外,還有當(dāng)下熱門的戴爾科技最新AI服務(wù)器——PowerEdge XE8545。其搭載的最新AMD米蘭CPU、第三代NVlink - SMX4以及NVIDIA A100 40/80GB GPU,無不顯示出這是成為尖端機(jī)器學(xué)習(xí)模型,復(fù)雜的高性能計(jì)算(HPC)和GPU虛擬化的理想選擇。
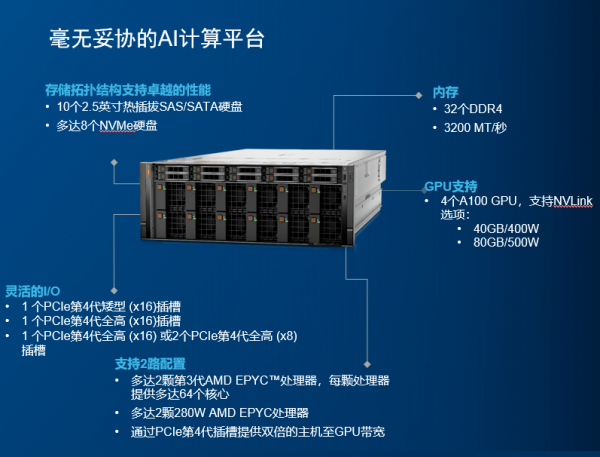
下面來看這款服務(wù)器的強(qiáng)大之處
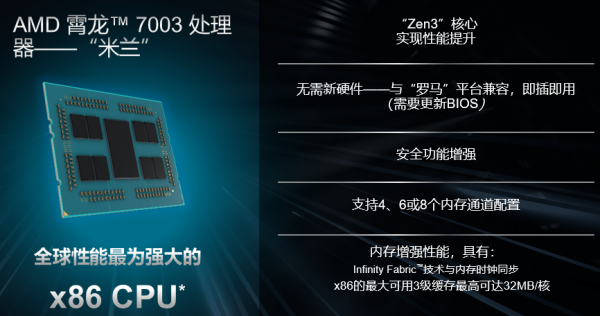
1AMD米蘭CPU
XE8545配備了2顆地表最強(qiáng)的7nm Zen3架構(gòu)的AMD第三代EPYC處理器。霄龍?zhí)幚砥饕宦纷邅恚米约旱膶?shí)力在服務(wù)器處理器市場(chǎng)牢牢的站穩(wěn)了腳,高性價(jià)吸引了不少用戶的目光。
2第三代NVLink-SXM4
XE8545 GPU內(nèi)部采用NVIDIA第三代NVLink互聯(lián)。其技術(shù)可提供更高帶寬和更多鏈路,并可提升多GPU系統(tǒng)配置的可擴(kuò)展性,故而可以解決互聯(lián)問題。
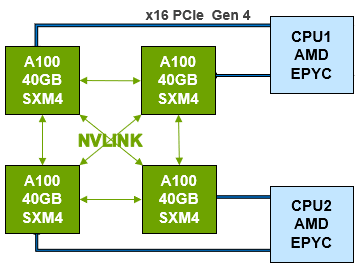
單個(gè)NVIDIA A100 Tensor核心GPU支持多達(dá)12個(gè)第三代NVLink 連接,總帶寬為每秒600 千兆字節(jié)(GB/秒),幾乎是PCIe Gen 4帶寬的10倍。

NVIDIA DGX™ A100等服務(wù)器可利用這項(xiàng)技術(shù)來提高可擴(kuò)展性,進(jìn)而實(shí)現(xiàn)非常快速的深度學(xué)習(xí)訓(xùn)練。NVLink也可用于 PCIe版A100的雙GPU配置。
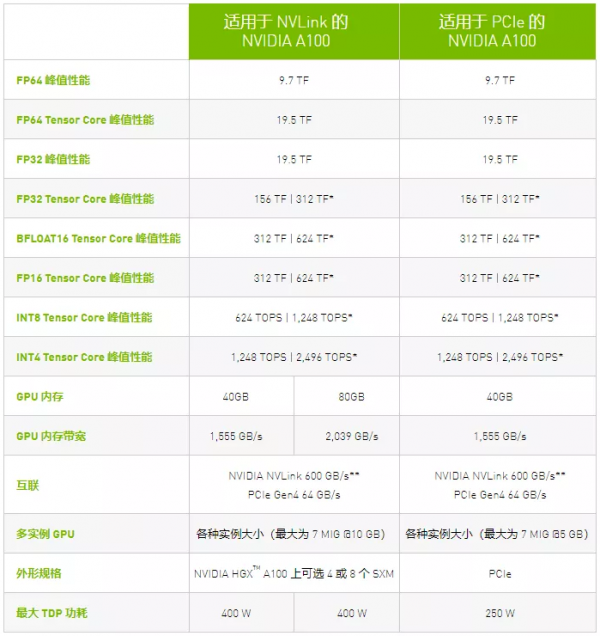
▲點(diǎn)擊查看清晰圖片
我們可以看出第三代NVLink的帶寬幾乎是PCIe Gen4的10倍,用第三代NVLink互聯(lián)的A100在能夠達(dá)到的最大功耗和顯存上也遠(yuǎn)遠(yuǎn)高于PCIe Gen4互聯(lián)的A100,是真正的靈活型性能怪獸。
3NVIDIA A100 40/80GB GPU
XE8545內(nèi)部支持多達(dá)四個(gè)A100 GPU,性能極其強(qiáng)大。
A100引入了突破性的功能來優(yōu)化推理工作負(fù)載。它能在從FP32到INT4的整個(gè)精度范圍內(nèi)進(jìn)行加速。多實(shí)例GPU (MIG)技術(shù)允許多個(gè)網(wǎng)絡(luò)同時(shí)基于單個(gè)A100運(yùn)行,從而優(yōu)化計(jì)算資源的利用率。在A100其他推理性能增益的基礎(chǔ)之上,僅結(jié)構(gòu)化稀疏支持一項(xiàng)就能帶來高達(dá)兩倍的性能提升。
在BERT等先進(jìn)的對(duì)話式AI模型上,A100可將推理吞吐量提升到高達(dá)CPU的249倍。
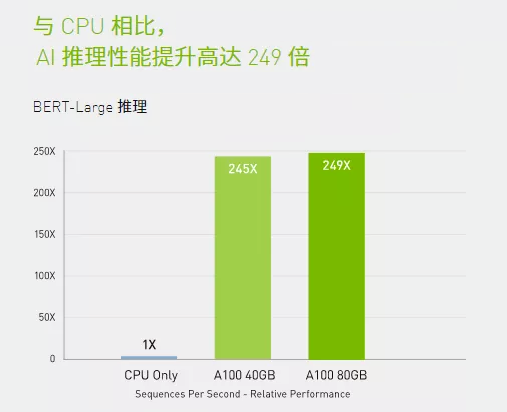
在受到批量大小限制的極復(fù)雜模型(例如用于先進(jìn)自動(dòng)語音識(shí)別用途的RNN-T)上,顯存容量有所增加的A100 80GB能使每個(gè)MIG的大小增加一倍(達(dá)到10GB),并提供比A100 40GB高1.2倍的吞吐量。
NVIDIA產(chǎn)品的出色性能在MLPerf推理測(cè)試中得到驗(yàn)證。A100再將性能提升了20倍,進(jìn)一步擴(kuò)大了這種性能優(yōu)勢(shì)。
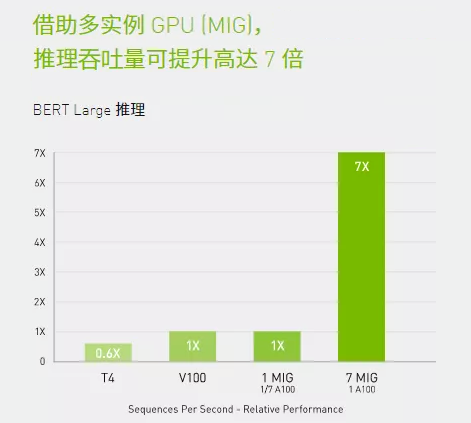
A100結(jié)合MIG技術(shù)可以更大限度地提高GPU加速的基礎(chǔ)設(shè)施的利用率。借助MIG,A100 GPU可劃分為多達(dá)7個(gè)獨(dú)立實(shí)例,讓多個(gè)用戶都能使用GPU加速功能。使用A100 40GB GPU,每個(gè)MIG實(shí)例最多可以分配5GB,而隨著A100 80GB增加的GPU內(nèi)存容量,每個(gè)實(shí)例將增加一倍達(dá)到10GB。
除了強(qiáng)大的XE8545服務(wù)器外,戴爾科技還有全系列的AMD服務(wù)器供您選擇。更詳細(xì)的產(chǎn)品,歡迎聯(lián)系戴爾官方企采網(wǎng)采購(gòu)專線400-884-6610,或者聯(lián)系您的客戶經(jīng)理。

尊敬的讀者
勞動(dòng)節(jié)福利火熱派送中
4月24日-5月14日
超炫新品0元試用
到手無需歸還
快來掃描下方二維碼
或點(diǎn)擊文末閱讀原文
速速參與活動(dòng)

相關(guān)內(nèi)容推薦:AI成為人,需要這一塊"肋骨"|戴爾科技為全球用戶提供幫助






習(xí),跑在公有云還是本地更劃算?")

 京公網(wǎng)安備 11010502049343號(hào)
京公網(wǎng)安備 11010502049343號(hào)